* Fix unexpected `UnrequestedBlobId` and `ExtraBlocksReturned` errors due to race conditions.
* Continue chain segment processing and skip any blocks that are already known, rather than returning an error.
* more de-dup checking
* ensure we don't reset `requested_ids` during rpc download
* better fix
* Merge branch 'unstable' of https://github.com/sigp/lighthouse into more-dup-lookup-fixes
* remove chain hash check
* Merge branch 'fix-block-lookup-race' of https://github.com/jimmygchen/lighthouse into sean-test-lookups
* remove block check
* add back tests
* Log and CI fixes
* undue extra check
* Merge branch 'sean-test-lookups' of https://github.com/realbigsean/lighthouse into sean-test-lookups
* log improvements
* Improve logging
* move gossipsub into a separate crate
* Merge branch 'unstable' of github.com:sigp/lighthouse into separate-gossipsub
* address review 2
* clippy beta
* update logging to log gossipsub logs
* Verify whether validators really are unknown during sync committee duty API request
* Merge branch 'unstable' into fix-4717
* Merge branch 'unstable' into fix-4717
* Merge branch 'unstable' of https://github.com/sigp/lighthouse into fix-4717
* Fix geth processes not being killed when stopping a local testnet
* Merge branch 'unstable' of https://github.com/sigp/lighthouse into fix_stop_testnet
* reduce scope of commitment
* avoid clone for last reference
* Merge branch 'unstable' of https://github.com/sigp/lighthouse into mod_merge_single_blob
* upgrade parent lookup result processing logs to debug, use display instead of debug for BlockError in case a blob parent unknown error is hit, add block root to BlockIsAlreadyKnown
* fix compile
* fix compile
* fix compile
* Set the peers_per_client metrics directly, rather than using increment/decrement
* Move PEERS_CONNECTED related update to the same place
* Move PEERS_CONNECTED_MULTI related update to the same place
* Rename
* Remove unused variables
* fix lib.rs and tests.rs
* update decode.rs
* auto-delete in Cargo.lock
* delete milagro in cargo.toml
* remove milagro from makefile
* remove milagro from the name
* delete milagro in comment
* delete milagro in cargo.toml
* delete in /testing/ef_tests/cargo.toml
* delete milagro in the logical OR
* delete milagro in /lighthouse/src/main.rs
* delete milagro in /crypto/bls/tests/tests.rs
* delete milagro in comment
* delete milagro in /testing//ef_test/src//cases/bls_eth_aggregate_pubkeys.rs
* delete milagro
* delete more in lib.rs
* delete more in lib.rs
* delete more in lib.rs
* delete milagro in /crypto/bls/src/lib.rs
* delete milagro in crypto/bls/src/mod.rs
* delete milagro.rs
* Fix duties override bug in VC
* Use initial request efficiently
* Prevent expired subscriptions by construction
* Clean up selection proof logic
* Add test
* remove exit-future usage,
as it is non maintained, and replace with async-channel which is already in the repo.
* Merge branch 'unstable' of https://github.com/sigp/lighthouse into remove-exit-future
* Merge branch 'unstable' of https://github.com/sigp/lighthouse into remove-exit-future
* Deactivate RPC Connection Handler
after goodbye message is sent
* nit: use to_string instead of format
* Merge branch 'unstable' of https://github.com/sigp/lighthouse into rpc-shutdown-improvement
* clippy
* Fix cargo.lock
* Merge latest unstable
* MVP implementation (untested)
* update store checkpoint sync test
* update cli help
* Merge pull request #5253 from realbigsean/checkpoint-blobs-sean
Checkpoint blobs sean
* Warn only if blobs are missing from server
* Merge remote-tracking branch 'origin/unstable' into checkpoint-blobs
* Verify checkpoint blobs
* Move blob verification earlier
* check the da cache and the attester cache in responding to RPC requests
* use the processing cache instead
* update comment
* add da cache metrics
* rename early attester cache method
* Merge branch 'unstable' of https://github.com/sigp/lighthouse into check-da-cache-in-rpc-response
* make rustup update run on the runners
* Revert "make rustup update run on the runners"
This reverts commit d097e9bfa8.
* improve libp2p connected peer metrics
* separate discv5 port from libp2p for NAT open
* use metric family for DISCOVERY_BYTES
* Merge branch 'unstable' of https://github.com/sigp/lighthouse into improve-metrics
* Downgrade duplicate publish logs
* Maintain backwards compatiblity, deprecate flag
* The tests had to go, because there's no config to test against
* Update help_bn.md
* Lint fixes
* More fixes for beta compiler.
* Format fixes
* Move `#[allow(dead_code)]` to field level.
* Remove old comment.
* Update beacon_node/execution_layer/src/test_utils/mod.rs
Co-authored-by: João Oliveira <hello@jxs.pt>
* remove duplicate line
* Add jq in api-bn
* Update beaconstate size
* Add fields to web3signer API
* Link web3signer API
* Update /lighthouse/logs in table
* plural
* update slasher doc
* update FAQ
* Add link in validator section
* Add more info on state pruning
* Update database size
* Merge branch 'unstable' into book-update
* Revise Siren for vc to connect bn
* Merge branch 'book-update' of https://github.com/chong-he/lighthouse into book-update
* Corrections to siren faq
* Fix typos
* Update release date for 4.6.0
* Merge branch 'unstable' into book-update
* add new spec field to spec
* add spec changes
* fix bug and update expected subnets with validation from pyspec
* fix values and make test prettier (?)
* fix style
---------
Co-authored-by: Lion - dapplion <35266934+dapplion@users.noreply.github.com>
* Perform transaction
* Remove lighthouse/beacon/states/{state_id}/ssz
* Update database api example
* Update checkpoint sync
* minor update
* single beacon node
* add info in mev
* Merge remote-tracking branch 'origin/unstable' into testnet
* add builder_boost_factor example
* change to 50 for consistency
* Remove SSZ state root route
* Remove SSZ states route from client impl
* Patch tests
* Merge branch 'unstable' into 5063-delete-ssz-state-route
* Further remove dead code
* expose builder booster flags in vc, enable options in validator endpoints, update tests
* resolve failing test
* fix issues related to CreateConfig and MoveConfig
* remove unneeded val, change how boost factor flag logic in the vc, add some additional documentation
* fix typos
* fix typos
* assume builder-proosals flag if one of other two vc builder flags are present
* fmt
* typo
* typo
* Fix CLI help text
* Prioritise per validator builder boost configurations over CLI flags.
* Add http test for builder boost factor with process defaults.
* Fix issue with PATCH request
* Add prefer builder proposals
* Add more builder boost factor tests.
---------
Co-authored-by: Mac L <mjladson@pm.me>
Co-authored-by: Jimmy Chen <jchen.tc@gmail.com>
Co-authored-by: Paul Hauner <paul@paulhauner.com>
* add get blobs unit test
* Use a multi_key_query for blob_sidecar indices
* Fix test
* Remove env_logger
---------
Co-authored-by: realbigsean <seananderson33@GMAIL.com>
* store blobs in the correct db in backfill
* add database migration
* add migration file
* remove log info suggesting deneb isn't schedule
* add batching in blob migration
* add metrics layer
* add metrics
* simplify getting the target
* make clippy happy
* fix typos
* unify deps under workspace
* make import statement shorter, fix typos
* enable warn by default, mark flag as deprecated
* do not exit on error when initializing logging fails
* revert exit on error
* adjust bootnode logging
* add logging layer
* non blocking file writer
* non blocking file writer
* add tracing visitor
* use target as is by default
* make libp2p events register correctly
* adjust repilcated cli help
* refactor tracing layer
* linting
* filesize
* log gossipsub, dont filter by log level
* turn on debug logs by default, remove deprecation warning
* truncate file, add timestamp, add unit test
* suppress output (#5)
* use tracing appender
* cleanup
* Add a task to remove old log files and upgrade to warn level
* Add the time feature for tokio
* Udeps and fmt
---------
Co-authored-by: Diva M <divma@protonmail.com>
Co-authored-by: Divma <26765164+divagant-martian@users.noreply.github.com>
Co-authored-by: Age Manning <Age@AgeManning.com>
* add metrics layer
* add metrics
* simplify getting the target
* make clippy happy
* fix typos
* unify deps under workspace
* make import statement shorter, fix typos
* enable warn by default, mark flag as deprecated
* do not exit on error when initializing logging fails
* revert exit on error
* adjust bootnode logging
* use target as is by default
* make libp2p events register correctly
* adjust repilcated cli help
* turn on debug logs by default, remove deprecation warning
* suppress output (#5)
---------
Co-authored-by: Age Manning <Age@AgeManning.com>
* switch libp2p source to sigp fork
* Shift the connection closing inside RPC behaviour
* Tag specific commits
* Add slow peer scoring
* Fix test
* Use default yamux config
* Pin discv5 to our libp2p fork and cargo update
* Upgrade libp2p to enable yamux gains
* Add a comment specifying the branch being used
* cleanup build output from within container
(prevents CI warnings related to fs permissions)
* Remove revision tags add branches for testing, will revert back once we're happy
* Update to latest rust-libp2p version
* Pin forks
* Update cargo.lock
* Re-pin to panic-free rust
---------
Co-authored-by: Age Manning <Age@AgeManning.com>
Co-authored-by: Pawan Dhananjay <pawandhananjay@gmail.com>
Co-authored-by: antondlr <anton@delaruelle.net>
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
* Disallow Syncing From Genesis By Default
* Fix CLI Tests
* Perform checks in the `ClientBuilder`
* Tidy, fix tests
* Return an error based on the Deneb fork
* Fix typos
* Fix failing test
* Add missing CLI flag
* Fix CLI flags
* Add suggestion from Sean
* Fix conflict with blob sidecars epochs
---------
Co-authored-by: Mark Mackey <mark@sigmaprime.io>
* add runtime variable list type
* add configs to ChainSpec
* git rid of max request blocks type
* fix tests and lints
* remove todos
* git rid of old const usage
* fix decode impl
* add new config to `Config` api struct
* add docs fix compilt
* move methods for per-fork-spec to chainspec
* get values off chain spec
* fix compile
* remove min by root size
* add tests for runtime var list
---------
Co-authored-by: Jimmy Chen <jchen.tc@gmail.com>
* Initial attempt to upgrade hashbrown to latest to get rid of the crate warnings.
* Replace `.expect()` usage with use of `const`.
* Update ahash 0.7 as well
* Remove unsafe code.
* Update `lru` to 0.12 and fix release test errors.
* Set non-blocking socket
* Bump testcontainers to 0.15.
* Fix lint
---------
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
* Add mergify.yml.
* Abstract out CI jobs to a "success" job so that a change in the CI jobs don't require modification to mergify configuration on stable branch.
* Add new jobs to the `needs` list of `test-suite-success`.
* Set `batch_max_wait_time` to 60 s.
* update libp2p and address compiler errors
* remove bandwidth logging from transport
* use libp2p registry
* make clippy happy
* use rust 1.73
* correct rpc keep alive
* remove comments and obsolte code
* remove libp2p prefix
* make clippy happy
* use quic under facade
* remove fast msg id
* bubble up close statements
* fix wrong comment
* Add cli.sh file
* update bash script
* update Makefile
* update
* modified test-suite
* fix path
* Fix cli.sh permissions
* update cmd
* cli_manual
* Revise to update
* Update directory in Github
* Correct cli.txt directory
* test old cli_manual
* change exit 1
* Update cli and makefile
* Move cli.sh
* remove files
* fix permission
* Indentation and revision
* Fixed permission
* Create new cli folder
* remove dummy
* put a dummy file
* Revise cli.sh
* comment
* function
* remove vm.md
* test make cli
* test
* testing
* testing
* update
* update
* test
* test
* add vm
* change back non-debug mode
* add exist and update for future debug
* revise
* remove troubleshooting part
* update
* add summary.md
* test
* test
* Update Makefile
Co-authored-by: Mac L <mjladson@pm.me>
* Update Makefile
Co-authored-by: Mac L <mjladson@pm.me>
* Remove help-cli.md and rearrange
* Remove help-cli.md
* Update scripts/cli.sh
Co-authored-by: Mac L <mjladson@pm.me>
* Update scripts/cli.sh
Co-authored-by: Mac L <mjladson@pm.me>
* remove maxperf
* move then to same line as if
* Fix indent and echo file not found
* To be explicit in replacing the old file
* Add logging when there are changes
* Add local variables
* spacing
* remove cargo fmt
* update .md files
* Edit exit message to avoid confusion
* Remove am and add vm subcommands
* Add cargo-fmt
* Revise test-suite.yml
* Update SUMMARY.md
* Add set -e
* Add vm
* Fix
* Add vm
* set -e
* Remove return 1 and add :
* Small revision
* Fix typo
* Update scripts/cli.sh
Co-authored-by: Mac L <mjladson@pm.me>
* Indent
* Update scripts/cli.sh
Co-authored-by: Mac L <mjladson@pm.me>
* Remove .exe in Windows
* Fix period with \.
* test
* check diff
* linux commit
* Add cli.sh file
* update bash script
* update Makefile
* update
* modified test-suite
* fix path
* Fix cli.sh permissions
* update cmd
* cli_manual
* Revise to update
* Update directory in Github
* Correct cli.txt directory
* test old cli_manual
* change exit 1
* Update cli and makefile
* Move cli.sh
* remove files
* fix permission
* Indentation and revision
* Fixed permission
* Create new cli folder
* remove dummy
* put a dummy file
* Revise cli.sh
* comment
* function
* remove vm.md
* test make cli
* test
* testing
* testing
* update
* update
* test
* test
* add vm
* change back non-debug mode
* add exist and update for future debug
* revise
* remove troubleshooting part
* update
* add summary.md
* test
* test
* Update Makefile
Co-authored-by: Mac L <mjladson@pm.me>
* Update Makefile
Co-authored-by: Mac L <mjladson@pm.me>
* Remove help-cli.md and rearrange
* Remove help-cli.md
* Update scripts/cli.sh
Co-authored-by: Mac L <mjladson@pm.me>
* Update scripts/cli.sh
Co-authored-by: Mac L <mjladson@pm.me>
* remove maxperf
* move then to same line as if
* Fix indent and echo file not found
* To be explicit in replacing the old file
* Add logging when there are changes
* Add local variables
* spacing
* remove cargo fmt
* Edit exit message to avoid confusion
* update .md files
* Remove am and add vm subcommands
* Add cargo-fmt
* Revise test-suite.yml
* Update SUMMARY.md
* Add set -e
* Add vm
* Fix
* Add vm
* set -e
* Remove return 1 and add :
* Small revision
* Fix typo
* Update scripts/cli.sh
Co-authored-by: Mac L <mjladson@pm.me>
* Indent
* Update scripts/cli.sh
Co-authored-by: Mac L <mjladson@pm.me>
* Remove .exe in Windows
* Fix period with \.
* test
* check diff
* Revert "Merge branch 'book-cli' of https://github.com/chong-he/lighthouse into book-cli"
This reverts commit 314005d3f8, reversing
changes made to a007f61378.
* update
* update
* Remove echo diff
* Dockerize
* Remove `-ti`
* take ownership inside container
* fix mistake
* proper escaping, restore ownership afterwards
* try without taking ownership of repo
* update
* add diff for troubleshooting
* binary
* update using linux
* binary
* make file
* remove diff
* add diff
* update progressive balance help text
* Remove diff
---------
Co-authored-by: Mac L <mjladson@pm.me>
Co-authored-by: antondlr <anton@delaruelle.net>
* EIP-3076 interchange tests: Add `should_succeed_complete` boolean.
This new added `should_succeed_complete` boolean means the test should succeed using
complete anti-slashing DB, while the untouched `should_succeed` boolean is
still implicitely reserved for minimal anti-slashing DB.
Note:
This commit only adds the new `should_succeed_complete` boolean, and copy the value from
`should_succeed` without any meaning regarding the value this boolean should
take.
* `TestEIP3076SpecTests`: Modify two tests
Those two tests are modified in a way they both comply with minimal AND
complete anti-slashing DB.
* Disallow false positives and differentiate more minimal vs complete cases
* Fix my own typos
* Update to v5.3.0 tag
---------
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
* Changes to use required Endpoint
* Format
* fixed doppleganger service
* minor fix
* efficiency changes
* fixed tests
* remove commented line
---------
Co-authored-by: Jimmy Chen <jchen.tc@gmail.com>
* Track time to early attester cache
* Add debug log for early attester cache
* Add mock-el command to lcli
* Revert beacon chain changes
* Tidy, fix compilation errors
* Add required flag
* Default to SYNCING response
* Hide flag
* rebase and add comment
* conditional test
* test
* optimistic chould be working now
* finality should be working now
* try again
* try again
* clippy fix
* add lc bootstrap beacon api
* add lc optimistic/finality update to events
* fmt
* That error isn't occuring on my computer but I think this should fix it
* Add missing test file
* Update light client types to comply with Altair light client spec.
* Fix test compilation
* Support deserializing light client structures for the Bellatrix fork
* Move `get_light_client_bootstrap` logic to `BeaconChain`. `LightClientBootstrap` API to return `ForkVersionedResponse`.
* Misc fixes.
- log cleanup
- move http_api config mutation to `config::get_config` for consistency
- fix light client API responses
* Add light client bootstrap API test and fix existing ones.
* Fix test for `light-client-server` http api config.
* Appease clippy
* Efficiency improvement when retrieving beacon state.
---------
Co-authored-by: Jimmy Chen <jchen.tc@gmail.com>
* multiple broadcast flags
* rewrite with single --broadcast option
* satisfy cargo fmt
* shorten sync-committee-messages
* fix a doc comment and a test
* use strum
* Add broadcast test to simulator
* bring --disable-run-on-all flag back with deprecation notice
* Added in process_justification_and_finalization
Added in process_justification_and_finalization to compute_attestation_rewards_altair to take into account justified attestations when coming out of inactivity leak. Also added in test to check for this edge case.
* Added in justification and finalization for compute_attestation_rewards_base
* Added in test for altair rewards without inactivity leak
* Delete BN spec flag and VC beacon-node flag
* Remove warn
* slog
* add warn
* delete eth1-endpoint
* delete server from vc cli.rs
* delete server flag in config.rs
* delete delete-lockfiles in vc
* delete allow-unsynced flag in VC
* delete strict-fee-recipient in VC and warn log
* delete merge flag in bn (hidden)
* delete count-unrealized and count-unrealized-full in bn (hidden)
* delete http-disable-legacy-spec in bn (hidden)
* delete eth1-endpoint in lcli
* delete warn message lcli
* delete eth1-endpoints
* delete minify in slashing protection
* delete minify related
* Remove mut
* add back warn! log
* Indentation
* Delete count-unrealized
* Delete eth1-endpoints
* Delete eth1-endpoint test
* delete eth1-endpints test
* delete allow-unsynced test
* Add back lcli eth1-endpoint
---------
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
## Issue Addressed
-downgrades `Missing components over rpc` to debug because this isn't unusual and just results in a re-try
-removes the result from `Block component processed for lookup` because this prints the full block on an unknown parent error
Co-authored-by: realbigsean <seananderson33@gmail.com>
## Issue Addressed
The comment implies that observations for the given slot would be retained but they are not.
## Proposed Changes
I'm pretty sure the functionality is correct and the comment is slightly incorrect, so just update the comment. The comment needs to say something along the lines of "less than or equal to" rather than just "less than."
## Additional Info
It doesn't make sense to keep finalized observations since those are no longer accepted.
## Issue Addressed
Closes#4481.
(Continuation of #4648)
## Proposed Changes
- [x] Add `lighthouse db prune-states`
- [x] Make it work
- [x] Ensure block roots are handled correctly (to be addressed in 4735)
- [x] Check perf on mainnet/Goerli/Gnosis (takes a few seconds max)
- [x] Run block root healing logic (#4875 ) at the beginning
- [x] Add some tests
- [x] Update docs
- [x] Add `--freezer` flag and other improvements to `lighthouse db inspect`
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
Co-authored-by: Jimmy Chen <jimmy@sigmaprime.io>
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Issue Addressed
#4582
## Proposed Changes
Add a new v3 block fetching flow that can decide to return a Full OR Blinded payload
## Additional Info
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Issue Addressed
I observed our forward sync on devnet 9 would stall when we would hit this log:
```
250425:Oct 19 00:54:17.133 WARN Blocks and blobs request for range received invalid data, error: KzgCommitmentMismatch, batch_id: 4338, peer_id: 16Uiu2HAmHbmkEQFDrJfNuy1aYyAfHkNUwSD9FN7EVAqGJ8YTF9Mh, service: sync, module: network::sync::manager:1036
```
## Proposed Changes
`range_sync_block_and_blob_response` [here](1cb02a13a5/beacon_node/network/src/sync/manager.rs (L1013)) removes the request from the sync manager. later, however if there's an error, `inject_error` [here](1cb02a13a5/beacon_node/network/src/sync/manager.rs (L1055)) expects the request to exist so we can handle retry logic. So this PR just re-inserts the request (withthout any accumulated blobs or blocks) when we hit an error here.
The issue is unique to block+blob sync because the error here is only possible from mismatches between blocks + blobs after we've downloaded both, there's no equivalent error in block sync
Co-authored-by: realbigsean <seananderson33@gmail.com>
## Issue Addressed
Closes#4817.
## Proposed Changes
- Fill in the linear block roots array between 0 and the slot of the first block (e.g. slots 0 and 1 on Holesky).
- Backport the `--freezer`, `--skip` and `--limit` options for `lighthouse db inspect` from tree-states. This allows us to easily view the database corruption of 4817 using `lighthouse db inspect --network holesky --freezer --column bbr --output values --limit 2`.
- Backport the `iter_column_from` change and `MemoryStore` overhaul from tree-states. These are required to enable `lighthouse db inspect`.
- Rework `freezer_upper_limit` to allow state lookups for slots below the `state_lower_limit`. Currently state lookups will fail until state reconstruction completes entirely.
There is a new regression test for the main bug, but no test for the `freezer_upper_limit` fix because we don't currently support running state reconstruction partially (see #3026). This will be fixed once we merge `tree-states`! In lieu of an automated test, I've tested manually on a Holesky node while it was reconstructing.
## Additional Info
Users who backfilled Holesky to slot 0 (e.g. using `--reconstruct-historic-states`) need to either:
- Re-sync from genesis.
- Re-sync using checkpoint sync and the changes from this PR.
Due to the recency of the Holesky genesis, writing a custom pass to fix up broken databases (which would require its own thorough testing) was deemed unnecessary. This is the primary reason for this PR being marked `backwards-incompat`.
This will create few conflicts with Deneb, which I've already resolved on `tree-states-deneb` and will be happy to backport to Deneb once this PR is merged to unstable.
Align the document with the [implementation](2841f60686/beacon_node/execution_layer/src/lib.rs (L740)) regarding the `--builder` flag.
The `tokio::join!` macro takes a list of async expressions and evaluates them concurrently on the same task.
1. Add commitments to logs and update the `Display` implementation of `KzgCommitment` to become truncated similarly to block root.
I've been finding it difficult to debug scenarios involving multiple blobs for the same `(index, block_root)`. Logging the commitment will help with this, we can match it to what exists in the block.
Example output:
```
Oct 20 21:13:36.700 DEBG Successfully verified gossip blob commitment: 0xa3c1…1cd8, index: 0, root: 0xf31e…f9de, slot: 154568
Oct 20 21:13:36.785 DEBG Successfully verified gossip block commitments: [0xa3c1…1cd8, 0x8655…02ff, 0x8d6a…955a, 0x84ac…3a1b, 0x9752…629b, 0xb9fc…20fb], root: 0xf31eeb732702e429e89057b15e1c0c631e8452e09e03cb1924353f536ef4f9de, slot: 154568, graffiti: teku/besu, service: beacon
```
Example output in a block with no blobs (this will show up pre-deneb):
```
426734:Oct 20 21:15:24.113 DEBG Successfully verified gossip block, commitments: [], root: 0x619db1360ba0e8d44ae2a0f2450ebca47e167191feecffcfac0e8d7b6c39623c, slot: 154577, graffiti: teku/nethermind, service: beacon, module: beacon_chain::beacon_chain:2765
```
2. Remove `strum::IntoStaticStr` from `AvailabilityCheckError`. This is because `IntoStaticStr` end up dropping information inside the enum. So kzg commitments in this error are dropped, making it more difficult to debug
```
AvailabilityCheckError::KzgCommitmentMismatch {
blob_commitment: KzgCommitment,
block_commitment: KzgCommitment,
},
```
which is output as just `AvailabilityCheckError`
3. Some additional misc sync logs I found useful in debugging https://github.com/sigp/lighthouse/pull/4869
4. This downgrades ”Block returned for single block lookup not present” to debug because I don’t think we can fix the scenario that causes this unless we can cancel inflight rpc requests
Co-authored-by: realbigsean <seananderson33@gmail.com>
## Issue Addressed
Fixes#4697.
This also unblocks the state pruning PR (#4835). Because self healing breaks if state pruning is applied to a database with missing block roots.
## Proposed Changes
- Fill in the missing block roots between last restore point slot and split slot when upgrading to latest database version.
## Issue Addressed
Makes lighthouse compliant with new kzg changes in https://github.com/ethereum/consensus-specs/releases/tag/v1.4.0-beta.3
## Proposed Changes
1. Adds new official trusted setup
2. Refactors kzg to match upstream changes in https://github.com/ethereum/c-kzg-4844/pull/377
3. Updates pre-generated `BlobBundle` to work with official trusted setup. ~~Using json here instead of ssz to account for different value of `MaxBlobCommitmentsPerBlock` in minimal and mainnet. By using json, we can just use one pre generated bundle for both minimal and mainnet. Size of 2 separate ssz bundles is approximately equal to one json bundle cc @jimmygchen~~
Dunno what I was doing, ssz works without any issues
4. Stores trusted_setup as just bytes in eth2_network_config so that we don't have kzg dependency in that lib and in lcli.
Co-authored-by: realbigsean <seananderson33@gmail.com>
Co-authored-by: realbigsean <seananderson33@GMAIL.com>
## Issue Addressed
N/A
## Proposed Changes
Sends blocks and blobs from http_api to the network channel for publishing in a single network channel send. This is to avoid overhead of multiple calls.
Also adds a metric for rpc blob retrieval duration.
## Issue Addressed
Addresses the recent CI failures caused by caching `blst` for the wrong CPU type.
## Proposed Changes
- Use `FEATURES: jemalloc,portable` when building Lighthouse & `lcli` in tests
- Add a new `TEST_FEATURES` and set to `portable` for all CI test jobs.
- Updated Makefiles to read the `TEST_FEATURES` environment variable, and default to none.
## Issue Addressed
We run `clippy` as part of our CI, so it would help new devs if we add the `make lint` command to the dev setup section in the Lighthouse book.
## Issue Addressed
#4512
Which issue # does this PR address?
## Proposed Changes
Add inactivity calculation for Altair
Please list or describe the changes introduced by this PR.
Add inactivity calculation for Altair
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
Co-authored-by: Jimmy Chen <jchen.tc@gmail.com>
## Issue Addressed
updates libp2p to the latest version and uses the new `SwarmBuilder`. Superseeds https://github.com/sigp/lighthouse/pull/4695/
CC @mxinden I don't think we can use both `bandwidth_loggers` with the new syntax right?
## Issue Addressed
Fix a bug in `lcli skip-slots` that resulted in it always writing the pre-state to the output file.
## Proposed Changes
Correctly keep track of the post-state, and write it.
## Issue Addressed
#4827
## Proposed Changes
This PR introduces a new build-arg to the Lighthouse Dockerfile: `CARGO_USE_GIT_CLI`. This arg will be passed into the `CARGO_NET_GIT_FETCH_WITH_CLI` [environment variable](https://doc.rust-lang.org/cargo/reference/config.html#netgit-fetch-with-cli), which instructs `cargo` to use the git CLI during `fetch` operations instead of the git library. Doing so works around [a bug](https://github.com/rust-lang/cargo/issues/10583) with the git library that causes it to go OOM during `fetch` operations on `arm64` platforms.
The default value is `false` so this doesn't affect Lighthouse builds or the CI pipeline. Running a build with `--build-arg CARGO_USE_GIT_CLI=true` will activate it, which is necessary to cross-compile the `arm64` binary when not using `cross` (i.e., when building via the Dockerfile instead of natively if you don't have a rust environment ready to go).
Special thanks to @michaelsproul for helping me repro the initial problem.
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Issue Addressed
Following the conversation on https://github.com/libp2p/rust-libp2p/pull/3666 the changes introduced in this PR will allow us to give more insights if the bandwidth limitations happen at the transport level, namely if quic helps vs yamux and it's [window size limitation](https://github.com/libp2p/rust-yamux/issues/162) or if the bottleneck is at the gossipsub level.
## Proposed Changes
introduce new quic and tcp bandwidth metric gauges.
cc @mxinden (turned out to be easier, Thomas gave me a hint)
* Fix block backfill with genesis skip slots
* Fix freezer upper limit
* Fix: write post state in lcli skip-slots (#4843)
* Added CARGO_USE_GIT_CLI to the Dockerfile (#4828)
* chore: replace deprecated hub with gh for releases (#4839)
* Put schema version back to 24 (ignore Deneb)
* Minimise diff
---------
Co-authored-by: Joe Clapis <jclapis@outlook.com>
Co-authored-by: Dustin Brickwood <dustinbrickwood204@gmail.com>
## Issue Addressed
Related to https://github.com/sigp/lighthouse/issues/4676.
Deneb-specifc CI code to be removed before merging to `unstable`. Dot not merge until we're ready to merge into `unstable`, as we may need to release deneb docker images before merging.
Keep in mind that most of the changes in the below PR (to `unstable`) have already
been merged to `deneb-free-blobs`, so merging `deneb-free-blobs` into `unstable` would include those changes - it would be ok if the release runners are ready, otherwise we may want to exclude them before merging.
- https://github.com/sigp/lighthouse/pull/4592
## Issue Addressed
Fix OOMs caused by too many concurrent tests. The runner machine is currently liable to run `32 * 5 = 160` tests in parallel. If each test uses say 300MB max, this is 48GB of RAM!
## Proposed Changes
Reduce the number of threads per runner job to 8. This should cap the memory at 4x lower than the current limit, i.e. around 12GB. If we continue to run out of RAM, we should consider more sophisticated limits.
## Issue Addressed
Fix a deadlock in the tests that was causing tests on tree-states to run for hours without finishing: https://github.com/sigp/lighthouse/actions/runs/6491194654/job/17628138360.
## Proposed Changes
Avoid using a Mutex under the Rayon `par_iter`. Instead, use an `AtomicUsize`. I've run the new version several times in a loop and it hasn't deadlocked (it was deadlocking consistently on tree-states).
## Additional Info
The same bug exists in unstable and tree-states, but I'm not sure why it was triggering so consistently on the tree-states branch.
## Proposed Changes
Add `compare_fields(as_iter)` as a field attribute to `compare_fields_derive`. This allows any iterable type to be compared in the same as a slice (by index).
This is forwards-compatible with tree-states types like `List` and `Vector` which can not be cast to slices.
## Issue Addressed
N/A
## Proposed Changes
I saw a false positive on the link-check CI run and while investigating I noticed that this link technically 404's but is not "dead" in the strict sense. I have updated it to the correct path.
## Proposed Changes
Fix the misplacement of the total block production time metric, which occurred during a previous refactor.
Total block production times are no longer skewed low (data from Holesky + blockdreamer):
```
# HELP beacon_block_production_seconds Full runtime of block production
# TYPE beacon_block_production_seconds histogram
beacon_block_production_seconds_bucket{le="0.005"} 0
beacon_block_production_seconds_bucket{le="0.01"} 0
beacon_block_production_seconds_bucket{le="0.025"} 0
beacon_block_production_seconds_bucket{le="0.05"} 0
beacon_block_production_seconds_bucket{le="0.1"} 0
beacon_block_production_seconds_bucket{le="0.25"} 0
beacon_block_production_seconds_bucket{le="0.5"} 37
beacon_block_production_seconds_bucket{le="1"} 65
beacon_block_production_seconds_bucket{le="2.5"} 66
beacon_block_production_seconds_bucket{le="5"} 66
beacon_block_production_seconds_bucket{le="10"} 66
beacon_block_production_seconds_bucket{le="+Inf"} 66
beacon_block_production_seconds_sum 34.225780452
beacon_block_production_seconds_count 66
```
## Additional Info
Cheers to @jimmygchen for helping spot this.
## Issue Addressed
Addresses #4778, and potentially fixes the flaky deneb builder test `builder_works_post_deneb`.
The [deneb builder test](c5c84f1213/beacon_node/http_api/tests/tests.rs (L5371)) has been quite flaky on our CI (`release-tests`) since it was introduced. I'm guessing that it might be timing out on the builder `get_header` call (1 second), and therefore the local payload is used, while the test expects builder payload to be used.
On my machine the [`get_header` ](c5c84f1213/beacon_node/execution_layer/src/test_utils/mock_builder.rs (L367)) call takes about 550ms, which could easily go over 1s on slower environments (our windows CI runner is much slower than the ubuntu one).
I did a profile on the test and it showed that `blob_to_kzg_commiment` and `compute_kzg_proof` was taking a large chunk of time, so perhaps pre-generating the blobs could help stablise this test.
## Proposed Changes
Pre-generate blobs bundle for Mainnet and Minimal presets.
Before the change `get_header` took about **550ms**, and it's now reduced to **50-55ms** after the change. If timeout was indeed the cause of the flaky test, this fix should stablise it. This also brings the flaky `builder_works_post_deneb` test time from 50s to 10s. (8s if we only use a single blob)
## Issue Addressed
CI is currently blocked by persistently failing integration tests.
## Proposed Changes
Use latest Nethermind release and apply the appropriate fixes as there have been breaking changes.
Also increase the timeout since I had some local timeouts.
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
Co-authored-by: antondlr <anton@delaruelle.net>
Co-authored-by: Jimmy Chen <jchen.tc@gmail.com>
* use workspace deps in kzg crate
* delete unused blobs dp path field
* full match on fork name in engine api get payload v3
* only accept v3 payloads on get payload v3 endpoint in mock el
* remove FIXMEs related to merge transition tests
* move static tx to test utils
* default max_per_epoch_activation_churn_limit to mainnet value
* remove unnecessary async
* remove comment
* use task executor in `blob_sidecars` endpoint
* Add `blob_sidecar` event to SSE.
* Return 202 if a block is published but failed blob validation when validation level is `Gossip`.
* Move `BlobSidecar` event to `process_gossip_blob` and add test.
* Emit `BlobSidecar` event when blobs are received over rpc.
* Improve test assertions on `SseBlobSidecar`s.
* Add quotes to blob index serialization in `SseBlobSidecar`
Co-authored-by: realbigsean <seananderson33@GMAIL.com>
---------
Co-authored-by: realbigsean <seananderson33@GMAIL.com>
* Initial Commit of State LRU Cache
* Build State Caches After Reconstruction
* Cleanup Duplicated Code in OverflowLRUCache Tests
* Added Test for State LRU Cache
* Prune Cache of Old States During Maintenance
* Address Michael's Comments
* Few More Comments
* Removed Unused impl
* Last touch up
* Fix Clippy
## Proposed Changes
Instead of sending every attestation subscription every slot to every BN:
- Send subscriptions 32, 16, 8, 7, 6, 5, 4, 3 slots before they occur.
- Track whether each subscription is sent successfully and retry it in subsequent slots if necessary.
## Additional Info
- [x] Add unit tests for `SubscriptionSlots`.
- [x] Test on Holesky.
- [x] Based on #4774 for testing.
## Issue Addressed
Partially #4788
## Proposed Changes
Remove documentation on `/lighthouse/database/reconstruct` API to avoid confusion as the calling the API during historical block download will show an error in the beacon log
Add Events API about `payload_attributes`
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
Co-authored-by: chonghe <44791194+chong-he@users.noreply.github.com>
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Issue Addressed
While reviewing #4801 I noticed that our use of `take_while` in the block replayer means that if a state root iterator _with gaps_ is provided, some additonal state roots will be dropped unnecessarily. In practice the impact is small, because once there's _one_ state root miss, the whole tree hash cache needs to be built anyway, and subsequent misses are less costly. However this was still a little inefficient, so I figured it's better to fix it.
## Proposed Changes
Use [`peeking_take_while`](https://docs.rs/itertools/latest/itertools/trait.Itertools.html#method.peeking_take_while) to avoid consuming the next element when checking whether it satisfies the slot predicate.
## Additional Info
There's a gist here that shows the basic dynamics in isolation: https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=40b623cc0febf9ed51705d476ab140c5. Changing the `peeking_take_while` to a `take_while` causes the assert to fail. Similarly I've added a new test `block_replayer_peeking_state_roots` which fails if the same change is applied inside `get_state_root`.
## Issue Addressed
Closes https://github.com/sigp/lighthouse/issues/4712
## Proposed Changes
Exit aggregation step early if no validator is aggregator. This avoids an unnecessary request to the beacon node and more importantly fixes noisy errors if Lighthouse VC is used with other clients such as Lodestar and Prysm.
## Additional Info
Related issue https://github.com/ChainSafe/lodestar/issues/5553
## Issue Addressed
- Close#4596
## Proposed Changes
- Add `Filter::recover` to handle rejections specifically as 404 NOT FOUND
Please list or describe the changes introduced by this PR.
## Additional Info
Similar to PR #3836
## Issue Addressed
This PR closes https://github.com/sigp/lighthouse/issues/3237
## Proposed Changes
Remove topic weight of old topics when the fork happens.
## Additional Info
- Divided `NetworkService::start()` into `NetworkService::build()` and `NetworkService::start()` for ease of testing.
## Issue Addressed
We've had a report of sync committee performance suffering with the beacon processor HTTP API prioritisations.
## Proposed Changes
Increase the priority of `/eth/v1/beacon/blocks/head/root` requests, which are used by the validator client to form sync committee messages, here:
441fc1691b/validator_client/src/sync_committee_service.rs (L181-L188)
Additionally, avoid loading the blinded block in all but the `block_id=block_root` case. I'm not sure why we were doing this previously, I suspect it was just an oversight during the implementation of the `finalized` status on API requests.
## Additional Info
I think this change should have minimal negative impact as:
- The block root endpoint is quick to compute (a few ms max).
- Only the priority of `head` requests is increased. Analytical processes that are making lots of block root requests for past slots are unable to DoS the beacon processor, as their requests will still be processed after attestations.
## Issue Addressed
N/A
## Proposed Changes
We were currently downscoring a peer for sending us a block that we already have in fork choice. This is unnecessary as we get duplicates in lighthouse only when
1. We published the block, so the block is already in fork choice
2. We imported the same block over rpc
In both scenarios, the peer who sent us the block over gossip is not at fault.
This isn't exploitable as valid duplicates will get dropped by the gossipsub duplicate filter
## Issue Addressed
Right now lighthouse accepts zero as enr ports. Since enr ports should be reachable, zero ports should be rejected here
## Proposed Changes
- update the config to use `NonZerou16` as an ENR port for all enr-related fields.
- the enr builder from config now sets the enr to the listening port only if the enr port is not already set (prev behaviour) and the listening port is not zero (new behaviour)
- reject zero listening ports when used with `enr-match`.
- boot node now rejects listening port as zero, since those are advertised.
- generate-bootnode-enr also rejected zero listening ports for the same reason.
- update local network scripts
## Additional Info
Unrelated, but why do we overwrite `enr-x-port` values with listening ports if `enr-match` is present? we prob should only do this for enr values that are not already set.
## Issue Addressed
https://github.com/sigp/lighthouse/issues/4543
## Proposed Changes
- Removes `NotBanned` from `BanResult`, implements `Display` and `std::error::Error` for `BanResult` and changes `ban_result` return type to `Option<BanResult>` which helps returning `BanResult` on `handle_established_inbound_connection`
- moves the check from for banned peers from `on_connection_established` to `handle_established_inbound_connection` to start addressing #4543.
- Removes `allow_block_list` as it's now redundant? Not sure about this one but if `PeerManager` keeps track of the banned peers, no need to send a `Swarm` event for `alow_block_list` to also keep that list right?
## Questions
- #4543 refers:
> More specifically, implement the connection limit behaviour inside the peer manager.
@AgeManning do you mean copying `libp2p::connection_limits::Behaviour`'s code into `PeerManager`/ having it as an inner `NetworkBehaviour` of `PeerManager`/other? If it's the first two, I think it probably makes more sense to have it as it is as it's less code to maintain.
> Also implement the banning of peers inside the behaviour, rather than passing messages back up to the swarm.
I tried to achieve this, but we still need to pass the `PeerManagerEvent::Banned` swarm event as `DiscV5` handles it's node and ip management internally and I did not find a method to query if a peer is banned. Is there anything else we can do from here?
3397612160/beacon_node/lighthouse_network/src/discovery/mod.rs (L931-L940)
Same as the question above, I did not find a way to check if `DiscV5` has the peer banned, so that we could check here and avoid sending `Swarm` events
3397612160/beacon_node/lighthouse_network/src/peer_manager/network_behaviour.rs (L168-L178)
Is there a chance we try to dial a peer that has been banned previously?
Thanks!
## Proposed Changes
- only use LH types to avoid build issues
- use warp instead of axum for the server to avoid importing the dep
## Additional Info
- wondering if we can move the `execution_layer/test_utils` to its own crate and import it as a dev dependency
- this would be made easier by separating out our engine API types into their own crate so we can use them in the test crate
- or maybe we can look into using reth types for the engine api if they are in their own crate
Co-authored-by: realbigsean <seananderson33@gmail.com>
* add processing and processed caching to the DA checker
* move processing cache out of critical cache
* get it compiling
* fix lints
* add docs to `AvailabilityView`
* some self review
* fix lints
* fix beacon chain tests
* cargo fmt
* make availability view easier to implement, start on testing
* move child component cache and finish test
* cargo fix
* cargo fix
* cargo fix
* fmt and lint
* make blob commitments not optional, rename some caches, add missing blobs struct
* Update beacon_node/beacon_chain/src/data_availability_checker/processing_cache.rs
Co-authored-by: ethDreamer <37123614+ethDreamer@users.noreply.github.com>
* marks review feedback and other general cleanup
* cargo fix
* improve availability view docs
* some renames
* some renames and docs
* fix should delay lookup logic
* get rid of some wrapper methods
* fix up single lookup changes
* add a couple docs
* add single blob merge method and improve process_... docs
* update some names
* lints
* fix merge
* remove blob indices from lookup creation log
* remove blob indices from lookup creation log
* delayed lookup logging improvement
* check fork choice before doing any blob processing
* remove unused dep
* Update beacon_node/beacon_chain/src/data_availability_checker/availability_view.rs
Co-authored-by: Michael Sproul <micsproul@gmail.com>
* Update beacon_node/beacon_chain/src/data_availability_checker/availability_view.rs
Co-authored-by: Michael Sproul <micsproul@gmail.com>
* Update beacon_node/beacon_chain/src/data_availability_checker/availability_view.rs
Co-authored-by: Michael Sproul <micsproul@gmail.com>
* Update beacon_node/beacon_chain/src/data_availability_checker/availability_view.rs
Co-authored-by: Michael Sproul <micsproul@gmail.com>
* Update beacon_node/network/src/sync/block_lookups/delayed_lookup.rs
Co-authored-by: Michael Sproul <micsproul@gmail.com>
* remove duplicate deps
* use gen range in random blobs geneartor
* rename processing cache fields
* require block root in rpc block construction and check block root consistency
* send peers as vec in single message
* spawn delayed lookup service from network beacon processor
* fix tests
---------
Co-authored-by: ethDreamer <37123614+ethDreamer@users.noreply.github.com>
Co-authored-by: Michael Sproul <micsproul@gmail.com>
Attempting to improve our CI speeds as its recently been a pain point.
Major changes:
- Use a github action to pull stable/nightly rust rather than building it each run
- Shift test suite to `nexttest` https://github.com/nextest-rs/nextest for CI
UPDATE:
So I've iterated on some changes, and although I think its still not optimal I think this is a good base to start from. Some extra things in this PR:
- Shifted where we pull rust from. We're now using this thing: https://github.com/moonrepo/setup-rust . It's got some interesting cache's built in, but was not seeing the gains that Jimmy managed to get. In either case tho, it can pull rust, cargofmt, clippy, cargo nexttest all in < 5s. So I think it's worthwhile.
- I've grouped a few of the check-like tests into a single test called `code-test`. Although we were using github runners in parallel which may be faster, it just seems wasteful. There were like 4-5 tests, where we would pull lighthouse, compile it, then run an action, like clippy, cargo-audit or fmt. I've grouped these into a single action, so we only compile lighthouse once, then in each step we run the checks. This avoids compiling lighthouse like 5 times.
- Ive made doppelganger tests run on our local machines to avoid pulling foundry, building and making lcli which are all now baked into the images.
- We have sccache and do not incremental compile lighthouse
Misc bonus things:
- Cargo update
- Fix web3 signer openssl keys which is required after a cargo update
- Use mock_instant in an LRU cache test to avoid non-deterministic test
- Remove race condition in building web3signer tests
There's still some things we could improve on. Such as downloading the EF tests every run and the web3-signer binary, but I've left these to be out of scope of this PR. I think the above are meaningful improvements.
Co-authored-by: Paul Hauner <paul@paulhauner.com>
Co-authored-by: realbigsean <seananderson33@gmail.com>
Co-authored-by: antondlr <anton@delaruelle.net>
## Issue Addressed
#4675
## Proposed Changes
- Update local ENR (**only port numbers**) with local addresses received from libp2p (via `SwarmEvent::NewListenAddr`)
- Only use the zero port for CLI tests
## Additional Info
### See Also ###
- #4705
- #4402
- #4745
* Start testing blob pruning
* Get rid of unnecessary orphaned blob column
* Make random blob tests deterministic
* Test for pruning being blocked by finality
* Fix bugs and test fork boundary
* A few more tweaks to pruning conditions
* Tweak oldest_blob_slot semantics
* Test margin pruning
* Clean up some terminology and lints
* Schema migrations for v18
* Remove FIXME
* Prune blobs on finalization not every slot
* Fix more bugs + tests
* Address review comments
## Issue Addressed
Synchronize dependencies and edition on the workspace `Cargo.toml`
## Proposed Changes
with https://github.com/rust-lang/cargo/issues/8415 merged it's now possible to synchronize details on the workspace `Cargo.toml` like the metadata and dependencies.
By only having dependencies that are shared between multiple crates aligned on the workspace `Cargo.toml` it's easier to not miss duplicate versions of the same dependency and therefore ease on the compile times.
## Additional Info
this PR also removes the no longer required direct dependency of the `serde_derive` crate.
should be reviewed after https://github.com/sigp/lighthouse/pull/4639 get's merged.
closes https://github.com/sigp/lighthouse/issues/4651
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Issue Addressed
#4635
## Proposed Changes
Wrap the `SignedVoluntaryExit` object in a `GenericResponse` container, adding an additional `data` layer, to ensure compliance with the key manager API specification.
The new response would look like this:
```json
{"data":{"message":{"epoch":"196868","validator_index":"505597"},"signature":"0xhexsig"}}
```
This is a backward incompatible change and will affect Siren as well.
## Issue Addressed
NA
## Proposed Changes
Bumps `quinn-proto` to address a QUIC-related vulnerability: https://rustsec.org/advisories/RUSTSEC-2023-0063
Fixes a `cargo audit` failure.
## Additional Info
NA
## Issue Addressed
Closes#4751
## Proposed Changes
Prevent `state_root_at_slot` and `block_root_at_slot` from erroring out due to a call to `self.slot()?` that fails before genesis. This fixes pre-genesis queries for:
- block at slot 0
- block by genesis block root
- state at slot 0
- state by genesis state root
- state at `finalized` tag
- state at `justified` tag
## Issue Addressed
#4531
## Proposed Changes
add SSZ support to the following block production endpoints:
GET /eth/v2/validator/blocks/{slot}
GET /eth/v1/validator/blinded_blocks/{slot}
## Additional Info
i updated a few existing tests to use ssz instead of writing completely new tests
## Issue Addressed
#4738
## Proposed Changes
See the above issue for details. Went with option #2 to use the async reqwest client in `Eth2NetworkConfig` and propagate the async-ness.
Fix local testnet to generate keys in the correct folders when `BN_COUNT` and `VC_COUNT` don't match.
The current script place the generated validator keys in validator folders based on the `BN_COUNT` config, e.g. `node_1/validators`, `node_2/validators`..etc. We should be using `VC_COUNT` here instead, otherwise the number of validator clients may not match the number of directories generated, and would result in either:
1. a VC not having any keys (when `BN_COUNT` < `VC_COUNT`)
2. a validator key directory not being used (when `BN_COUNT` > `VC_COUNT`).
There is an issue with the file `scripts/local_testnet/start_local_testnet.sh` - when we use a non-default `$SPEC-PRESET` in `vars.env` it runs into an error:
```
executing: ./setup.sh >> /home/ck/.lighthouse/local-testnet/testnet/setup.log
parse error: Invalid numeric literal at line 1, column 7
```
@jimmygchen found the issue and the updated script includes the flag `--spec $SPEC-PRESET`
## Proposed Changes
This PR adds more logging prior to genesis, particularly on networks that start with execution enabled.
There are new checks using `eth_getBlockByHash/Number` to verify that the genesis state's `latest_execution_payload_header` matches the execution node's genesis block.
The first commit also runs the merge-readiness/Capella-readiness checks prior to genesis. This has two effects:
- Give more information on the execution node's status and its readiness for genesis.
- Prevent the `el_offline` status from being set on `/eth/v1/node/syncing`, which previously caused the VC to complain loudly.
I would like to include this for the Holesky reboot. It would have caught the misconfig that doomed the first Holesky.
## Additional Info
- Geth doesn't serve payload bodies prior to genesis, which is why we use the legacy methods. I haven't checked with other ELs yet.
- Currently this is logging errors with _Capella_ genesis states generated by `ethereum-genesis-generator` because the `withdrawals_root` is not set correctly (it is 0x0). This is not a blocker for Holesky, as it starts from Bellatrix (Pari is investigating).
## Issue Addressed
I went through the code base and look for places where we acquire fork choice locks (after the deadlock bug was found and fixed in #4687), and discovered an instance where we re-acquire a lock immediately after dropping it. This shouldn't cause deadlock like the other issue, but is slightly less efficient.
## Issue Addressed
CI is plagued by `AddrAlreadyInUse` failures, which are caused by race conditions in allocating free ports.
This PR removes all usages of the `unused_port` crate for Lighthouse's HTTP API, in favour of passing `:0` as the listen address. As a result, the listen address isn't known ahead of time and must be read from the listening socket after it binds. This requires tying some self-referential knots, which is a little disruptive, but hopefully doesn't clash too much with Deneb 🤞
There are still a few usages of `unused_tcp4_port` left in cases where we start external processes, like the `watch` Postgres DB, Anvil, Geth, Nethermind, etc. Removing these usages is non-trivial because it's hard to read the port back from an external process after starting it with `--port 0`. We might be able to do something on Linux where we read from `/proc/`, but I'll leave that for future work.
* Implement `SignedBlockContent` decoding and fixed bug in `SignedBlockContent::new`
* Update Cargo.lock file
* Use `make_genesis_spec` to simplify test setup.
* Fix syntax errors.
## Issue Addressed
On a new network a user might require importing validators before waiting until genesis has occurred.
## Proposed Changes
Starts the validator client http api before waiting for genesis
## Additional Info
cc @antondlr
Web3Signer now requires Java runtime v17, see [v23.8.0 release](https://github.com/Consensys/web3signer/releases/tag/23.8.0).
We have some Web3Signer tests that requires a compatible Java runtime to be installed on dev machines. This PR updates `setup` documentation in Lighthouse book, and also fixes a small typo.
* move length update outside of if let in LRU cache
* add comment and use hex for G1_POINT_AT_INFINITY
* remove some misleading comments from `ssz_snappy`
* make sure we can't overflow on blobs by range requests with large counts
* downgrade gossip verification internal availability check error
* change blob rpc responses from BlockingFnWithManualSendOnIdle to BlockingFn
* remove unnecessary collect in blobs by range response
* add a comment to blobs by range response start slot logic
* typo persist_data_availabilty_checker -> persist_data_availability_checker
* unify cheap_state_advance_to_obtain_committees
## Issue Addressed
#4402
## Proposed Changes
This PR adds QUIC support to Lighthouse. As this is not officially spec'd this will only work between lighthouse <-> lighthouse connections. We attempt a QUIC connection (if the node advertises it) and if it fails we fallback to TCP.
This should be a backwards compatible modification. We want to test this functionality on live networks to observe any improvements in bandwidth/latency.
NOTE: This also removes the websockets transport as I believe no one is really using it. It should be mentioned in our release however.
Co-authored-by: João Oliveira <hello@jxs.pt>
* increase the max topic subscriptions #4581
* make the max_subscription limitation based off constants / configuration
* format
* wording & add deneb topic array
* reduce max_subscriptions_per_request to 2x
* format
* update comment
* Support per slot state diffs
* Store HierarchyConfig on disk. Support storing hdiffs at per slot level.
* Revert HierachyConfig change for testing.
* Add validity check for the hierarchy config when opening the DB.
* Update HDiff tests.
* Fix `get_cold_state` panic when the diff for the slot isn't stored.
* Use slots instead of epochs for storing snapshots in freezer DB.
* Add snapshot buffer to `diff_buffer_cache` instead of loading it from db every time.
* Add `hierarchy-exponents` cli flag to beacon node.
* Add test for `StorageStrategy::ReplayFrom` and ignore a flaky test.
* Drop hierarchy_config in tests for more frequent snapshot and fix an issue where hdiff wasn't stored unless it's a epoch boundary slot.
* Update comments and small cleanup.
* Deserialize into `SsePayloadAttributesV3` for Deneb fork. Update `SignedBlockContents::blobs_cloned` to return blobs for `BlindedBlockAndBlobSidecars`.
* Improve code readability and error handling when converting blinded block into full block.
## Issue Addressed
I noticed a node.js version warning on our CI, and thought about updating the version to get rid of this warning, but then realized we may not need node.js anymore now we're using `anvil` instead of `ganache`.
> The following actions uses node12 which is deprecated and will be forced to run on node16: actions/setup-node@v2. For more info: https://github.blog/changelog/2023-06-13-github-actions-all-actions-will-run-on-node16-instead-of-node12-by-default/
## Issue Addressed
Siren FAQ requires more information regarding network connections to lighthouse BN/VC
## Proposed Changes
Added more info regarding port, BN/VC flags, ssh tunneling and VPNs access
## Issue Addressed
N/A
## Proposed Changes
The current Advanced Networking page references the ["--listen-addresses"](14924dbc95/book/src/advanced_networking.md (L124C8-L124C8)) argument, which does not exist in the beacon node. This PR changes such instances of "--listen-addresses" to "--listen-address".
Additionally, the page mentions using sockets that [both listen to IPv6](14924dbc95/book/src/advanced_networking.md (L151)) in a dual-stack setup? Hence, this PR also changes said line to "using one socket for IPv4 and another socket for IPv6".
## Additional Info
None.
## Proposed Changes
New release to replace the cancelled v4.4.0 release.
This release includes the bugfix #4687 which avoids a deadlock that was present in v4.4.0.
## Additional Info
Awaiting testing over the weekend this will be merged Monday September 4th.
## Issue Addressed
Fix a deadlock introduced in #4236 which was caught during the v4.4.0 release testing cycle (with thanks to @paulhauner and `gdb`).
## Proposed Changes
Avoid re-locking the fork choice read lock when querying a state by root in the HTTP API. This avoids a deadlock due to the lock already being held.
## Additional Info
The [RwLock docs](https://docs.rs/lock_api/latest/lock_api/struct.RwLock.html#method.read) explicitly advise against re-locking:
> Note that attempts to recursively acquire a read lock on a RwLock when the current thread already holds one may result in a deadlock.
## Issue Addressed
N/A
## Proposed Changes
Adds the Chiado (Gnosis testnet) network to the builtin one.
## Additional Info
It's a fairly trivial change all things considered as the preset already exists, so shouldn't be hard to maintain.
It compiles and seems to work, but I'm sure I missed something?
Co-authored-by: Paul Hauner <paul@paulhauner.com>
## Issue Addressed
Fix a bug in the storage of the linear block roots array in the freezer DB. Previously this array was always written as part of state storage (or block backfill). With state pruning enabled by #4610, these states were no longer being written and as a result neither were the block roots.
The impact is quite low, we would just log an error when trying to forwards-iterate the block roots, which for validating nodes only happens when they try to look up blocks for peers:
> Aug 25 03:42:36.980 ERRO Missing chunk in forwards iterator chunk index: 49726, service: freezer_db
Any node checkpoint synced off `unstable` is affected and has a corrupt database. If you see the log above, you need to re-sync with the fix. Nodes that haven't checkpoint synced recently should _not_ be corrupted, even if they ran the buggy version.
## Proposed Changes
- Use a `ChunkWriter` to write the block roots when states are not being stored.
- Tweak the usage of `get_latest_restore_point` so that it doesn't return a nonsense value when state pruning is enabled.
- Tweak the guarantee on the block roots array so that block roots are assumed available up to the split slot (exclusive). This is a bit nicer than relying on anything to do with the latest restore point, which is a nonsensical concept when there aren't any restore points.
## Additional Info
I'm looking forward to deleting the chunked vector code for good when we merge tree-states 😁
## Issue Addressed
NA
## Proposed Changes
Add the Holesky network config as per 36e4ff2d51/custom_config_data.
Since the genesis state is ~190MB, I've opted to *not* include it in the binary and instead download it at runtime (see #4564 for context). To download this file we have:
- A hard-coded URL for a SigP-hosted S3 bucket with the Holesky genesis state. Assuming this download works correctly, users will be none the wiser that the state wasn't included in the binary (apart from some additional logs)
- If the user provides a `--checkpoint-sync-url` flag, then LH will download the genesis state from that server rather than our S3 bucket.
- If the user provides a `--genesis-state-url` flag, then LH will download the genesis state from that server regardless of the S3 bucket or `--checkpoint-sync-url` flag.
- Whenever a genesis state is downloaded it is checked against a checksum baked into the binary.
- A genesis state will never be downloaded if it's already included in the binary.
- There is a `--genesis-state-url-timeout` flag to tweak the timeout for downloading the genesis state file.
## Log Output
Example of log output when a state is downloaded:
```bash
Aug 23 05:40:13.424 INFO Logging to file path: "/Users/paul/.lighthouse/holesky/beacon/logs/beacon.log"
Aug 23 05:40:13.425 INFO Lighthouse started version: Lighthouse/v4.3.0-bd9931f+
Aug 23 05:40:13.425 INFO Configured for network name: holesky
Aug 23 05:40:13.426 INFO Data directory initialised datadir: /Users/paul/.lighthouse/holesky
Aug 23 05:40:13.427 INFO Deposit contract address: 0x4242424242424242424242424242424242424242, deploy_block: 0
Aug 23 05:40:13.427 INFO Downloading genesis state info: this may take some time on testnets with large validator counts, timeout: 60s, server: https://sigp-public-genesis-states.s3.ap-southeast-2.amazonaws.com/
Aug 23 05:40:29.895 INFO Starting from known genesis state service: beacon
```
Example of log output when there are no URLs specified:
```
Aug 23 06:29:51.645 INFO Logging to file path: "/Users/paul/.lighthouse/goerli/beacon/logs/beacon.log"
Aug 23 06:29:51.646 INFO Lighthouse started version: Lighthouse/v4.3.0-666a39c+
Aug 23 06:29:51.646 INFO Configured for network name: goerli
Aug 23 06:29:51.647 INFO Data directory initialised datadir: /Users/paul/.lighthouse/goerli
Aug 23 06:29:51.647 INFO Deposit contract address: 0xff50ed3d0ec03ac01d4c79aad74928bff48a7b2b, deploy_block: 4367322
The genesis state is not present in the binary and there are no known download URLs. Please use --checkpoint-sync-url or --genesis-state-url.
```
## Additional Info
I tested the `--genesis-state-url` flag with all 9 Goerli checkpoint sync servers on https://eth-clients.github.io/checkpoint-sync-endpoints/ and they all worked 🎉
My IDE eagerly formatted some `Cargo.toml`. I've disabled it but I don't see the value in spending time reverting the changes that are already there.
I also added the `GenesisStateBytes` enum to avoid an unnecessary clone on the genesis state bytes baked into the binary. This is not a huge deal on Mainnet, but will become more relevant when testing with big genesis states.
When we do a fresh checkpoint sync we're downloading the genesis state to check the `genesis_validators_root` against the finalised state we receive. This is not *entirely* pointless, since we verify the checksum when we download the genesis state so we are actually guaranteeing that the finalised state is on the same network. There might be a smarter/less-download-y way to go about this, but I've run out of cycles to figure that out. Perhaps we can grab it in the next release?
## Issue Addressed
`web3signer_tests` can sometimes timeout.
## Proposed Changes
Increase the `web3signer_tests` timeout from 20s to 30s
## Additional Info
Previously I believed the consistent CI failures were due to this, but it ended up being something different. See below:
---
The timing of this makes it very likely it is related to the [latest release of `web3-signer`](https://github.com/Consensys/web3signer/releases/tag/23.8.1).
I now believe this is due to an out of date Java runtime on our runners. A newer version of Java became a requirement with the new `web3-signer` release.
However, I was getting timeouts locally, which implies that the margin before timeout is quite small at 20s so bumping it up to 30s could be a good idea regardless.
## Issue Addressed
N/A
## Proposed Changes
Remove the `hidden(true)` modifier on the `--gui` flag so it shows up when running `lighthouse bn --help`
## Additional Info
We need to include this now that Siren has had its first stable release.
## Issue Addressed
#4654
## Proposed Changes
Only log error if we're unable to read slot clock after genesis.
I thought about simply down grading the `error` to a `warn`, but feel like it's still unnecessary noise before genesis, and it would be good to retain error log if we're pass genesis. But I'd be ok with just downgrading the log level, too.
## Issue Addressed
Closes#4473 (take 3)
## Proposed Changes
- Send a 202 status code by default for duplicate blocks, instead of 400. This conveys to the caller that the block was published, but makes no guarantees about its validity. Block relays can count this as a success or a failure as they wish.
- For users wanting finer-grained control over which status is returned for duplicates, a flag `--http-duplicate-block-status` can be used to adjust the behaviour. A 400 status can be supplied to restore the old (spec-compliant) behaviour, or a 200 status can be used to silence VCs that warn loudly for non-200 codes (e.g. Lighthouse prior to v4.4.0).
- Update the Lighthouse VC to gracefully handle success codes other than 200. The info message isn't the nicest thing to read, but it covers all bases and isn't a nasty `ERRO`/`CRIT` that will wake anyone up.
## Additional Info
I'm planning to raise a PR to `beacon-APIs` to specify that clients may return 202 for duplicate blocks. Really it would be nice to use some 2xx code that _isn't_ the same as the code for "published but invalid". I think unfortunately there aren't any suitable codes, and maybe the best fit is `409 CONFLICT`. Given that we need to fix this promptly for our release, I think using the 202 code temporarily with configuration strikes a nice compromise.
## Issue Addressed
updates underlying dependencies and removes the ignored `RUSTSEC`'s for `cargo audit`.
Also switches `procinfo` to `procfs` on `eth2` to remove the `nom` warning, `procinfo` is unmaintained see [here](https://github.com/danburkert/procinfo-rs/issues/46).
## Issue Addressed
Temporary ignore for #4651. We are unaffected, and upstream will be patched in a few days.
## Proposed Changes
- Ignore cargo audit failures (ublocks CI)
- Use `--locked` when building with `cross`. We use `--locked` for regular builds, and I think excluding it from `cross` was just an oversight.
I think for consistent builds it makes sense to use `--locked` while building. This is particularly relevant for release binaries, which otherwise will just use a random selection of dependencies that exist on build day (near impossible to recreate if we had to).
## Issue Addressed
Fixes a bug in the handling of `--beacon-process-max-workers` which caused it to have no effect.
## Proposed Changes
For this PR I channeled @ethDreamer and saw deep into the faulty CLI config -- this bug is almost identical to the one Mark found and fixed in #4622.
`parent_finalized.epoch + 1 > block_epoch` will never be `true` since as the comment says:
```
A block in epoch `N` cannot contain attestations which would finalize an epoch higher than `N - 1`.
```
## Issue Addressed
Closes#3210Closes#3211
## Proposed Changes
- Checkpoint sync from the latest finalized state regardless of its alignment.
- Add the `block_root` to the database's split point. This is _only_ added to the in-memory split in order to avoid a schema migration. See `load_split`.
- Add a new method to the DB called `get_advanced_state`, which looks up a state _by block root_, with a `state_root` as fallback. Using this method prevents accidental accesses of the split's unadvanced state, which does not exist in the hot DB and is not guaranteed to exist in the freezer DB at all. Previously Lighthouse would look up this state _from the freezer DB_, even if it was required for block/attestation processing, which was suboptimal.
- Replace several state look-ups in block and attestation processing with `get_advanced_state` so that they can't hit the split block's unadvanced state.
- Do not store any states in the freezer database by default. All states will be deleted upon being evicted from the hot database unless `--reconstruct-historic-states` is set. The anchor info which was previously used for checkpoint sync is used to implement this, including when syncing from genesis.
## Additional Info
Needs further testing. I want to stress-test the pruned database under Hydra.
The `get_advanced_state` method is intended to become more relevant over time: `tree-states` includes an identically named method that returns advanced states from its in-memory cache.
Co-authored-by: realbigsean <seananderson33@gmail.com>
* remove protoc and token from network tests github action
* delete unused beacon chain methods
* downgrade writing blobs to store log
* reduce diff in block import logic
* remove some todo's and deneb built in network
* remove unnecessary error, actually use some added metrics
* remove some metrics, fix missing components on publish funcitonality
* fix status tests
* rename sidecar by root to blobs by root
* clean up some metrics
* remove unnecessary feature gate from attestation subnet tests, clean up blobs by range response code
* pawan's suggestion in `protocol_info`, peer score in matching up batch sync block and blobs
* fix range tests for deneb
* pub block and blob db cache behind the same mutex
* remove unused errs and an empty file
* move sidecar trait to new file
* move types from payload to eth2 crate
* update comment and add flag value name
* make function private again, remove allow unused
* use reth rlp for tx decoding
* fix compile after merge
* rename kzg commitments
* cargo fmt
* remove unused dep
* Update beacon_node/execution_layer/src/lib.rs
Co-authored-by: Pawan Dhananjay <pawandhananjay@gmail.com>
* Update beacon_node/beacon_processor/src/lib.rs
Co-authored-by: Pawan Dhananjay <pawandhananjay@gmail.com>
* pawan's suggestiong for vec capacity
* cargo fmt
* Revert "use reth rlp for tx decoding"
This reverts commit 5181837d81.
* remove reth rlp
---------
Co-authored-by: Pawan Dhananjay <pawandhananjay@gmail.com>
* Update mock builder, mev-rs dependencies, eth2 lib to support deneb builder flow
* Replace `sharingForkTime` with `cancunTime`
* Patch `ethereum-consensus` to include some deneb-devnet-8 changes
* Add deneb builder test and fix block contents deserialization
* Fix builder bid encoding issue and passing deneb builder test \o/
* Fix test compilation
* Revert `cancunTime` change in genesis to pass doppelganger tests
## Proposed Changes
This PR updates `blst` to 0.3.11, which gives us _runtime detection of CPU features_ 🎉
Although [performance benchmarks](https://gist.github.com/michaelsproul/f759fa28dfa4003962507db34b439d6c) don't show a substantial detriment to running the `portable` build vs `modern`, in order to take things slowly I propose the following roll-out strategy:
- Keep both `modern` and `portable` builds for releases/Docker images.
- Run the `portable` build on half of SigP's infrastructure to monitor for performance deficits.
- Listen out for user issues with the `portable` builds (e.g. SIGILLs from misdetected hardware).
- Make the `portable` build the default and remove the `modern` build from our release binaries & Docker images.
It seems `post_validator_duties_sync` is the only api which doesn't have its own metric in `duties_service`, this PR adds `metrics::VALIDATOR_DUTIES_SYNC_HTTP_POST` for completeness.
Since `tolerant_current_epoch` is expected to be either `current_epoch` or `current_epoch+1`, we can eliminate a case here.
And added a comment about `compute_historic_attester_duties` , since `RelativeEpoch::from_epoch` will only allow `request_epoch == current_epoch-1` when `request_epoch < current_epoch`.
## Issue Addressed
Closes#4245
## Proposed Changes
- If an SSE channel fills up, send a comment instead of terminating the stream.
- Add a CLI flag for scaling up the SSE buffer: `--http-sse-capacity-multiplier N`.
## Additional Info
~~Blocked on #4462. I haven't rebased on that PR yet for initial testing, because it still needs some more work to handle long-running HTTP threads.~~
- [x] Add CLI flag tests.
## Issue Addressed
The feature flag used to control this feature is `disable_backfill` instead of `disable-backfill`.
kudos to @michaelsproul for discovering this bug!
## Issue Addressed
Closes#3404 (mostly)
## Proposed Changes
- Remove all uses of Warp's `and_then` (which backtracks) in favour of `then` (which doesn't).
- Bump the priority of the `POST` method for `v2/blocks` to `P0`. Publishing a block needs to happen quickly.
- Run the new SSZ POST endpoints on the beacon processor. I think this was missed in between merging #4462 and #4504/#4479.
- Fix a minor issue in the validator registrations endpoint whereby an error from spawning the task on the beacon processor would be dropped.
## Additional Info
I've tested this manually and can confirm that we no longer get the dreaded `Unsupported endpoint version` errors for queries like:
```
$ curl -X POST -H "Content-Type: application/json" --data @block.json "http://localhost:5052/eth/v2/beacon/blocks" | jq
{
"code": 400,
"message": "BAD_REQUEST: WeakSubjectivityConflict",
"stacktraces": []
}
```
```
$ curl -X POST -H "Content-Type: application/octet-stream" --data @block.json "http://localhost:5052/eth/v2/beacon/blocks" | jq
{
"code": 400,
"message": "BAD_REQUEST: invalid SSZ: OffsetOutOfBounds(572530811)",
"stacktraces": []
}
```
```
$ curl "http://localhost:5052/eth/v2/validator/blocks/7067595"
{"code":400,"message":"BAD_REQUEST: invalid query: Invalid query string","stacktraces":[]}
```
However, I can still trigger it by leaving off the `Content-Type`. We can re-test this aspect with #4575.
## Issue Addressed
#4538
## Proposed Changes
add newtype wrapper around DialError that extracts error messages and logs them in a more readable format
## Additional Info
I was able to test Transport Dial Errors in the situation where a libp2p instance attempts to ping a nonexistent peer. That error message should look something like
`A transport level error has ocurred: Connection refused (os error 61)`
AgeManning mentioned we should try fetching only the most inner error (in situations where theres a nested error). I took a stab at implementing that
For non transport DialErrors, I wrote out the error messages explicitly (as per the docs). Could potentially clean things up here if thats not necessary
Co-authored-by: Age Manning <Age@AgeManning.com>
## Issue Addressed
NA
## Proposed Changes
Rather than spawning new tasks on the tokio executor to process each HTTP API request, send the tasks to the `BeaconProcessor`. This achieves:
1. Places a bound on how many concurrent requests are being served (i.e., how many we are actually trying to compute at one time).
1. Places a bound on how many requests can be awaiting a response at one time (i.e., starts dropping requests when we have too many queued).
1. Allows the BN prioritise HTTP requests with respect to messages coming from the P2P network (i.e., proiritise importing gossip blocks rather than serving API requests).
Presently there are two levels of priorities:
- `Priority::P0`
- The beacon processor will prioritise these above everything other than importing new blocks.
- Roughly all validator-sensitive endpoints.
- `Priority::P1`
- The beacon processor will prioritise practically all other P2P messages over these, except for historical backfill things.
- Everything that's not `Priority::P0`
The `--http-enable-beacon-processor false` flag can be supplied to revert back to the old behaviour of spawning new `tokio` tasks for each request:
```
--http-enable-beacon-processor <BOOLEAN>
The beacon processor is a scheduler which provides quality-of-service and DoS protection. When set to
"true", HTTP API requests will queued and scheduled alongside other tasks. When set to "false", HTTP API
responses will be executed immediately. [default: true]
```
## New CLI Flags
I added some other new CLI flags:
```
--beacon-processor-aggregate-batch-size <INTEGER>
Specifies the number of gossip aggregate attestations in a signature verification batch. Higher values may
reduce CPU usage in a healthy network while lower values may increase CPU usage in an unhealthy or hostile
network. [default: 64]
--beacon-processor-attestation-batch-size <INTEGER>
Specifies the number of gossip attestations in a signature verification batch. Higher values may reduce CPU
usage in a healthy network whilst lower values may increase CPU usage in an unhealthy or hostile network.
[default: 64]
--beacon-processor-max-workers <INTEGER>
Specifies the maximum concurrent tasks for the task scheduler. Increasing this value may increase resource
consumption. Reducing the value may result in decreased resource usage and diminished performance. The
default value is the number of logical CPU cores on the host.
--beacon-processor-reprocess-queue-len <INTEGER>
Specifies the length of the queue for messages requiring delayed processing. Higher values may prevent
messages from being dropped while lower values may help protect the node from becoming overwhelmed.
[default: 12288]
```
I needed to add the max-workers flag since the "simulator" flavor tests started failing with HTTP timeouts on the test assertions. I believe they were failing because the Github runners only have 2 cores and there just weren't enough workers available to process our requests in time. I added the other flags since they seem fun to fiddle with.
## Additional Info
I bumped the timeouts on the "simulator" flavor test from 4s to 8s. The prioritisation of consensus messages seems to be causing slower responses, I guess this is what we signed up for 🤷
The `validator/register` validator has some special handling because the relays have a bad habit of timing out on these calls. It seems like a waste of a `BeaconProcessor` worker to just wait for the builder API HTTP response, so we spawn a new `tokio` task to wait for a builder response.
I've added an optimisation for the `GET beacon/states/{state_id}/validators/{validator_id}` endpoint in [efbabe3](efbabe3252). That's the endpoint the VC uses to resolve pubkeys to validator indices, and it's the endpoint that was causing us grief. Perhaps I should move that into a new PR, not sure.
* remove closure from `check_availability_mayb_import`
* impove logging, add wrapper struct to requested ids
* improve logging
* only log if we're in deneb. Only delay lookup if we're in deneb
* fix bug in missing components check
## Issue Addressed
Addresses #2557
## Proposed Changes
Adds the `lighthouse validator-manager` command, which provides:
- `lighthouse validator-manager create`
- Creates a `validators.json` file and a `deposits.json` (same format as https://github.com/ethereum/staking-deposit-cli)
- `lighthouse validator-manager import`
- Imports validators from a `validators.json` file to the VC via the HTTP API.
- `lighthouse validator-manager move`
- Moves validators from one VC to the other, utilizing only the VC API.
## Additional Info
In 98bcb947c I've reduced some VC `ERRO` and `CRIT` warnings to `WARN` or `DEBG` for the case where a pubkey is missing from the validator store. These were being triggered when we removed a validator but still had it in caches. It seems to me that `UnknownPubkey` will only happen in the case where we've removed a validator, so downgrading the logs is prudent. All the logs are `DEBG` apart from attestations and blocks which are `WARN`. I thought having *some* logging about this condition might help us down the track.
In 856cd7e37d I've made the VC delete the corresponding password file when it's deleting a keystore. This seemed like nice hygiene. Notably, it'll only delete that password file after it scans the validator definitions and finds that no other validator is also using that password file.
## Issue Addressed
NA
## Proposed Changes
We've been seeing a lot of [CI failures](https://github.com/sigp/lighthouse/actions/runs/5781296217/job/15666209142) with errors like this:
```
---- extra_interchange_tests::export_same_key_twice stdout ----
thread 'extra_interchange_tests::export_same_key_twice' panicked at 'called `Result::unwrap()` on an `Err` value: SQLError("Unable to open database: Error(None)")', validator_client/slashing_protection/src/extra_interchange_tests.rs:48:67
```
I'm assuming they're timeouts. I noticed that tests have a 0.1s timeout. Perhaps this just doesn't cut it when our new runners are overloaded.
## Additional Info
NA
**Motivation**
As clarified [on discord](https://discord.com/channels/605577013327167508/605577013331361793/1121246688183603240), sync committee contributions are not delayed if DP is enabled.
**Description**
This PR updates doppelganger note about sync committee contributions. Based on the current docs, a user might assume that DP is not working as expected.
* Low hanging fruits
* Remove unnecessary todo
I think it's fine to not handle this since the calling functions handle the error.
No specific reason imo to handle it in the function as well.
* Rename BlobError to GossipBlobError
I feel this signified better what the error is for. The BlobError was only for failures when gossip
verifying a blob. We cannot get this error when doing rpc validation
* Remove the BlockError::BlobValidation variant
This error was only there to appease gossip verification before publish.
It's unclear how to peer score this error since this cannot actually occur during any
block verification flows.
This commit introuduces an additional error type BlockContentsError to better represent the
Error type
* Add docs for peer scoring (or lack thereof) of AvailabilityCheck errors
* I do not see a non-convoluted way of doing this. Okay to have some redundant code here
* Removing this to catch the failure red handed
* Fix compilation
* Cannot be deleted because some tests assume the trait impl
Also useful to have around for testing in the future imo
* Add some metrics and logs
* Only process `Imported` variant in sync_methods
The only additional thing for other variants that might be useful is logging. We can do that
later if required
* Convert to TryFrom
Not really sure where this would be used, but just did what the comment says.
Could consider just returning the Block variant for a deneb block in the From version
* Unlikely to change now
* This is fine as this is max_rpc_size per rpc chunk (for blobs, it would be 128kb max)
* Log count instead of individual blobs, can delete log later if it becomes too annoying.
* Add block production blob verification timer
* Extend block_straemer test to deneb
* Remove dbg statement
* Fix tests
## Issue Addressed
Addresses [#4401](https://github.com/sigp/lighthouse/issues/4401)
## Proposed Changes
Shift some constants into ```ChainSpec``` and remove the constant values from code space.
## Additional Info
I mostly used ```MainnetEthSpec::default_spec()``` for getting ```ChainSpec```. I wonder Did I make a mistake about that.
Co-authored-by: armaganyildirak <armaganyildirak@gmail.com>
Co-authored-by: Paul Hauner <paul@paulhauner.com>
Co-authored-by: Age Manning <Age@AgeManning.com>
Co-authored-by: Diva M <divma@protonmail.com>
## Issue Addressed
Upgrade libp2p to v0.52
## Proposed Changes
- **Workflows**: remove installation of `protoc`
- **Book**: remove installation of `protoc`
- **`Dockerfile`s and `cross`**: remove custom base `Dockerfile` for cross since it's no longer needed. Remove `protoc` from remaining `Dockerfiles`s
- **Upgrade `discv5` to `v0.3.1`:** we have some cool stuff in there: no longer needs `protoc` and faster ip updates on cold start
- **Upgrade `prometheus` to `0.21.0`**, now it no longer needs encoding checks
- **things that look like refactors:** bunch of api types were renamed and need to be accessed in a different (clearer) way
- **Lighthouse network**
- connection limits is now a behaviour
- banned peers no longer exist on the swarm level, but at the behaviour level
- `connection_event_buffer_size` now is handled per connection with a buffer size of 4
- `mplex` is deprecated and was removed
- rpc handler now logs the peer to which it belongs
## Additional Info
Tried to keep as much behaviour unchanged as possible. However, there is a great deal of improvements we can do _after_ this upgrade:
- Smart connection limits: Connection limits have been checked only based on numbers, we can now use information about the incoming peer to decide if we want it
- More powerful peer management: Dial attempts from other behaviours can be rejected early
- Incoming connections can be rejected early
- Banning can be returned exclusively to the peer management: We should not get connections to banned peers anymore making use of this
- TCP Nat updates: We might be able to take advantage of confirmed external addresses to check out tcp ports/ips
Co-authored-by: Age Manning <Age@AgeManning.com>
Co-authored-by: Akihito Nakano <sora.akatsuki@gmail.com>
## Issue Addressed
Solves #4442
## Proposed Changes
EL clients log errors if we don't query this endpoint, but they are making releases that remove this error logging. After those are out we can stop calling it, after which point EL teams will remove the endpoint entirely.
Refer https://hackmd.io/@n0ble/deprecate-exchgTC
Some updates in the FAQ based on issues seen on Discord. Additionally, corrected the disk usage on the default SPRP as the previously provided value is not correct.
Co-authored-by: chonghe <44791194+chong-he@users.noreply.github.com>
Often when testing I have to create a hack which is annoying to maintain.
I think it might be handy to add a custom compile-time flag that developers can use if they want to test things locally without having to backfill a bunch of blocks.
There is probably an argument to have a feature called "backfill" which is enabled by default and can be disabled. I didn't go this route because I think it's counter-intuitive to have a feature that enables a core and necessary behaviour.
## Issue Addressed
The PR fixes a bug where the the ideal rewards for source and head were incorrectly set.
Output from testing a validator that performed optimally in a Phase 0 epoch , note the `source` and `target` under ideal rewards is incorrect (compared to the actual `total_rewards` below):
```json
{
"ideal_rewards": [
...
{
"effective_balance": "32000000000",
"head": "18771",
"target": "18770",
"source": "18729",
"inclusion_delay": "17083",
"inactivity": "0"
}
],
"total_rewards": [
{
"validator_index": "0",
"head": "18729",
"target": "18770",
"source": "18771",
"inclusion_delay": "17083",
"inactivity": "0"
}
]
```
## Proposed Changes
- Fix bad `state_root` reuse in `lcli transition-blocks` that resulted in invalid results at skipped slots.
- Modernise `lcli pretty-ssz` to include fork-generic decoders for `SignedBeaconBlock` and `BeaconState` which respect the `--network`/`--testnet-dir` flag.
## Additional Info
Breaking change: the underscore names like `signed_block_merge` are removed in favour of the fork-generic name `SignedBeaconBlock`, and fork-specific names which match the superstruct variants, e.g. `SignedBeaconBlockMerge`.
## Proposed Changes
Remove patch for `arbitrary` in favour of upstream, now that the `arithmetic_side_effects` lint no longer triggers in derive macro code.
## Additional Info
~~Blocked on Rust 1.71.0, to be released 13 July 23~~
* changed name
* Fix sidecars
* Added query type and parrameter
* added query struct and function
* added method
* improved filtering method
* added blob_sidecar_list_indexed to block_id
* minor blobqueryindex fix
* function and formatting fix
* minor function and naming fix
* minor changes
## Issue Addressed
NA
## Proposed Changes
Carries on from #4115, with the following modifications:
1. Self-hosted runners are only enabled if `github.repository == sigp/lighthouse`.
- This allows forks to still have Github-hosted CI.
- This gives us a method to switch back to Github-runners if we have extended downtime on self-hosted.
1. Does not remove any existing dependency builds for Github-hosted runners (e.g., installing the latest Rust).
1. Adds the `WATCH_HOST` environment variable which defines where we expect to find the postgres db in the `watch` tests. This should be set to `host.docker.internal` for the tests to pass on self-hosted runners.
## Additional Info
NA
Co-authored-by: antondlr <anton@delaruelle.net>
## Issue Addressed
n/a Noticed this while working on something else
## Proposed Changes
- leverage the appropriate types to avoid a bunch of `unwrap` and errors
## Additional Info
n/a
## Issue Addressed
Speed up CI by installing foundry with Github action instead of building Anvil from source.
Building anvil from source on GItHub hosted runners currently takes about 10 mins. Using the `foundry-toolchain` action to install only takes about 2 seconds.
## Issue Addressed
N/A
## Proposed Changes
Add lints for rust 1.71
[3789134](3789134ae2) is probably the one that needs most attention as it changes beacon state code. I changed the `is_in_inactivity_leak ` function to return a `ArithError` as not all consumers of that function work well with a `BeaconState::Error`.
## Issue Addressed
This PR attempts to workaround the recent frequent eth1 simulator failures caused by missing eth logs from Anvil.
> FailedToInsertDeposit(NonConsecutive { log_index: 1, expected: 0 })
This usually occurs at the beginning of the tests, and it guarantees a timeout after a few hours if this log shows up, and this is currently causing our CIs to fail quite frequently.
Example failure here: https://github.com/sigp/lighthouse/actions/runs/5525760195/jobs/10079736914
## Proposed Changes
The quick fix applied here adds a timeout to node startup and restarts the node again.
- Add a 60 seconds timeout to beacon node startup in eth1 simulator tests. It takes ~10 seconds on my machine, but could take longer on CI runners.
- Wrap the startup code in a retry function, that allows for 3 retries before returning an error.
## Additional Info
We should probably raise an issue under the Anvil GitHub repo there so this can be further investigated.
## Issue Addressed
Addresses an issue where CI could fail due to an nonexisting file error:
```
Run ./clean.sh
rm: cannot remove '/home/runner/.lighthouse/local-testnet/geth_datadir4/geth/fastcache.tmp.1549331618': No such file or directory
Error: Process completed with exit code 1.
```
This seems to happen quite frequently now, I'm not sure exactly why but perhaps worth trying suppressing the prompt?
https://github.com/sigp/lighthouse/actions/runs/5455027574/jobs/9925916159?pr=4463
## Proposed Changes
Replace `wget` in the EF-tests makefile with `curl`.
On macOS `curl` is pre-installed, and I found myself making this change to avoid installing `wget`.
The `-L` flag is used to follow redirects which is useful if a repo gets renamed, and more similar to `wget`'s default behaviour.
## Issue Addressed
Fixes occasional compilation errors with mev-rs (see #4456).
## Proposed Changes
- Update `mev-rs` to the latest version, which allows us to remove hacky `[patch]` sections
- Update the `axum` version used in `watch` so LH only uses a single version
## Issue Addressed
#4488
## Proposed Changes
- Remove all instances of the `required` modifier where we have a default value specified for a subcommand
## Additional Info
N/A
## Issue Addressed
When trying to run `eth1-sim` locally, the simulator doesn't start for me, and panicked due to duplicate arg names for `proposer-nodes` (using same arg names as `nodes`). Not sure why this isn't failing on CI but failing on mine 🤔
```
thread 'main' panicked at 'Argument short must be unique
thread 'main' panicked at 'Argument long must be unique
```
## Issue Addressed
Fix an issue observed by `@zlan` on Discord where Lighthouse would sometimes return this error when looking up states via the API:
> {"code":500,"message":"UNHANDLED_ERROR: ForkChoiceError(MissingProtoArrayBlock(0xc9cf1495421b6ef3215d82253b388d77321176a1dcef0db0e71a0cd0ffc8cdb7))","stacktraces":[]}
## Proposed Changes
The error stems from a faulty assumption in the HTTP API logic: that any state in the hot database must have its block in fork choice. This isn't true because the state's hot database may update much less frequently than the fork choice store, e.g. if reconstructing states (where freezer migration pauses), or if the freezer migration runs slowly. There could also be a race between loading the hot state and checking fork choice, e.g. even if the finalization migration of DB+fork choice were atomic, the update could happen between the 1st and 2nd calls.
To address this I've changed the HTTP API logic to use the finalized block's execution status as a fallback where it is safe to do so. In the case where a block is non-canonical and prior to finalization (permanently orphaned) we default `execution_optimistic` to `true`.
## Additional Info
I've also added a new CLI flag to reduce the frequency of the finalization migration as this is useful for several purposes:
- Spacing out database writes (less frequent, larger batches)
- Keeping a limited chain history with high availability, e.g. the last month in the hot database.
This new flag made it _substantially_ easier to test this change. It was extracted from `tree-states` (where it's called `--db-migration-period`), which is why this PR also carries the `tree-states` label.
## Issue Addressed
#4494
## Proposed Changes
- Remove explicit re-exports of various types to appease the new compiler lint
## Additional Info
It seems `warn(hidden_glob_reexports)` is the main culprit.
## Proposed Changes
* Add `lcli state-root` command for computing the hash tree root of a `BeaconState`.
* Add a `--network` flag which can be used instead of `--testnet-dir` to set the network, e.g. Mainnet, Goerli, Gnosis.
* Use the new network flag in `transition-blocks`, `skip-slots`, and `block-root`, which previously only supported mainnet.
* **BREAKING CHANGE** Remove the default value of `~/.lighthouse/testnet` from `--testnet-dir`. This may have made sense in previous versions where `lcli` was more testnet focussed, but IMO it is an unnecessary complication and foot-gun today.
*Replaces #4434. It is identical, but this PR has a smaller diff due to a curated commit history.*
## Issue Addressed
NA
## Proposed Changes
This PR moves the scheduling logic for the `BeaconProcessor` into a new crate in `beacon_node/beacon_processor`. Previously it existed in the `beacon_node/network` crate.
This addresses a circular-dependency problem where it's not possible to use the `BeaconProcessor` from the `beacon_chain` crate. The `network` crate depends on the `beacon_chain` crate (`network -> beacon_chain`), but importing the `BeaconProcessor` into the `beacon_chain` crate would create a circular dependancy of `beacon_chain -> network`.
The `BeaconProcessor` was designed to provide queuing and prioritized scheduling for messages from the network. It has proven to be quite valuable and I believe we'd make Lighthouse more stable and effective by using it elsewhere. In particular, I think we should use the `BeaconProcessor` for:
1. HTTP API requests.
1. Scheduled tasks in the `BeaconChain` (e.g., state advance).
Using the `BeaconProcessor` for these tasks would help prevent the BN from becoming overwhelmed and would also help it to prioritize operations (e.g., choosing to process blocks from gossip before responding to low-priority HTTP API requests).
## Additional Info
This PR is intended to have zero impact on runtime behaviour. It aims to simply separate the *scheduling* code (i.e., the `BeaconProcessor`) from the *business logic* in the `network` crate (i.e., the `Worker` impls). Future PRs (see #4462) can build upon these works to actually use the `BeaconProcessor` for more operations.
I've gone to some effort to use `git mv` to make the diff look more like "file was moved and modified" rather than "file was deleted and a new one added". This should reduce review burden and help maintain commit attribution.
## Issue Addressed
[Users on Twitter](https://twitter.com/ashekhirin/status/1676334843192397824) are getting checkpoint sync URL timeouts with the default of 60s, so this PR increases the default timeout to 3 minutes.
I've also added a short section to the book about adjusting the timeout with `--checkpoint-sync-url-timeout`.
## Issue Addressed
#4331
## Proposed Changes
- Use comparison rather than strict equality between the earliest epoch we know about and the backfill target (which will be the most recent WSP by default or genesis)
- Add helper function `BackFillSync<T>::would_complete` to achieve this in one location
## Additional Info
- There's an ad hoc test for this in #4461
Co-authored-by: Age Manning <Age@AgeManning.com>
* changed name
* Fix sidecars
* update get blobs endpoint name from blobs to blob_sidecars
---------
Co-authored-by: Rahul Dogra <rahulcooldogra@gmail.com>
We now officially have ipv6 support. The mainnet bootnodes have been updated to support ipv6. This PR updates lighthouse's internal bootnodes for mainnet to avoid fetching them on initial load.
* Relocate epoch cache to BeaconState
* Optimize per block processing by pulling previous epoch & current epoch calculation up.
* Revert `get_cow` change (no performance improvement)
* Initialize `EpochCache` in epoch processing and load it from state when getting base rewards.
* Initialize `EpochCache` at start of block processing if required.
* Initialize `EpochCache` in `transition_blocks` if `exclude_cache_builds` is enabled
* Fix epoch cache initialization logic
* Remove FIXME comment.
* Cache previous & current epochs in `consensus_context.rs`.
* Move `get_base_rewards` from `ConsensusContext` to `BeaconState`.
* Update Milhouse version
## Issue Addressed
#4118
## Proposed Changes
This PR introduces a "progressive balances" cache on the `BeaconState`, which keeps track of the accumulated target attestation balance for the current & previous epochs. The cached values are utilised by fork choice to calculate unrealized justification and finalization (instead of converting epoch participation arrays to balances for each block we receive).
This optimization will be rolled out gradually to allow for more testing. A new `--progressive-balances disabled|checked|strict|fast` flag is introduced to support this:
- `checked`: enabled with checks against participation cache, and falls back to the existing epoch processing calculation if there is a total target attester balance mismatch. There is no performance gain from this as the participation cache still needs to be computed. **This is the default mode for now.**
- `strict`: enabled with checks against participation cache, returns error if there is a mismatch. **Used for testing only**.
- `fast`: enabled with no comparative checks and without computing the participation cache. This mode gives us the performance gains from the optimization. This is still experimental and not currently recommended for production usage, but will become the default mode in a future release.
- `disabled`: disable the usage of progressive cache, and use the existing method for FFG progression calculation. This mode may be useful if we find a bug and want to stop the frequent error logs.
### Tasks
- [x] Initial cache implementation in `BeaconState`
- [x] Perform checks in fork choice to compare the progressive balances cache against results from `ParticipationCache`
- [x] Add CLI flag, and disable the optimization by default
- [x] Testing on Goerli & Benchmarking
- [x] Move caching logic from state processing to the `ProgressiveBalancesCache` (see [this comment](https://github.com/sigp/lighthouse/pull/4362#discussion_r1230877001))
- [x] Add attesting balance metrics
Co-authored-by: Jimmy Chen <jimmy@sigmaprime.io>
## Issue Addressed
[#4292](https://github.com/sigp/lighthouse/issues/4292)
## Proposed Changes
Updated the node health endpoint
will return a 200 status code if `!syncing && !el_offline && !optimistic`
wil return a 206 if `(syncing || optimistic) && !el_offline`
will return a 503 if `el_offline`
## Additional Info
## Issue Addressed
[#4259](https://github.com/sigp/lighthouse/issues/4259)
## Proposed Changes
debounce spammy `Unable to send message to the beacon processor` log messages
## Additional Info
We could potentially debounce other logs that have the potential to be "spammy".
After some feedback we decided to additionally add the following change:
create a newtype wrapper around `mpsc::Sender<BeaconWorkEvent<T>>`. When there is an error on the try_send method on the wrapper, we increase a counter metric with one label per work type.
* some blob reprocessing work
* remove ForceBlockLookup
* reorder enum match arms in sync manager
* a lot more reprocessing work
* impl logic for triggerng blob lookups along with block lookups
* deal with rpc blobs in groups per block in the da checker. don't cache missing blob ids in the da checker.
* make single block lookup generic
* more work
* add delayed processing logic and combine some requests
* start fixing some compile errors
* fix compilation in main block lookup mod
* much work
* get things compiling
* parent blob lookups
* fix compile
* revert red/stevie changes
* fix up sync manager delay message logic
* add peer usefulness enum
* should remove lookup refactor
* consolidate retry error handling
* improve peer scoring during certain failures in parent lookups
* improve retry code
* drop parent lookup if either req has a peer disconnect during download
* refactor single block processed method
* processing peer refactor
* smol bugfix
* fix some todos
* fix lints
* fix lints
* fix compile in lookup tests
* fix lints
* fix lints
* fix existing block lookup tests
* renamings
* fix after merge
* cargo fmt
* compilation fix in beacon chain tests
* fix
* refactor lookup tests to work with multiple forks and response types
* make tests into macros
* wrap availability check error
* fix compile after merge
* add random blobs
* start fixing up lookup verify error handling
* some bug fixes and the start of deneb only tests
* make tests work for all forks
* track information about peer source
* error refactoring
* improve peer scoring
* fix test compilation
* make sure blobs are sent for processing after stream termination, delete copied tests
* add some tests and fix a bug
* smol bugfixes and moar tests
* add tests and fix some things
* compile after merge
* lots of refactoring
* retry on invalid block/blob
* merge unknown parent messages before current slot lookup
* get tests compiling
* penalize blob peer on invalid blobs
* Check disk on in-memory cache miss
* Update beacon_node/beacon_chain/src/data_availability_checker/overflow_lru_cache.rs
* Update beacon_node/network/src/sync/network_context.rs
Co-authored-by: Divma <26765164+divagant-martian@users.noreply.github.com>
* fix bug in matching blocks and blobs in range sync
* pr feedback
* fix conflicts
* upgrade logs from warn to crit when we receive incorrect response in range
* synced_and_connected_within_tolerance -> should_search_for_block
* remove todo
* add data gas used and update excess data gas to u64
* Fix Broken Overflow Tests
* payload verification with commitments
* fix merge conflicts
* restore payload file
* Restore payload file
* remove todo
* add max blob commitments per block
* c-kzg lib update
* Fix ef tests
* Abstract over minimal/mainnet spec in kzg crate
* Start integrating new KZG
* checkpoint sync without alignment
* checkpoint sync without alignment
* add import
* add import
* query for checkpoint state by slot rather than state root (teku doesn't serve by state root)
* query for checkpoint state by slot rather than state root (teku doesn't serve by state root)
* loosen check
* get state first and query by most recent block root
* Revert "loosen check"
This reverts commit 069d13dd63.
* get state first and query by most recent block root
* merge max blobs change
* simplify delay logic
* rename unknown parent sync message variants
* rename parameter, block_slot -> slot
* add some docs to the lookup module
* use interval instead of sleep
* drop request if blocks and blobs requests both return `None` for `Id`
* clean up `find_single_lookup` logic
* add lookup source enum
* clean up `find_single_lookup` logic
* add docs to find_single_lookup_request
* move LookupSource our of param where unnecessary
* remove unnecessary todo
* query for block by `state.latest_block_header.slot`
* fix lint
* fix merge transition ef tests
* fix test
* fix test
* fix observed blob sidecars test
* Add some metrics (#33)
* fix protocol limits for blobs by root
* Update Engine API for 1:1 Structure Method
* make beacon chain tests to fix devnet 6 changes
* get ckzg working and fix some tests
* fix remaining tests
* fix lints
* Fix KZG linking issues
* remove unused dep
* lockfile
* test fixes
* remove dbgs
* remove unwrap
* cleanup tx generator
* small fixes
* fixing fixes
* more self reivew
* more self review
* refactor genesis header initialization
* refactor mock el instantiations
* fix compile
* fix network test, make sure they run for each fork
* pr feedback
* fix last test (hopefully)
---------
Co-authored-by: Pawan Dhananjay <pawandhananjay@gmail.com>
Co-authored-by: Mark Mackey <mark@sigmaprime.io>
Co-authored-by: Divma <26765164+divagant-martian@users.noreply.github.com>
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
## Issue Addressed
- #4293
- #4264
## Proposed Changes
*Changes largely follow those suggested in the main issue*.
- Add new routes to HTTP API
- `post_beacon_blocks_v2`
- `post_blinded_beacon_blocks_v2`
- Add new routes to `BeaconNodeHttpClient`
- `post_beacon_blocks_v2`
- `post_blinded_beacon_blocks_v2`
- Define new Eth2 common types
- `BroadcastValidation`, enum representing the level of validation to apply to blocks prior to broadcast
- `BroadcastValidationQuery`, the corresponding HTTP query string type for the above type
- ~~Define `_checked` variants of both `publish_block` and `publish_blinded_block` that enforce a validation level at a type level~~
- Add interactive tests to the `bn_http_api_tests` test target covering each validation level (to their own test module, `broadcast_validation_tests`)
- `beacon/blocks`
- `broadcast_validation=gossip`
- Invalid (400)
- Full Pass (200)
- Partial Pass (202)
- `broadcast_validation=consensus`
- Invalid (400)
- Only gossip (400)
- Only consensus pass (i.e., equivocates) (200)
- Full pass (200)
- `broadcast_validation=consensus_and_equivocation`
- Invalid (400)
- Invalid due to early equivocation (400)
- Only gossip (400)
- Only consensus (400)
- Pass (200)
- `beacon/blinded_blocks`
- `broadcast_validation=gossip`
- Invalid (400)
- Full Pass (200)
- Partial Pass (202)
- `broadcast_validation=consensus`
- Invalid (400)
- Only gossip (400)
- ~~Only consensus pass (i.e., equivocates) (200)~~
- Full pass (200)
- `broadcast_validation=consensus_and_equivocation`
- Invalid (400)
- Invalid due to early equivocation (400)
- Only gossip (400)
- Only consensus (400)
- Pass (200)
- Add a new trait, `IntoGossipVerifiedBlock`, which allows type-level guarantees to be made as to gossip validity
- Modify the structure of the `ObservedBlockProducers` cache from a `(slot, validator_index)` mapping to a `((slot, validator_index), block_root)` mapping
- Modify `ObservedBlockProducers::proposer_has_been_observed` to return a `SeenBlock` rather than a boolean on success
- Punish gossip peer (low) for submitting equivocating blocks
- Rename `BlockError::SlashablePublish` to `BlockError::SlashableProposal`
## Additional Info
This PR contains changes that directly modify how blocks are verified within the client. For more context, consult [comments in-thread](https://github.com/sigp/lighthouse/pull/4316#discussion_r1234724202).
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
* Get tests passing
* Get benchmarks compiling
* Fix EF withdrawals test
* Remove unused deps
* Fix tree_hash panic in tests
* Fix slasher compilation
* Fix ssz_generic test
* Get more tests passing
* Fix EF tests for real
* Fix local testnet scripts
## Issue Addressed
NA
## Proposed Changes
Implements the `PrettyReqwestError` to wrap a `reqwest::Error` and give nicer `Debug` formatting. It also wraps the `Url` component in a `SensitiveUrl` to avoid leaking sensitive info in logs.
### Before
```
Reqwest(reqwest::Error { kind: Request, url: Url { scheme: "http", cannot_be_a_base: false, username: "", password: None, host: Some(Domain("localhost")), port: Some(9999), path: "/eth/v1/node/version", query: None, fragment: None }, source: hyper::Error(Connect, ConnectError("tcp connect error", Os { code: 61, kind: ConnectionRefused, message: "Connection refused" })) })
```
### After
```
HttpClient(url: http://localhost:9999/, kind: request, detail: error trying to connect: tcp connect error: Connection refused (os error 61))
```
## Additional Info
I've also renamed the `Reqwest` error enum variants to `HttpClient`, to give people a better chance at knowing what's going on. Reqwest is pretty odd and looks like a typo.
I've implemented it in the `eth2` and `execution_layer` crates. This should affect most logs in the VC and EE-related ones in the BN.
I think the last crate that could benefit from the is the `beacon_node/eth1` crate. I haven't updated it in this PR since its error type is not so amenable to it (everything goes into a `String`). I don't have a whole lot of time to jig around with that at the moment and I feel that this PR as it stands is a significant enough improvement to merge on its own. Leaving it as-is is fine for the time being and we can always come back for it later (or implement in-protocol deposits!).
## Issue Addressed
Resolves#3238
## Proposed Changes
Please list or describe the changes introduced by this PR.
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
## Issue Addressed
This PR adds a new `lint-fix` task to automatically fix simple Clippy warnings using `cargo clippy --fix`.
Usage:
```
make lint-fix
```
## Issue Addressed
#4386
## Proposed Changes
The original proposal described in the issue adds a new endpoint to support updating validator graffiti, but I realized we already have an endpoint that we use for updating various validator fields in memory and in the validator definitions file, so I think that would be the best place to add this to.
### API endpoint
`PATCH lighthouse/validators/{validator_pubkey}`
This endpoint updates the graffiti in both the [ validator definition file](https://lighthouse-book.sigmaprime.io/graffiti.html#2-setting-the-graffiti-in-the-validator_definitionsyml) and the in memory `InitializedValidators`. In the next block proposal, the new graffiti will be used.
Note that the [`--graffiti-file`](https://lighthouse-book.sigmaprime.io/graffiti.html#1-using-the---graffiti-file-flag-on-the-validator-client) flag has a priority over the validator definitions file, so if the caller attempts to update the graffiti while the `--graffiti-file` flag is present, the endpoint will return an error (Bad request 400).
## Tasks
- [x] Add graffiti update support to `PATCH lighthouse/validators/{validator_pubkey}`
- [x] Return error if user tries to update graffiti while the `--graffiti-flag` is set
- [x] Update Lighthouse book
## Issue Addressed
NA
## Proposed Changes
Adds the `--validator-registration-batch-size` flag to the VC to allow runtime configuration of the number of validators POSTed to the [`validator/register_validator`](https://ethereum.github.io/beacon-APIs/?urls.primaryName=dev#/Validator/registerValidator) endpoint.
There are builders (Agnostic and Eden) that are timing out with `regsiterValidator` requests with ~400 validators, even with a 9 second timeout. Exposing the batch size will help tune batch sizes to (hopefully) avoid this.
This PR should not change the behavior of Lighthouse when the new flag is not provided (i.e., the same default value is used).
## Additional Info
NA
* Use "rebasing" to minimise BeaconState mem usage
* Update metastruct
* Use upstream milhouse, update cargo lock
* Rebase caches for extra memory savings
## Proposed Changes
Remove `max-skip-slots` checks when processing blocks.
This was legacy code which was previously used in the Medalla testnet to sync to the correct fork.
With the addition of checkpoint sync which allows us to sync to any arbitrary fork, this is no longer a necessary feature, so it has been removed for simplicity.
## Additional Notes
The CLI flag and checks for attestation processing have been retained as it still may have uses in DoS protection.
Currently, the ENR of the node may not be correctly updated when specifying ipv6 fields through the CLI if an ENR exists on disk.
This remedies a bug where we were not checking for ipv6 fields when comparing whether to use an on-disk ENR or updating based on CLI configuration parameters.
This is only a minor correction to the table not properly showing up in Lighthouse book. The changes solves the formatting issue. Another change is on the link to do port-forwarding.
## Issue Addressed
Closes#4332
## Proposed Changes
Remove the `CountUnrealized` type, defaulting unrealized justification to _on_. This fixes the #4332 issue by ensuring that importing the same block to fork choice always results in the same outcome.
Finalized sync speed may be slightly impacted by this change, but that is deemed an acceptable trade-off until the optimisation from #4118 is implemented.
TODO:
- [x] Also check that the block isn't a duplicate before importing
* some blob reprocessing work
* remove ForceBlockLookup
* reorder enum match arms in sync manager
* a lot more reprocessing work
* impl logic for triggerng blob lookups along with block lookups
* deal with rpc blobs in groups per block in the da checker. don't cache missing blob ids in the da checker.
* make single block lookup generic
* more work
* add delayed processing logic and combine some requests
* start fixing some compile errors
* fix compilation in main block lookup mod
* much work
* get things compiling
* parent blob lookups
* fix compile
* revert red/stevie changes
* fix up sync manager delay message logic
* add peer usefulness enum
* should remove lookup refactor
* consolidate retry error handling
* improve peer scoring during certain failures in parent lookups
* improve retry code
* drop parent lookup if either req has a peer disconnect during download
* refactor single block processed method
* processing peer refactor
* smol bugfix
* fix some todos
* fix lints
* fix lints
* fix compile in lookup tests
* fix lints
* fix lints
* fix existing block lookup tests
* renamings
* fix after merge
* cargo fmt
* compilation fix in beacon chain tests
* fix
* refactor lookup tests to work with multiple forks and response types
* make tests into macros
* wrap availability check error
* fix compile after merge
* add random blobs
* start fixing up lookup verify error handling
* some bug fixes and the start of deneb only tests
* make tests work for all forks
* track information about peer source
* error refactoring
* improve peer scoring
* fix test compilation
* make sure blobs are sent for processing after stream termination, delete copied tests
* add some tests and fix a bug
* smol bugfixes and moar tests
* add tests and fix some things
* compile after merge
* lots of refactoring
* retry on invalid block/blob
* merge unknown parent messages before current slot lookup
* get tests compiling
* penalize blob peer on invalid blobs
* Check disk on in-memory cache miss
* Update beacon_node/beacon_chain/src/data_availability_checker/overflow_lru_cache.rs
* Update beacon_node/network/src/sync/network_context.rs
Co-authored-by: Divma <26765164+divagant-martian@users.noreply.github.com>
* fix bug in matching blocks and blobs in range sync
* pr feedback
* fix conflicts
* upgrade logs from warn to crit when we receive incorrect response in range
* synced_and_connected_within_tolerance -> should_search_for_block
* remove todo
* Fix Broken Overflow Tests
* fix merge conflicts
* checkpoint sync without alignment
* add import
* query for checkpoint state by slot rather than state root (teku doesn't serve by state root)
* get state first and query by most recent block root
* simplify delay logic
* rename unknown parent sync message variants
* rename parameter, block_slot -> slot
* add some docs to the lookup module
* use interval instead of sleep
* drop request if blocks and blobs requests both return `None` for `Id`
* clean up `find_single_lookup` logic
* add lookup source enum
* clean up `find_single_lookup` logic
* add docs to find_single_lookup_request
* move LookupSource our of param where unnecessary
* remove unnecessary todo
* query for block by `state.latest_block_header.slot`
* fix lint
* fix test
* fix test
* fix observed blob sidecars test
* PR updates
* use optional params instead of a closure
* create lookup and trigger request in separate method calls
* remove `LookupSource`
* make sure duplicate lookups are not dropped
---------
Co-authored-by: Pawan Dhananjay <pawandhananjay@gmail.com>
Co-authored-by: Mark Mackey <mark@sigmaprime.io>
Co-authored-by: Divma <26765164+divagant-martian@users.noreply.github.com>
Checkpointz now supports deposit snapshot but [they only support returning them in JSON](https://github.com/ethpandaops/checkpointz/issues/74) so I've modified lighthouse to request them in JSON by default.
There's also `get_opt` & `get_opt_with_timeout` methods which seem to expect responses in JSON but were not adding `Accept: application/json` to the request headers so I fixed that as well.
Also the beacon API puts quantities in quotes so I fixed that in the snapshot JSON serialization
## Issue Addressed
Closes#3964
## Proposed Changes
Use the `maxperf` profile to build Windows binaries, now that Rust 1.70.0 fixed the underlying issue.
## Proposed Changes
Correct some typos in the book, also update information about withdrawals since the Mainnet will be having 700K validators in about a month
## Issue Addressed
#3510
## Proposed Changes
- Replace mime with MediaTypeList
- Remove parse_accept fn as MediaTypeList does it built-in
- Get the supported media type of the highest q-factor in a single list iteration without sorting
## Additional Info
I have addressed the suggested changes in previous [PR](https://github.com/sigp/lighthouse/pull/3520#discussion_r959048633)
Done in different PRs so that they can reviewed independently, as it's likely this won't be merged before I leave
Includes resolution for #4080
- [ ] #4299
- [ ] #4318
- [ ] #4320
Co-authored-by: Diva M <divma@protonmail.com>
Co-authored-by: Age Manning <Age@AgeManning.com>
## Issue Addressed
This PR addresses issue https://github.com/sigp/lighthouse/issues/4350
## Proposed Changes
This change will enable slasher broadcast in the following cases:
No flag is passed,
`--slasher-broadcast` is passed and,
`--slasher-broadcast=true` is passed.
Only when an explicit false value is passed the slasher does not broadcast.(`--slasher-broadcast=false`).
## Additional Info
TODO
- [x] Modify CLI parsing logic
- [x] Write test
Refer to #4353
Co-authored-by: Rahul Dogra <rahulcooldogra@gmail.com>
Co-authored-by: Gua00va <105484243+Gua00va@users.noreply.github.com>
## Issue Addressed
Workaround for https://github.com/foundry-rs/foundry/issues/5115.
## Proposed Changes
Allow Anvil to be installed on Windows without errors by enabling the IPC features (which we don't use, but Anvil expects to exist).
## Issue Addressed
NA
## Proposed Changes
Downgrade a `CRIT` to an `ERRO` when there's an `Irrecoverable` error whilst publishing a blinded block.
It's quite common for builders successfully broadcast a block to the network whilst failing to respond to the BN when it publishes a signed, blinded block. The VC is currently raising a `CRIT` when this happens and I think that's excessive.
These changes have the same intent as #4073. In that PR I only managed to remove the `CRIT`s in the BN but missed this one in the VC.
I've also tidied the log messages to:
- Give them all the same title (*"Error whilst producing block"*) to help with grepping.
- Include the `block_slot` so it's easy to look up the slot in an explorer and see if it was actually skipped.
## Additional Info
This PR should not change any logic beyond logging.
## Issue Addressed
Closes#4354Closes#3987
Replaces #4305, #4283
## Proposed Changes
This switches the default slasher backend _back_ to LMDB.
If an MDBX database exists and the MDBX backend is enabled then MDBX will continue to be used. Our release binaries and Docker images will continue to include MDBX for as long as it is practical, so users of these should not notice any difference.
The main benefit is to users compiling from source and devs running tests. These users no longer have to struggle to compile MDBX and deal with the compatibility issues that arises. Similarly, devs don't need to worry about toggling feature flags in tests or risk forgetting to run the slasher tests due to backend issues.
## Issue Addressed
N/A
## Proposed Changes
This change will log the value of the relay block and the local block when the relay block is more profitable.
## Additional Info
This change will help validators understand the block selection (as it looks like the execution reward sometimes is higher that the MEV-reward).
The rationale for this change is to aid operators to better understand why a relay-block was chosen over a local block.
Looking at produced blocks (at beaconcha.in for example) it sometimes looks like the builder is making a profit just from the execution reward vs the MEV-reward, and creates the nagging question: "Could i have built this block and made that extra profit?"... The answer is probably "No, not without the extra transactions included by the relay", but by logging the value of the local block-candidate, this will no longer be an issue..
### Example (Mainnet)
https://beaconcha.in/block/17370329
MEV Block Reward: 0.17122 Ether to 0xE35bBaFa0266089f95d745d348b468622805D82B
Execution Reward: 0.17528 Ether to 0x1f9090aaE28b8a3dCeaDf281B0F12828e676c326
Difference: 0.00406 Ether
### Examples (Goerli)
https://goerli.beaconcha.in/block/9040065
MEV Block Reward: 0.56423 Ether to 0xF5794543CF6055Ae710E9c8E99E31343Cea004a8
Execution Reward: 0.56488 Ether to 0xfC0157aA4F5DB7177830ACddB3D5a9BB5BE9cc5e
Difference: 0.00065 Ether
https://goerli.beaconcha.in/block/9019921
MEV Block Reward: 1.39440 Ether to 0xF5794543CF6055Ae710E9c8E99E31343Cea004a8
Execution Reward: 1.39469 Ether to 0xfC0157aA4F5DB7177830ACddB3D5a9BB5BE9cc5e
Difference: 0.00029 Ether
https://goerli.beaconcha.in/block/9015583
MEV Block Reward: 1.04356 Ether to 0xF5794543CF6055Ae710E9c8E99E31343Cea004a8
Execution Reward: 1.04896 Ether to 0xfC0157aA4F5DB7177830ACddB3D5a9BB5BE9cc5e
Difference: 0.0054 Ether
## Issue Addressed
On deneb devnetv5, lighthouse keeps rate limiting peers which makes it harder to bootstrap new nodes as there are very few peers in the network. This PR adds an option to disable the inbound rate limiter for testnets.
Added an option to configure inbound rate limits as well.
Co-authored-by: Diva M <divma@protonmail.com>
## Proposed Changes
This is a light refactor of the execution layer's block hash calculation logic making it easier to use externally. e.g. in `eleel` (https://github.com/sigp/eleel/pull/18).
A static method is preferable to a method because the calculation doesn't actually need any data from `self`, and callers may want to compute block hashes without constructing an `ExecutionLayer` (`eleel` only constructs a simpler `Engine` struct).
## Issue Addressed
Update Information in Lighthouse Book
## Proposed Changes
- move Validator Graffiti from Advanced Usage to Validator Management
- update API response and command
- some items that aren't too sure I put it in comment, which can be seen in raw/review format but not live
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
Co-authored-by: chonghe <44791194+chong-he@users.noreply.github.com>
## Issue Addressed
Added some frequently asked questions in the Lighthouse Book
## Proposed Changes
Created another file faqV2.md which categorises the FAQs into different sections for better organisation. For review purpose, a review on faq.md will suffice. Then, if faqV2.md looks better, can delete faq.md; otherwise if the changes to the faqV2.md is too much, can keep faq.md and delete faqv2.md.
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
Co-authored-by: chonghe <44791194+chong-he@users.noreply.github.com>
## Issue Addressed
-
## Proposed Changes
Add information to use SSH to connect to Siren beyond the local computer
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
Co-authored-by: chonghe <44791194+chong-he@users.noreply.github.com>
Co-authored-by: Michael Sproul <micsproul@gmail.com>
This PR address the following spec change: https://github.com/ethereum/consensus-specs/pull/3312
Instead of subscribing to a long-lived subnet for every attached validator to a beacon node, all beacon nodes will subscribe to `SUBNETS_PER_NODE` long-lived subnets. This is currently set to 2 for mainnet.
This PR does not include any scoring or advanced discovery mechanisms. A future PR will improve discovery and we can implement scoring after the next hard fork when we expect all client teams and all implementations to respect this spec change.
This will be a significant change in the subnet network structure for consensus clients and we will likely have to monitor and tweak our peer management logic.
## Issue Addressed
Realized this was missing while discussing #4280
## Proposed Changes
Add an Item to the list of additional requirements for developers.
## Issue Addressed
N/A
## Proposed Changes
Geth's latest release breaks our CI with the following message
```
Fatal: Failed to register the Ethereum service: ethash is only supported as a historical component of already merged networks
Shutting down
```
Latest geth version has removed support for PoW networks. Hence, we need to add an extra `terminalTotalDifficultyPassed ` parameter in the genesis config to start from a merged network.
## Issue Addressed
Add a new `--output values` option to `db inspect` for dumping raw database values to SSZ files.
This could be useful for inspecting the database when we're unable to start the beacon node.
Example usage:
```
# Output the `ForkChoice` column to an SSZ file
lighthouse db inspect --column frk --output values
```
By default, it stores the output files in the current directory, and can be overriden with `--ouput-dir`.
List of columns can be found here:
c547a11b0d/beacon_node/store/src/lib.rs (L169-L216)
## Issue Addressed
None
## Proposed Changes
Tiny change to the documentation: Bellatrix happened for Gnosis so also needs a merge-ready config.
## Additional Info
None
This PR adds the ability to read the Lighthouse logs from the HTTP API for both the BN and the VC.
This is done in such a way to as minimize any kind of performance hit by adding this feature.
The current design creates a tokio broadcast channel and mixes is into a form of slog drain that combines with our main global logger drain, only if the http api is enabled.
The drain gets the logs, checks the log level and drops them if they are below INFO. If they are INFO or higher, it sends them via a broadcast channel only if there are users subscribed to the HTTP API channel. If not, it drops the logs.
If there are more than one subscriber, the channel clones the log records and converts them to json in their independent HTTP API tasks.
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Issue Addressed
https://github.com/sigp/lighthouse/pull/4309#issuecomment-1556052261
## Proposed Changes
Log the `Connected to beacon node` message only if the node was previously offline. This avoids a regression in logging after #4295, whereby the `Connected to beacon node` message would be logged every slot.
The new reduced logging is _slightly different_ from what we had prior to my changes in #4295. The main difference is that we used to log the `Connected` message whenever a node was online and subject to a health check (for being unhealthy in some other way). I think the new behaviour is reasonable, as the `Connected` message isn't particularly helpful if the BN is unhealthy, and the specific reason for unhealthiness will be logged by the warnings for `is_compatible`/`is_synced`.
## Issue Addressed
N/A
## Proposed Changes
Gnosis preset values have been updated from previous placeholder values. This changes are required for chiado since it inherits the preset from gnosis mainnet.
- preset values update PR ref: https://github.com/gnosischain/configs/pull/11
## Additional Info
N/A
## Issue Addressed
NA
## Proposed Changes
Adds metrics to track validators that are submitting equivocating (but not slashable) sync messages. This follows on from some research we've been doing in a separate fork of LH.
## Additional Info
@jimmygchen and @michaelsproul have already run their eyes over this so it should be easy to get into v4.2.0, IMO.
## Issue Addressed
#4281
## Proposed Changes
- Change `ShufflingCache` implementation from using `LruCache` to a custom cache that removes entry with lowest epoch instead of oldest insertion time.
- Protect the "enshrined" head shufflings when inserting new committee cache entries. The shuffling ids matching the head's previous, current, and future epochs will never be ejected from the cache during `Self::insert_cache_item`.
## Additional Info
There is a bonus point on shuffling preferences in the issue description that hasn't been implemented yet, as I haven't figured out a good way to do this:
> However I'm not convinced since there are some complexities around tie-breaking when two entries have the same epoch. Perhaps preferring entries in the canonical chain is best?
We should be able to check if a block is on the canonical chain by:
```rust
canonical_head
.fork_choice_read_lock()
.contains_block(root)
```
However we need to interleave the shuffling and fork choice locks, which may cause deadlocks if we're not careful (mentioned by @paulhauner). Alternatively, we could use the `state.block_roots` field of the `chain.canonical_head.snapshot.beacon_state`, which avoids deadlock but requires more work.
I'd like to get some feedback on review & testing before I dig deeper into the preferences stuff, as having the canonical head preference may already be quite useful in preventing the issue raised.
Co-authored-by: Jimmy Chen <jimmy@sigmaprime.io>
## Issue Addressed
Closes https://github.com/sigp/lighthouse/issues/4291, part of #3613.
## Proposed Changes
- Implement the `el_offline` field on `/eth/v1/node/syncing`. We set `el_offline=true` if:
- The EL's internal status is `Offline` or `AuthFailed`, _or_
- The most recent call to `newPayload` resulted in an error (more on this in a moment).
- Use the `el_offline` field in the VC to mark nodes with offline ELs as _unsynced_. These nodes will still be used, but only after synced nodes.
- Overhaul the usage of `RequireSynced` so that `::No` is used almost everywhere. The `--allow-unsynced` flag was broken and had the opposite effect to intended, so it has been deprecated.
- Add tests for the EL being offline on the upcheck call, and being offline due to the newPayload check.
## Why track `newPayload` errors?
Tracking the EL's online/offline status is too coarse-grained to be useful in practice, because:
- If the EL is timing out to some calls, it's unlikely to timeout on the `upcheck` call, which is _just_ `eth_syncing`. Every failed call is followed by an upcheck [here](693886b941/beacon_node/execution_layer/src/engines.rs (L372-L380)), which would have the effect of masking the failure and keeping the status _online_.
- The `newPayload` call is the most likely to time out. It's the call in which ELs tend to do most of their work (often 1-2 seconds), with `forkchoiceUpdated` usually returning much faster (<50ms).
- If `newPayload` is failing consistently (e.g. timing out) then this is a good indication that either the node's EL is in trouble, or the network as a whole is. In the first case validator clients _should_ prefer other BNs if they have one available. In the second case, all of their BNs will likely report `el_offline` and they'll just have to proceed with trying to use them.
## Additional Changes
- Add utility method `ForkName::latest` which is quite convenient for test writing, but probably other things too.
- Delete some stale comments from when we used to support multiple execution nodes.
## Issue Addressed
N/A
## Proposed Changes
Modifies the local testnet scripts to start a network with genesis validators embedded into the genesis state. This allows us to start a local testnet without the need for deploying a deposit contract or depositing validators pre-genesis.
This also enables us to start a local test network at any fork we want without going through fork transitions. Also adds scripts to start multiple geth clients and peer them with each other and peer the geth clients with beacon nodes to start a post merge local testnet.
## Additional info
Adds a new lcli command `mnemonics-validators` that generates validator directories derived from a given mnemonic.
Adds a new `derived-genesis-state` option to the `lcli new-testnet` command to generate a genesis state populated with validators derived from a mnemonic.
## Issue Addressed
#2335
## Proposed Changes
- Remove the `lighthouse-network::tests::gossipsub_tests` module
- Remove dead code from the `lighthouse-network::tests::common` helper module (`build_full_mesh`)
## Additional Info
After discussion with both @divagant-martian and @AgeManning, these tests seem to have two main issues in that they are:
- Redundant, in that they don't test anything meaningful (due to our handling of duplicate messages)
- Out-of-place, in that it doesn't really test Lighthouse-specific functionality (rather libp2p functionality)
As such, this PR supersedes #4286.
## Issue Addressed
NA
## Proposed Changes
Adds an additional check to a feature introduced in #4179 to prevent us from re-queuing already-known blocks that could be rejected immediately.
## Additional Info
Ideally this would have been included in v4.1.0, however we came across it too late to release it safely. We decided that the safest path forward is to release *without* this check and then patch it in the next version. The lack of this check should only result in a very minor performance impact (the impact is totally negligible in my assessment).
## Issue Addressed
NA
## Proposed Changes
Adds a flag to store invalid blocks on disk for teh debugz. Only *some* invalid blocks are stored, those which:
- Were received via gossip (rather than RPC, for instance)
- This keeps things simple to start with and should capture most blocks.
- Passed gossip verification
- This reduces the ability for random people to fill up our disk. A proposer signature is required to write something to disk.
## Additional Info
It's possible that we'll store blocks that aren't necessarily invalid, but we had an internal error during verification. Those blocks seem like they might be useful sometimes.
## Issue Addressed
N/A
## Proposed Changes
Replace ganache-cli with anvil https://github.com/foundry-rs/foundry/blob/master/anvil/README.md
We can lose all js dependencies in CI as a consequence.
## Additional info
Also changes the ethers-rs version used in the execution layer (for the transaction reconstruction) to a newer one. This was necessary to get use the ethers utils for anvil. The fixed execution engine integration tests should catch any potential issues with the payload reconstruction after #3592
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
## Issue Addressed
#4233
## Proposed Changes
Remove the `best_justified_checkpoint` from the `PersistedForkChoiceStore` type as it is now unused.
Additionally, remove the `Option`'s wrapping the `justified_checkpoint` and `finalized_checkpoint` fields on `ProtoNode` which were only present to facilitate a previous migration.
Include the necessary code to facilitate the migration to a new DB schema.
## Issue Addressed
Addresses #4238
## Proposed Changes
- [x] Add tests for the scenarios
- [x] Use the fork of the attestation slot for signature verification.
## Issue Addressed
Update some broken links in Lighthouse Book
## Proposed Changes
The updated links correctly link to the section of the book
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
## Issue Addressed
Addresses #4234
## Proposed Changes
- Skip withdrawals processing in an inconsistent state replay.
- Repurpose `StateRootStrategy`: rename to `StateProcessingStrategy` and always skip withdrawals if using `StateProcessingStrategy::Inconsistent`
- Add a test to reproduce the scenario
Co-authored-by: Jimmy Chen <jimmy@sigmaprime.io>
## Issue Addressed
#4266
## Proposed Changes
- Log `Using external block builder` instead of `Connected to external block builder` on its initialization to resolve the confusion (there's no actual connection there)
## Additional Info
The log is mentioned in builders docs, so it's changed there too.
This commit adds a check to the networking service when handling core gossipsub topic subscription requests. If the BN is already subscribed to the core topics, we won't attempt to resubscribe.
## Issue Addressed
#4258
## Proposed Changes
- In the networking service, check if we're already subscribed to all of the core gossipsub topics and, if so, do nothing
## Additional Info
N/A
## Limit Backfill Sync
This PR transitions Lighthouse from syncing all the way back to genesis to only syncing back to the weak subjectivity point (~ 5 months) when syncing via a checkpoint sync.
There are a number of important points to note with this PR:
- Firstly and most importantly, this PR fundamentally shifts the default security guarantees of checkpoint syncing in Lighthouse. Prior to this PR, Lighthouse could verify the checkpoint of any given chain by ensuring the chain eventually terminates at the corresponding genesis. This guarantee can still be employed via the new CLI flag --genesis-backfill which will prompt lighthouse to the old behaviour of downloading all blocks back to genesis. The new behaviour only checks the proposer signatures for the last 5 months of blocks but cannot guarantee the chain matches the genesis chain.
- I have not modified any of the peer scoring or RPC responses. Clients syncing from gensis, will downscore new Lighthouse peers that do not possess blocks prior to the WSP. This is by design, as Lighthouse nodes of this form, need a mechanism to sort through peers in order to find useful peers in order to complete their genesis sync. We therefore do not discriminate between empty/error responses for blocks prior or post the local WSP. If we request a block that a peer does not posses, then fundamentally that peer is less useful to us than other peers.
- This will make a radical shift in that the majority of nodes will no longer store the full history of the chain. In the future we could add a pruning mechanism to remove old blocks from the db also.
Co-authored-by: Paul Hauner <paul@paulhauner.com>
## Issue Addressed
#3873
## Proposed Changes
add a cache to optimise historical state lookup.
## Additional Info
N/A
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Issue Addressed
Update Lighthouse book to include latest information especially after Capella upgrade
## Proposed Changes
Notable changes:
- Combine Sec 4.1 & 6.1 into Sec 4, because Sec 6.1 is importing validator key which is a required step when want to run a validator
- Combine Sec 5.1 & 5.2 with Sec 5, and move Sec 5 to under Sec 9
- Added partial withdrawals in Sec 6
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
Co-authored-by: chonghe <tanck2005@gmail.com>
## Issue Addressed
This PR un-deprecates some commonly used test util functions, e.g. `extend_chain`. Most of these were deprecated in 2020 but some of us still found them quite convenient and they're still being used a lot. If there's no issue with using them, I think we should remove the "Deprecated" comment to avoid confusion.
## Proposed Changes
- Allow Docker images to be built with different profiles via e.g. `--build-arg PROFILE=maxperf`.
- Include the build profile in `lighthouse --version`.
## Additional Info
This only affects Docker images built from source. Our published Docker images use `cross`-compiled binaries that get copied into place.
## Issue Addressed
#4150
## Proposed Changes
Maintain trusted peers in the pruning logic. ~~In principle the changes here are not necessary as a trusted peer has a max score (100) and all other peers can have at most 0 (because we don't implement positive scores). This means that we should never prune trusted peers unless we have more trusted peers than the target peer count.~~
This change shifts this logic to explicitly never prune trusted peers which I expect is the intuitive behaviour.
~~I suspect the issue in #4150 arises when a trusted peer disconnects from us for one reason or another and then we remove that peer from our peerdb as it becomes stale. When it re-connects at some large time later, it is no longer a trusted peer.~~
Currently we do disconnect trusted peers, and this PR corrects this to maintain trusted peers in the pruning logic.
As suggested in #4150 we maintain trusted peers in the db and thus we remember them even if they disconnect from us.
## Issue Addressed
[#4162](https://github.com/sigp/lighthouse/issues/4162)
## Proposed Changes
update `--logfile-no-restricted-perms` flag help text to indicate that, for Windows users, the file permissions are inherited from the parent folder
## Additional Info
N/A
## Proposed Changes
Added page explanation for authentication under Siren UI book.
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
* Update Engine API to Latest
* Get Mock EE Working
* Fix Mock EE
* Update Engine API Again
* Rip out get_blobs_bundle Stuff
* Fix Test Harness
* Fix Clippy Complaints
* Fix Beacon Chain Tests
* Temp hack to compile
* Fix doppelganger tests
* Kill in groups instead of storing pid
* Install geth in CI
* Install geth first
* Fix eth1_block_hash
* Fix directory paths and block hash
* Fix workflow for local testnets; reset genesis.json after running script
* Disable capella and deneb forks for doppelganger tests
* oops not capella
* Spin up a spare bn for the doppelganger validator
* testing
* Revert "testing"
This reverts commit 14eb178bca.
* Modify beacon_node script to take trusted peers
* Set doppelganger bn as a trusted peer
* Update var
* update another
* Fix port
* Add a flag to disable peer scoring
* Disable peer scoring in local testnet bn script
* Revert trusted peers hack
* fmt
* Fix proposer boost score
It is a well-known fact that IP addresses for beacon nodes used by specific validators can be de-anonymized. There is an assumed risk that a malicious user may attempt to DOS validators when producing blocks to prevent chain growth/liveness.
Although there are a number of ideas put forward to address this, there a few simple approaches we can take to mitigate this risk.
Currently, a Lighthouse user is able to set a number of beacon-nodes that their validator client can connect to. If one beacon node is taken offline, it can fallback to another. Different beacon nodes can use VPNs or rotate IPs in order to mask their IPs.
This PR provides an additional setup option which further mitigates attacks of this kind.
This PR introduces a CLI flag --proposer-only to the beacon node. Setting this flag will configure the beacon node to run with minimal peers and crucially will not subscribe to subnets or sync committees. Therefore nodes of this kind should not be identified as nodes connected to validators of any kind.
It also introduces a CLI flag --proposer-nodes to the validator client. Users can then provide a number of beacon nodes (which may or may not run the --proposer-only flag) that the Validator client will use for block production and propagation only. If these nodes fail, the validator client will fallback to the default list of beacon nodes.
Users are then able to set up a number of beacon nodes dedicated to block proposals (which are unlikely to be identified as validator nodes) and point their validator clients to produce blocks on these nodes and attest on other beacon nodes. An attack attempting to prevent liveness on the eth2 network would then need to preemptively find and attack the proposer nodes which is significantly more difficult than the default setup.
This is a follow on from: #3328
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
Co-authored-by: Paul Hauner <paul@paulhauner.com>
## Issue Addressed
The latest stable version (1.69.0) of Rust was released on 20 April and contains this change:
- [Update the minimum external LLVM to 14.](https://github.com/rust-lang/rust/pull/107573/)
This impacts some of our CI workflows (build and release-test-windows) that uses LLVM 13.0. This PR updates the workflows to install LLVM 15.0.
**UPDATE**: Also updated `h2` to address [this issue](https://github.com/advisories/GHSA-f8vr-r385-rh5r)
## Issue Addressed
NA
## Proposed Changes
Avoids reprocessing loops introduced in #4179. (Also somewhat related to #4192).
Breaks the re-queue loop by only re-queuing when an RPC block is received before the attestation creation deadline.
I've put `proposal_is_known` behind a closure to avoid interacting with the `observed_proposers` lock unnecessarily.
## Additional Info
NA
## Issue Addressed
There was a [`VecDeque` bug](https://github.com/rust-lang/rust/issues/108453) in some recent versions of the Rust standard library (1.67.0 & 1.67.1) that could cause Lighthouse to panic (reported by `@Sea Monkey` on discord). See full logs below.
The issue was likely introduced in Rust 1.67.0 and [fixed](https://github.com/rust-lang/rust/pull/108475) in 1.68, and we were able to reproduce the panic ourselves using [@michaelsproul's fuzz tests](https://github.com/michaelsproul/lighthouse/blob/fuzz-lru-time-cache/beacon_node/lighthouse_network/src/peer_manager/fuzz.rs#L111) on both Rust 1.67.0 and 1.67.1.
Users that uses our Docker images or binaries are unlikely affected, as our Docker images were built with `1.66`, and latest binaries were built with latest stable (`1.68.2`). It likely impacts user that builds from source using Rust versions 1.67.x.
## Proposed Changes
Bump Rust version (MSRV) to latest stable `1.68.2`.
## Additional Info
From `@Sea Monkey` on Lighthouse Discord:
> Crash on goerli using `unstable` `dd124b2d6804d02e4e221f29387a56775acccd08`
```
thread 'tokio-runtime-worker' panicked at 'Key must exist', /mnt/goerli/goerli/lighthouse/common/lru_cache/src/time.rs:68:28
stack backtrace:
Apr 15 09:37:36.993 WARN Peer sent invalid block in single block lookup, peer_id: 16Uiu2HAm6ZuyJpVpR6y51X4Enbp8EhRBqGycQsDMPX7e5XfPYznG, error: WouldRevertFinalizedSlot { block_slot: Slot(5420212), finalized_slot: Slot(5420224) }, root: 0x10f6…3165, service: sync
0: rust_begin_unwind
at /rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/std/src/panicking.rs:575:5
1: core::panicking::panic_fmt
at /rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/core/src/panicking.rs:64:14
2: core::panicking::panic_display
at /rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/core/src/panicking.rs:135:5
3: core::panicking::panic_str
at /rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/core/src/panicking.rs:119:5
4: core::option::expect_failed
at /rustc/d5a82bbd26e1ad8b7401f6a718a9c57c96905483/library/core/src/option.rs:1879:5
5: lru_cache::time::LRUTimeCache<Key>::raw_remove
6: lighthouse_network::peer_manager::PeerManager<TSpec>::handle_ban_operation
7: lighthouse_network::peer_manager::PeerManager<TSpec>::handle_score_action
8: lighthouse_network::peer_manager::PeerManager<TSpec>::report_peer
9: network::service::NetworkService<T>::spawn_service::{{closure}}
10: <futures_util::future::select::Select<A,B> as core::future::future::Future>::poll
11: <futures_util::future::future::map::Map<Fut,F> as core::future::future::Future>::poll
12: <futures_util::future::future::flatten::Flatten<Fut,<Fut as core::future::future::Future>::Output> as core::future::future::Future>::poll
13: tokio::loom::std::unsafe_cell::UnsafeCell<T>::with_mut
14: tokio::runtime::task::core::Core<T,S>::poll
15: tokio::runtime::task::harness::Harness<T,S>::poll
16: tokio::runtime::scheduler::multi_thread::worker::Context::run_task
17: tokio::runtime::scheduler::multi_thread::worker::Context::run
18: tokio::macros::scoped_tls::ScopedKey<T>::set
19: tokio::runtime::scheduler::multi_thread::worker::run
20: tokio::loom::std::unsafe_cell::UnsafeCell<T>::with_mut
21: tokio::runtime::task::core::Core<T,S>::poll
22: tokio::runtime::task::harness::Harness<T,S>::poll
23: tokio::runtime::blocking::pool::Inner::run
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
Apr 15 09:37:37.069 INFO Saved DHT state service: network
Apr 15 09:37:37.070 INFO Network service shutdown service: network
Apr 15 09:37:37.132 CRIT Task panic. This is a bug! advice: Please check above for a backtrace and notify the developers, message: <none>, task_name: network
Apr 15 09:37:37.132 INFO Internal shutdown received reason: Panic (fatal error)
Apr 15 09:37:37.133 INFO Shutting down.. reason: Failure("Panic (fatal error)")
Apr 15 09:37:37.135 WARN Unable to free worker error: channel closed, msg: did not free worker, shutdown may be underway
Apr 15 09:37:39.350 INFO Saved beacon chain to disk service: beacon
Panic (fatal error)
```
## Issue Addressed
Closes#4185
## Proposed Changes
- Set user agent to `Lighthouse/vX.Y.Z-<commit hash>` by default
- Allow tweaking user agent via `--builder-user-agent "agent"`
## Proposed Changes
Builds on #4028 to use the new payload bodies methods in the HTTP API as well.
## Caveats
The payloads by range method only works for the finalized chain, so it can't be used in the execution engine integration tests because we try to reconstruct unfinalized payloads there.
## Issue Addressed
NA
## Proposed Changes
Apply two changes to code introduced in #4179:
1. Remove the `ERRO` log for when we error on `proposer_has_been_observed()`. We were seeing a lot of this in our logs for finalized blocks and it's a bit noisy.
1. Use `false` rather than `true` for `proposal_already_known` when there is an error. If a block raises an error in `proposer_has_been_observed()` then the block must be invalid, so we should process (and reject) it now rather than queuing it.
For reference, here is one of the offending `ERRO` logs:
```
ERRO Failed to check observed proposers block_root: 0x5845…878e, source: rpc, error: FinalizedBlock { slot: Slot(5410983), finalized_slot: Slot(5411232) }
```
## Additional Info
NA
## Issue Addressed
NA
## Proposed Changes
Similar to #4181 but without the version bump and a more nuanced fix.
Patches the high CPU usage seen after the Capella fork which was caused by processing exits when there are skip slots.
## Additional Info
~~This is an imperfect solution that will cause us to drop some exits at the fork boundary. This is tracked at #4184.~~
## Issue Addressed
Updated Lighthouse book on Section 2 and added some FAQs
## Proposed Changes
All changes are made in the book/src .md files.
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
Co-authored-by: chonghe <tanck2005@gmail.com>
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Proposed Changes
We already make some attempts to avoid processing RPC blocks when a block from the same proposer is already being processed through gossip. This PR strengthens that guarantee by using the existing cache for `observed_block_producers` to inform whether an RPC block's processing should be delayed.
## Proposed Changes
This change attempts to prevent failed re-orgs by:
1. Lowering the re-org cutoff from 2s to 1s. This is informed by a failed re-org attempted by @yorickdowne's node. The failed block was requested in the 1.5-2s window due to a Vouch failure, and failed to propagate to the majority of the network before the attestation deadline at 4s.
2. Allow users to adjust their re-org cutoff depending on observed network conditions and their risk profile. The static 2 second cutoff was too rigid.
3. Add a `--proposer-reorg-disallowed-offsets` flag which can be used to prohibit reorgs at certain slots. This is intended to help workaround an issue whereby reorging blocks at slot 1 are currently taking ~1.6s to propagate on gossip rather than ~500ms. This is suspected to be due to a cache miss in current versions of Prysm, which should be fixed in their next release.
## Additional Info
I'm of two minds about removing the `shuffling_stable` check which checks for blocks at slot 0 in the epoch. If we removed it users would be able to configure Lighthouse to try reorging at slot 0, which likely wouldn't work very well due to interactions with the proposer index cache. I think we could leave it for now and revisit it later.
## Issue Addressed
#4146
## Proposed Changes
Removes the `ExecutionOptimisticForkVersionedResponse` type and the associated Beacon API endpoint which is now deprecated. Also removes the test associated with the endpoint.
## Issue Addressed
N/A
## Proposed Changes
Adds a flag for disabling peer scoring. This is useful for local testing and testing small networks for new features.
## Issue Addressed
Attempt to fix#3812
## Proposed Changes
Move web3signer binary download script out of build script to avoid downloading unless necessary. If this works, it should also reduce the build time for all jobs that runs compilation.
> This is currently a WIP and all features are subject to alteration or removal at any time.
## Overview
The successor to #2873.
Contains the backbone of `beacon.watch` including syncing code, the initial API, and several core database tables.
See `watch/README.md` for more information, requirements and usage.
It is possible that when we go to ban a peer, there is already an unbanned message in the queue. It could lead to the case that we ban and immediately unban a peer leaving us in a state where a should-be banned peer is unbanned.
If this banned peer connects to us in this faulty state, we currently do not attempt to re-ban it. This PR does correct this also, so if we do see this error, it will now self-correct (although we shouldn't see the error in the first place).
I have also incremented the severity of not supporting protocols as I see peers ultimately get banned in a few steps and it seems to make sense to just ban them outright, rather than have them linger.
## Issue Addressed
Addresses #4117
## Proposed Changes
See https://github.com/ethereum/keymanager-APIs/pull/58 for proposed API specification.
## TODO
- [x] ~~Add submission to BN~~
- removed, see discussion in [keymanager API](https://github.com/ethereum/keymanager-APIs/pull/58)
- [x] ~~Add flag to allow voluntary exit via the API~~
- no longer needed now the VC doesn't submit exit directly
- [x] ~~Additional verification / checks, e.g. if validator on same network as BN~~
- to be done on client side
- [x] ~~Potentially wait for the message to propagate and return some exit information in the response~~
- not required
- [x] Update http tests
- [x] ~~Update lighthouse book~~
- not required if this endpoint makes it to the standard keymanager API
Co-authored-by: Paul Hauner <paul@paulhauner.com>
Co-authored-by: Jimmy Chen <jimmy@sigmaprime.io>
## Issue Addressed
#3212
## Proposed Changes
- Introduce a new `rate_limiting_backfill_queue` - any new inbound backfill work events gets immediately sent to this FIFO queue **without any processing**
- Spawn a `backfill_scheduler` routine that pops a backfill event from the FIFO queue at specified intervals (currently halfway through a slot, or at 6s after slot start for 12s slots) and sends the event to `BeaconProcessor` via a `scheduled_backfill_work_tx` channel
- This channel gets polled last in the `InboundEvents`, and work event received is wrapped in a `InboundEvent::ScheduledBackfillWork` enum variant, which gets processed immediately or queued by the `BeaconProcessor` (existing logic applies from here)
Diagram comparing backfill processing with / without rate-limiting:
https://github.com/sigp/lighthouse/issues/3212#issuecomment-1386249922
See this comment for @paulhauner's explanation and solution: https://github.com/sigp/lighthouse/issues/3212#issuecomment-1384674956
## Additional Info
I've compared this branch (with backfill processing rate limited to to 1 and 3 batches per slot) against the latest stable version. The CPU usage during backfill sync is reduced by ~5% - 20%, more details on this page:
https://hackmd.io/@jimmygchen/SJuVpJL3j
The above testing is done on Goerli (as I don't currently have hardware for Mainnet), I'm guessing the differences are likely to be bigger on mainnet due to block size.
### TODOs
- [x] Experiment with processing multiple batches per slot. (need to think about how to do this for different slot durations)
- [x] Add option to disable rate-limiting, enabed by default.
- [x] (No longer required now we're reusing the reprocessing queue) Complete the `backfill_scheduler` task when backfill sync is completed or not required
## Issue Addressed
Update the database-migrations to include v4.0.1 for database version v16:
## Proposed Changes
Update the table by adding a row
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
## Issue Addressed
#4127. PR to test port conflicts in CI tests .
## Proposed Changes
See issue for more details, potential solution could be adding a cache bound by time to the `unused_port` function.
## Issue Addressed
#3708
## Proposed Changes
- Add `is_finalized_block` method to `BeaconChain` in `beacon_node/beacon_chain/src/beacon_chain.rs`.
- Add `is_finalized_state` method to `BeaconChain` in `beacon_node/beacon_chain/src/beacon_chain.rs`.
- Add `fork_and_execution_optimistic_and_finalized` in `beacon_node/http_api/src/state_id.rs`.
- Add `ExecutionOptimisticFinalizedForkVersionedResponse` type in `consensus/types/src/fork_versioned_response.rs`.
- Add `execution_optimistic_finalized_fork_versioned_response`function in `beacon_node/http_api/src/version.rs`.
- Add `ExecutionOptimisticFinalizedResponse` type in `common/eth2/src/types.rs`.
- Add `add_execution_optimistic_finalized` method in `common/eth2/src/types.rs`.
- Update API response methods to include finalized.
- Remove `execution_optimistic_fork_versioned_response`
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
## Title
Optimise `update_validators` by decrypting key cache only when necessary
## Issue Addressed
Resolves [#3968: Slow performance of validator client PATCH API with hundreds of keys](https://github.com/sigp/lighthouse/issues/3968)
## Proposed Changes
1. Add a check to determine if there is at least one local definition before decrypting the key cache.
2. Assign an empty `KeyCache` when all definitions are of the `Web3Signer` type.
3. Perform cache-related operations (e.g., saving the modified key cache) only if there are local definitions.
## Additional Info
This PR addresses the excessive CPU usage and slow performance experienced when using the `PATCH lighthouse/validators/{pubkey}` request with a large number of keys. The issue was caused by the key cache using cryptography to decipher and cipher the cache entities every time the request was made. This operation called `scrypt`, which was very slow and required a lot of memory when there were many concurrent requests.
These changes have no impact on the overall functionality but can lead to significant performance improvements when working with remote signers. Importantly, the key cache is never used when there are only `Web3Signer` definitions, avoiding the expensive operation of decrypting the key cache in such cases.
Co-authored-by: Maksim Shcherbo <max.shcherbo@consensys.net>
## Issue Addressed
Which issue # does this PR address?
https://github.com/sigp/lighthouse/issues/3669
## Proposed Changes
Please list or describe the changes introduced by this PR.
- A new API to fetch fork choice data, as specified [here](https://github.com/ethereum/beacon-APIs/pull/232)
- A new integration test to test the new API
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
- `extra_data` field specified in the beacon-API spec is not implemented, please let me know if I should instead.
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Issue Addressed
The minimum supported Rust version has been set to 1.66 as of Lighthouse v4.0.0. This PR updates Rust to 1.66 in lcli Dockerfile.
Co-authored-by: Jimmy Chen <jimmy@sigmaprime.io>
## Proposed Changes
To prevent breakages from `cargo update`, this updates the `arbitrary` crate to a new commit from my fork. Unfortunately we still need to use my fork (even though my `bound` change was merged) because of this issue: https://github.com/rust-lang/rust-clippy/issues/10185.
In a couple of Rust versions it should be resolved upstream.
## Issue Addressed
NA
## Proposed Changes
- Bump versions.
- Bump openssl version to resolve various `cargo audit` notices.
## Additional Info
- Requires further testing
* rename 4844 to deneb
* rename 4844 to deneb
* move excess data gas field
* get EF tests working
* fix ef tests lint
* fix the blob identifier ef test
* fix accessed files ef test script
* get beacon chain tests passing
* introduce availability pending block
* add intoavailableblock trait
* small fixes
* add 'gossip blob cache' and start to clean up processing and transition types
* shard memory blob cache
* Initial commit
* Fix after rebase
* Add gossip verification conditions
* cache cleanup
* general chaos
* extended chaos
* cargo fmt
* more progress
* more progress
* tons of changes, just tryna compile
* everything, everywhere, all at once
* Reprocess an ExecutedBlock on unavailable blobs
* Add sus gossip verification for blobs
* Merge stuff
* Remove reprocessing cache stuff
* lint
* Add a wrapper to allow construction of only valid `AvailableBlock`s
* rename blob arc list to blob list
* merge cleanuo
* Revert "merge cleanuo"
This reverts commit 5e98326878.
* Revert "Revert "merge cleanuo""
This reverts commit 3a4009443a.
* fix rpc methods
* move beacon block and blob to eth2/types
* rename gossip blob cache to data availability checker
* lots of changes
* fix some compilation issues
* fix compilation issues
* fix compilation issues
* fix compilation issues
* fix compilation issues
* fix compilation issues
* cargo fmt
* use a common data structure for block import types
* fix availability check on proposal import
* refactor the blob cache and split the block wrapper into two types
* add type conversion for signed block and block wrapper
* fix beacon chain tests and do some renaming, add some comments
* Partial processing (#4)
* move beacon block and blob to eth2/types
* rename gossip blob cache to data availability checker
* lots of changes
* fix some compilation issues
* fix compilation issues
* fix compilation issues
* fix compilation issues
* fix compilation issues
* fix compilation issues
* cargo fmt
* use a common data structure for block import types
* fix availability check on proposal import
* refactor the blob cache and split the block wrapper into two types
* add type conversion for signed block and block wrapper
* fix beacon chain tests and do some renaming, add some comments
* cargo update (#6)
---------
Co-authored-by: realbigsean <sean@sigmaprime.io>
Co-authored-by: realbigsean <seananderson33@gmail.com>
* Update get blobs endpoint to return BlobSidecarList
* Update code comment
* Update blob retrieval to return BlobSidecarList without Arc
* Remove usage of BlobSidecarList type alias to avoid code conflicts
* Add clippy allow exception
## Issue Addressed
NA
## Proposed Changes
- Implements https://github.com/ethereum/consensus-specs/pull/3290/
- Bumps `ef-tests` to [v1.3.0-rc.4](https://github.com/ethereum/consensus-spec-tests/releases/tag/v1.3.0-rc.4).
The `CountRealizedFull` concept has been removed and the `--count-unrealized-full` and `--count-unrealized` BN flags now do nothing but log a `WARN` when used.
## Database Migration Debt
This PR removes the `best_justified_checkpoint` from fork choice. This field is persisted on-disk and the correct way to go about this would be to make a DB migration to remove the field. However, in this PR I've simply stubbed out the value with a junk value. I've taken this approach because if we're going to do a DB migration I'd love to remove the `Option`s around the justified and finalized checkpoints on `ProtoNode` whilst we're at it. Those options were added in #2822 which was included in Lighthouse v2.1.0. The options were only put there to handle the migration and they've been set to `Some` ever since v2.1.0. There's no reason to keep them as options anymore.
I started adding the DB migration to this branch but I started to feel like I was bloating this rather critical PR with nice-to-haves. I've kept the partially-complete migration [over in my repo](https://github.com/paulhauner/lighthouse/tree/fc-pr-18-migration) so we can pick it up after this PR is merged.
## Issue Addressed
NA
## Proposed Changes
Sets the mainnet Capella fork epoch as per https://github.com/ethereum/consensus-specs/pull/3300
## Additional Info
I expect the `ef_tests` to fail until we get a compatible consensus spec tests release.
## Issue Addressed
NA
## Proposed Changes
Replaces #4058 to attempt to reduce `ERRO Failed to send scheduled attestation` spam and provide more information for diagnosis. With this PR we achieve:
- When dequeuing attestations after a block is received, send only one log which reports `n` failures (rather than `n` logs reporting `n` failures).
- Make a distinction in logs between two separate attestation dequeuing events.
- Add more information to both log events to help assist with troubleshooting.
## Additional Info
NA
This PR enables the user to adjust the shuffling cache size.
This is useful for some HTTP API requests which require re-computing old shufflings. This PR currently optimizes the
beacon/states/{state_id}/committees HTTP API by first checking the cache before re-building shuffling.
If the shuffling is set to a non-default value, then the HTTP API request will also fill the cache when as it constructs new shufflings.
If the CLI flag is not present or the value is set to the default of 16 the default behaviour is observed.
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
Currently Lighthouse will remain uncontactable if users port forward a port that is not the same as the one they are listening on.
For example, if Lighthouse runs with port 9000 TCP/UDP locally but a router is configured to pass 9010 externally to the lighthouse node on 9000, other nodes on the network will not be able to reach the lighthouse node.
This occurs because Lighthouse does not update its ENR TCP port on external socket discovery. The intention was always that users should use `--enr-tcp-port` to customise this, but this is non-intuitive.
The difficulty arises because we have no discovery mechanism to find our external TCP port. If we discovery a new external UDP port, we must guess what our external TCP port might be. This PR assumes the external TCP port is the same as the external UDP port (which may not be the case) and thus updates the TCP port along with the UDP port if the `--enr-tcp-port` flag is not set.
Along with this PR, will be added documentation to the Lighthouse book so users can correctly understand and configure their ENR to maximize Lighthouse's connectivity.
This relies on https://github.com/sigp/discv5/pull/166 and we should wait for a new release in discv5 before adding this PR.
If a node is also a bootnode it can try to add itself to its own local routing table which will emit an error.
The error is entirely harmless but we would prefer to avoid emitting the error.
This PR does not attempt to add a boot node ENR if that ENR corresponds to our local peer-id/node-id.
## Issue Addressed
Resolves#4061
## Proposed Changes
Adds a message to tell users to check their EE.
## Additional Info
I really struggled to come up with something succinct and complete, so I'm totally open to feedback.
## Issue Addressed
NA
## Proposed Changes
When producing a block from a builder, there are two points where we could consider the block "broadcast":
1. When the blinded block is published to the builder.
2. When the un-blinded block is published to the P2P network (this is always *after* the previous step).
Our logging for late block broadcasts was using (2) for builder-blocks, which was creating a lot of false-positive logs. This is because the builder publishes the block on the P2P network themselves before returning it to us and we perform (2). For clarity, the logs were false-positives because we claim that the block was published late by us when it was actually published earlier by the builder.
This PR changes our logging behavior so we do our logging at (1) instead. It also updates our metrics for block broadcast to distinguish between local and builder blocks. I believe the metrics change will be natively compatible with existing Grafana dashboards.
## Additional Info
One could argue that the builder *should* return the block to us faster, however that's not the case. I think it's more important that we don't desensitize users with false-positives.
## Issue Addressed
Closes#3814, replaces #3818.
## Proposed Changes
* Add a WARN log for the case where we are attempting to sync chain segments but can't process them because they're building on an invalid parent. The most common case where we see this is when the execution node database is corrupt, causing sync to stall mysteriously (because we're currently logging the failure only at debug level).
* Additionally I've bumped up the logging for invalid execution payloads to `WARN`. This may result in some duplicate logs as we log errors from the `beacon_chain` and then again from the beacon processor. Invalid payloads and corrupt DBs _should_ be rare enough that this doesn't produce overwhelming log volume.
## Issue Addressed
Added note in lighthouse book to instruct users to use a min lighthouse requirement to run Siren Ui.
Which issue # does this PR address?
## Proposed Changes
Please list or describe the changes introduced by this PR.
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
There is a race condition which occurs when multiple discovery queries return at almost the exact same time and they independently contain a useful peer we would like to connect to.
The condition can occur that we can add the same peer to the dial queue, before we get a chance to process the queue.
This ends up displaying an error to the user:
```
ERRO Dialing an already dialing peer
```
Although this error is harmless it's not ideal.
There are two solutions to resolving this:
1. As we decide to dial the peer, we change the state in the peer-db to dialing (before we add it to the queue) which would prevent other requests from adding to the queue.
2. We prevent duplicates in the dial queue
This PR has opted for 2. because 1. will complicate the code in that we are changing states in non-intuitive places. Although this technically adds a very slight performance cost, its probably a cleaner solution as we can keep the state-changing logic in one place.
* update docs
* introduce a temp enum to model an adjusted `BlockWrapper` and fix blob coupling
* fix compilation issue
* fix blob coupling in the network context
* review comments
## Issue Addressed
#3938
## Proposed Changes
- `network::Processor` is deleted and all it's logic is moved to `network::Router`.
- The `network::Router` module is moved to a single file.
- The following functions are deleted: `on_disconnect` `send_status` `on_status_response` `on_blocks_by_root_request` `on_lightclient_bootstrap` `on_blocks_by_range_request` `on_block_gossip` `on_unaggregated_attestation_gossip` `on_aggregated_attestation_gossip` `on_voluntary_exit_gossip` `on_proposer_slashing_gossip` `on_attester_slashing_gossip` `on_sync_committee_signature_gossip` `on_sync_committee_contribution_gossip` `on_light_client_finality_update_gossip` `on_light_client_optimistic_update_gossip`. This deletions are possible because the updated `Router` allows the underlying methods to be called directly.
## Issue Addressed
In #4027 I forgot to add the `parent_block_number` to the payload attributes SSE.
## Proposed Changes
Compute the parent block number while computing the pre-payload attributes. Pass it on to the SSE stream.
## Additional Info
Not essential for v3.5.1 as I suspect most builders don't need the `parent_block_root`. I would like to use it for my dummy no-op builder however.
## Issue Addressed
Add support for ipv6 and dual stack in lighthouse.
## Proposed Changes
From an user perspective, now setting an ipv6 address, optionally configuring the ports should feel exactly the same as using an ipv4 address. If listening over both ipv4 and ipv6 then the user needs to:
- use the `--listen-address` two times (ipv4 and ipv6 addresses)
- `--port6` becomes then required
- `--discovery-port6` can now be used to additionally configure the ipv6 udp port
### Rough list of code changes
- Discovery:
- Table filter and ip mode set to match the listening config.
- Ipv6 address, tcp port and udp port set in the ENR builder
- Reported addresses now check which tcp port to give to libp2p
- LH Network Service:
- Can listen over Ipv6, Ipv4, or both. This uses two sockets. Using mapped addresses is disabled from libp2p and it's the most compatible option.
- NetworkGlobals:
- No longer stores udp port since was not used at all. Instead, stores the Ipv4 and Ipv6 TCP ports.
- NetworkConfig:
- Update names to make it clear that previous udp and tcp ports in ENR were Ipv4
- Add fields to configure Ipv6 udp and tcp ports in the ENR
- Include advertised enr Ipv6 address.
- Add type to model Listening address that's either Ipv4, Ipv6 or both. A listening address includes the ip, udp port and tcp port.
- UPnP:
- Kept only for ipv4
- Cli flags:
- `--listen-addresses` now can take up to two values
- `--port` will apply to ipv4 or ipv6 if only one listening address is given. If two listening addresses are given it will apply only to Ipv4.
- `--port6` New flag required when listening over ipv4 and ipv6 that applies exclusively to Ipv6.
- `--discovery-port` will now apply to ipv4 and ipv6 if only one listening address is given.
- `--discovery-port6` New flag to configure the individual udp port of ipv6 if listening over both ipv4 and ipv6.
- `--enr-udp-port` Updated docs to specify that it only applies to ipv4. This is an old behaviour.
- `--enr-udp6-port` Added to configure the enr udp6 field.
- `--enr-tcp-port` Updated docs to specify that it only applies to ipv4. This is an old behaviour.
- `--enr-tcp6-port` Added to configure the enr tcp6 field.
- `--enr-addresses` now can take two values.
- `--enr-match` updated behaviour.
- Common:
- rename `unused_port` functions to specify that they are over ipv4.
- add functions to get unused ports over ipv6.
- Testing binaries
- Updated code to reflect network config changes and unused_port changes.
## Additional Info
TODOs:
- use two sockets in discovery. I'll get back to this and it's on https://github.com/sigp/discv5/pull/160
- lcli allow listening over two sockets in generate_bootnodes_enr
- add at least one smoke flag for ipv6 (I have tested this and works for me)
- update the book
## Proposed Changes
The current `/lighthouse/nat` implementation checks for _zero_ address updated messages, when it should check for a _non-zero_ number. This was spotted while debugging an issue on Discord where a user's ports weren't forwarded but `/lighthouse/nat` was still returning `true`.
## Issue Addressed
#3435
## Proposed Changes
Fire a warning with the path of JWT to be created when the path given by --execution-jwt is not found
Currently, the same error is logged if the jwt is found but doesn't match the execution client's jwt, and if no jwt was found at the given path. This makes it very hard to tell if you accidentally typed the wrong path, as a new jwt is created silently that won't match the execution client's jwt. So instead, it will now fire a warning stating that a jwt is being generated at the given path.
## Additional Info
In the future, it may be smarter to handle this case by adding an InvalidJWTPath member to the Error enum in lib.rs or auth.rs
that can be handled during upcheck()
This is my first PR and first project with rust. so thanks to anyone who looks at this for their patience and help!
Co-authored-by: Sebastian Richel <47844429+sebastianrich18@users.noreply.github.com>
## Proposed Changes
Two tiny updates to satisfy Clippy 1.68
Plus refactoring of the `http_api` into less complex types so the compiler can chew and digest them more easily.
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
* wip
* fix router
* arc the byroot responses we send
* add placeholder for blob verification
* respond to blobs by range and blobs by root request in the most horrible and gross way ever
* everything in sync is now unimplemented
* fix compiation issues
* http_pi change is very small, just add it
* remove ctrl-c ctrl-v's docs
## Issue Addressed
#4040
## Proposed Changes
- Add the `always_prefer_builder_payload` field to `Config` in `beacon_node/client/src/config.rs`.
- Add that same field to `Inner` in `beacon_node/execution_layer/src/lib.rs`
- Modify the logic for picking the payload in `beacon_node/execution_layer/src/lib.rs`
- Add the `always-prefer-builder-payload` flag to the beacon node CLI
- Test the new flags in `lighthouse/tests/beacon_node.rs`
Co-authored-by: Paul Hauner <paul@paulhauner.com>
## Issue Addressed
NA
## Proposed Changes
In #4024 we added metrics to expose the latency measurements from a VC to each BN. Whilst playing with these new metrics on our infra I realised it would be great to have a single metric to make sure that the primary BN for each VC has a reasonable latency. With the current "metrics for all BNs" it's hard to tell which is the primary.
## Additional Info
NA
## Issue Addressed
NA
## Proposed Changes
- Adds a `WARN` statement for Capella, just like the previous forks.
- Adds a hint message to all those WARNs to suggest the user update the BN or VC.
## Additional Info
NA
## Proposed Changes
Fix the cargo audit failure caused by [RUSTSEC-2023-0018](https://rustsec.org/advisories/RUSTSEC-2023-0018) which we were exposed to via `tempfile`.
## Additional Info
I've held back the libp2p crate for now because it seemed to introduce another duplicate dependency on libp2p-core, for a total of 3 copies. Maybe that's fine, but we can sort it out later.
## Issue Addressed
Closes#3963 (hopefully)
## Proposed Changes
Compute attestation selection proofs gradually each slot rather than in a single `join_all` at the start of each epoch. On a machine with 5k validators this replaces 5k tasks signing 5k proofs with 1 task that signs 5k/32 ~= 160 proofs each slot.
Based on testing with Goerli validators this seems to reduce the average time to produce a signature by preventing Tokio and the OS from falling over each other trying to run hundreds of threads. My testing so far has been with local keystores, which run on a dynamic pool of up to 512 OS threads because they use [`spawn_blocking`](https://docs.rs/tokio/1.11.0/tokio/task/fn.spawn_blocking.html) (and we haven't changed the default).
An earlier version of this PR hyper-optimised the time-per-signature metric to the detriment of the entire system's performance (see the reverted commits). The current PR is conservative in that it avoids touching the attestation service at all. I think there's more optimising to do here, but we can come back for that in a future PR rather than expanding the scope of this one.
The new algorithm for attestation selection proofs is:
- We sign a small batch of selection proofs each slot, for slots up to 8 slots in the future. On average we'll sign one slot's worth of proofs per slot, with an 8 slot lookahead.
- The batch is signed halfway through the slot when there is unlikely to be contention for signature production (blocks are <4s, attestations are ~4-6 seconds, aggregates are 8s+).
## Performance Data
_See first comment for updated graphs_.
Graph of median signing times before this PR:
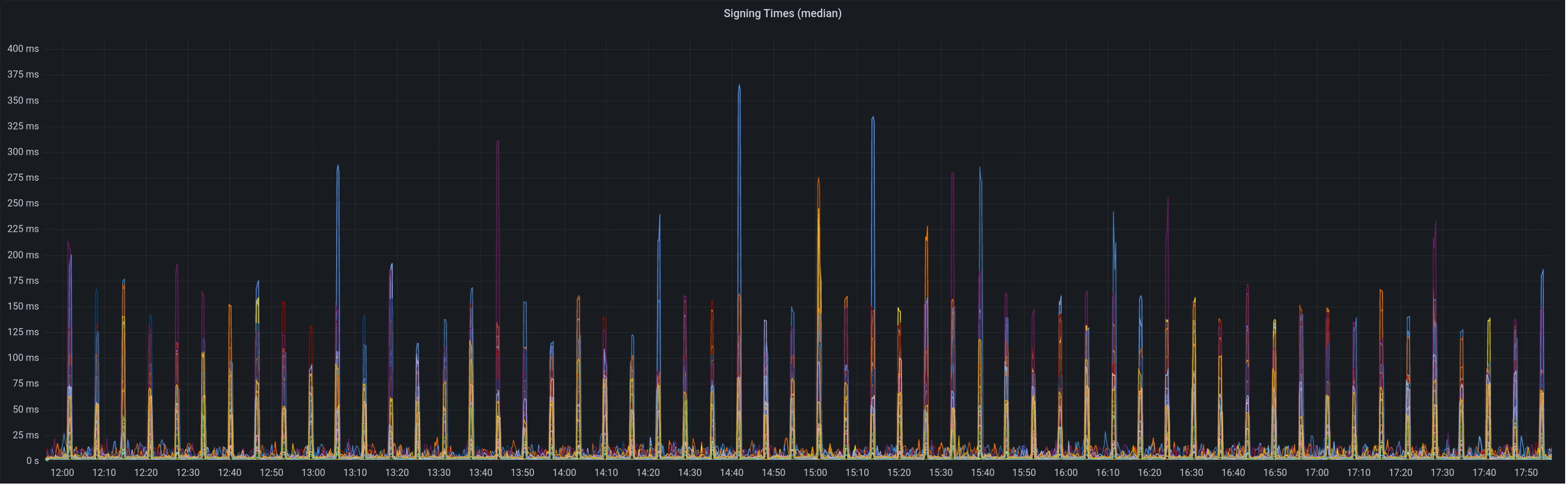
Graph of update attesters metric (includes selection proof signing) before this PR:
Median signing time after this PR (prototype from 12:00, updated version from 13:30):
99th percentile on signing times (bounded attestation signing from 16:55, now removed):
Attester map update timing after this PR:
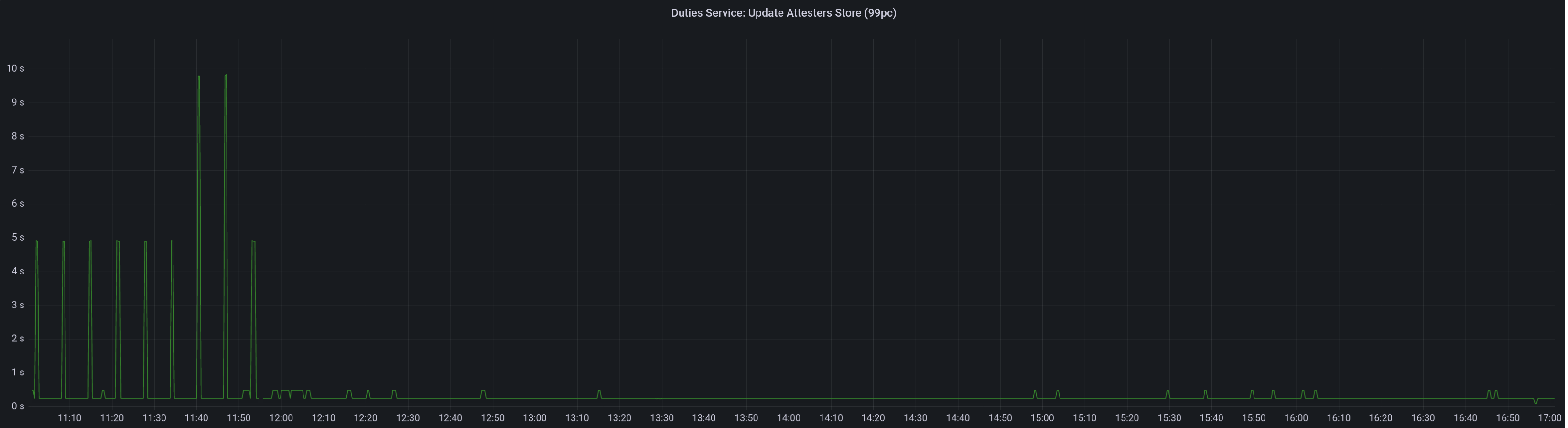
Selection proof signings per second change:
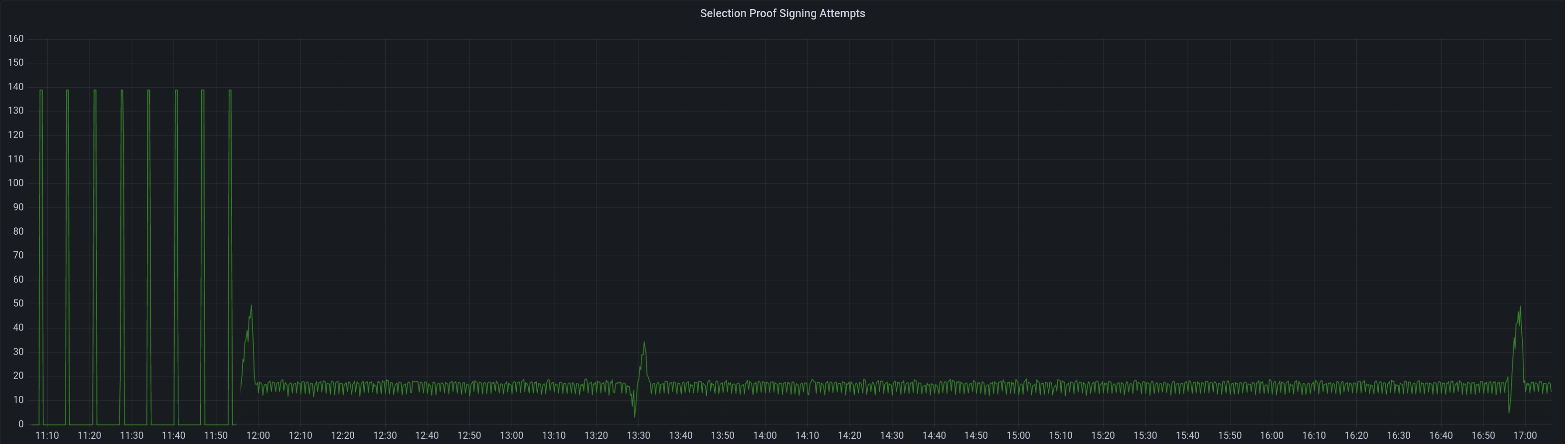
## Link to late blocks
I believe this is related to the slow block signings because logs from Stakely in #3963 show these two logs almost 5 seconds apart:
> Feb 23 18:56:23.978 INFO Received unsigned block, slot: 5862880, service: block, module: validator_client::block_service:393
> Feb 23 18:56:28.552 INFO Publishing signed block, slot: 5862880, service: block, module: validator_client::block_service:416
The only thing that happens between those two logs is the signing of the block:
0fb58a680d/validator_client/src/block_service.rs (L410-L414)
Helpfully, Stakely noticed this issue without any Lighthouse BNs in the mix, which pointed to a clear issue in the VC.
## TODO
- [x] Further testing on testnet infrastructure.
- [x] Make the attestation signing parallelism configurable.
## Issue Addressed
Closes#3896Closes#3998Closes#3700
## Proposed Changes
- Optimise the calculation of withdrawals for payload attributes by avoiding state clones, avoiding unnecessary state advances and reading from the snapshot cache if possible.
- Use the execution layer's payload attributes cache to avoid re-calculating payload attributes. I actually implemented a new LRU cache just for withdrawals but it had the exact same key and most of the same data as the existing payload attributes cache, so I deleted it.
- Add a new SSE event that fires when payloadAttributes are calculated. This is useful for block builders, a la https://github.com/ethereum/beacon-APIs/issues/244.
- Add a new CLI flag `--always-prepare-payload` which forces payload attributes to be sent with every fcU regardless of connected proposers. This is intended for use by builders/relays.
For maximum effect, the flags I've been using to run Lighthouse in "payload builder mode" are:
```
--always-prepare-payload \
--prepare-payload-lookahead 12000 \
--suggested-fee-recipient 0x0000000000000000000000000000000000000000
```
The fee recipient is required so Lighthouse has something to pack in the payload attributes (it can be ignored by the builder). The lookahead causes fcU to be sent at the start of every slot rather than at 8s. As usual, fcU will also be sent after each change of head block. I think this combination is sufficient for builders to build on all viable heads. Often there will be two fcU (and two payload attributes) sent for the same slot: one sent at the start of the slot with the head from `n - 1` as the parent, and one sent after the block arrives with `n` as the parent.
Example usage of the new event stream:
```bash
curl -N "http://localhost:5052/eth/v1/events?topics=payload_attributes"
```
## Additional Info
- [x] Tests added by updating the proposer re-org tests. This has the benefit of testing the proposer re-org code paths with withdrawals too, confirming that the new changes don't interact poorly.
- [ ] Benchmarking with `blockdreamer` on devnet-7 showed promising results but I'm yet to do a comparison to `unstable`.
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Issue Addressed
NA
## Proposed Changes
Adds a service which periodically polls (11s into each mainnet slot) the `node/version` endpoint on each BN and roughly measures the round-trip latency. The latency is exposed as a `DEBG` log and a Prometheus metric.
The `--latency-measurement-service` has been added to the VC, with the following options:
- `--latency-measurement-service true`: enable the service (default).
- `--latency-measurement-service`: (without a value) has the same effect.
- `--latency-measurement-service false`: disable the service.
## Additional Info
Whilst looking at our staking setup, I think the BN+VC latency is contributing to late blocks. Now that we have to wait for the builders to respond it's nice to try and do everything we can to reduce that latency. Having visibility is the first step.
## Issue Addressed
NA
## Proposed Changes
As discovered in #4034, Lighthouse is not accepting `latest_valid_hash == None` in an `INVALID` response to `newPayload`. The `null`/`None` response *was* illegal at one point, however it was added in https://github.com/ethereum/execution-apis/pull/254.
This PR brings Lighthouse in line with the standard and should fix the root cause of what #4034 patched around.
## Additional Info
NA
## Issue Addressed
Cleaner resolution for #4006
## Proposed Changes
We are currently subscribing to core topics of new forks way before the actual fork since we had just a single `CORE_TOPICS` array. This PR separates the core topics for every fork and subscribes to only required topics based on the current fork.
Also adds logic for subscribing to the core topics of a new fork only 2 slots before the fork happens.
2 slots is to give enough time for the gossip meshes to form.
Currently doesn't add logic to remove topics from older forks in new forks. For e.g. in the coupled 4844 world, we had to remove the `BeaconBlock` topic in favour of `BeaconBlocksAndBlobsSidecar` at the 4844 fork. It should be easy enough to add though. Not adding it because I'm assuming that #4019 will get merged before this PR and we won't require any deletion logic. Happy to add it regardless though.
## Proposed Changes
Remove built-in support for Ropsten and Kiln via the `--network` flag. Both testnets are long dead and deprecated.
This shaves about 30MiB off the binary size, from 135MiB to 103MiB (maxperf), or 165MiB to 135MiB (release).
## Issue Addressed
Cleans up all the remnants of 4844 in capella. This makes sure when 4844 is reviewed there is nothing we are missing because it got included here
## Proposed Changes
drop a bomb on every 4844 thing
## Additional Info
Merge process I did (locally) is as follows:
- squash merge to produce one commit
- in new branch off unstable with the squashed commit create a `git revert HEAD` commit
- merge that new branch onto 4844 with `--strategy ours`
- compare local 4844 to remote 4844 and make sure the diff is empty
- enjoy
Co-authored-by: Paul Hauner <paul@paulhauner.com>
## Issue Addressed
NA
## Proposed Changes
Adds two new `DEBG` logs to the HTTP API:
1. As soon as we are requested to produce a block.
2. As soon as a signed block is received.
In #3858 we added some very helpful logs to the VC so we could see when things are happening with block proposals in the VC. After doing some more debugging, I found that I can tell when the VC is sending a block but I *can't* tell the time that the BN receives it (I can only get the time after the BN has started doing some work with the block). Knowing when the VC published and as soon as the BN receives is useful for determining the delays introduced by network latency (and some other things like JSON decoding, etc).
## Additional Info
NA
## Issue Addressed
NA
## Proposed Changes
Updates our `ef_tests` to use: https://github.com/ethereum/consensus-specs/releases/tag/v1.3.0-rc.3
This required:
- Skipping a `merkle_proof_validity` test (see #4022)
- Account for the `eip4844` tests changing name to `deneb`
- My IDE did some Python linting during this change. It seemed simple and nice so I left it there.
## Additional Info
NA
This fixes issues with certain metrics scrapers, which might error if the content-type is not correctly set.
## Issue Addressed
Fixes https://github.com/sigp/lighthouse/issues/3437
## Proposed Changes
Simply set header: `Content-Type: text/plain` on metrics server response. Seems like the errored branch does this correctly already.
## Additional Info
This is needed also to enable influx-db metric scraping which work very nicely with Geth.
## Proposed Changes
Allowing compiling without MDBX by running:
```bash
CARGO_INSTALL_EXTRA_FLAGS="--no-default-features" make
```
The reasons to do this are several:
- Save compilation time if the slasher won't be used
- Work around compilation errors in slasher backend dependencies (our pinned version of MDBX is currently not compiling on FreeBSD with certain compiler versions).
## Additional Info
When I opened this PR we were using resolver v1 which [doesn't disable default features in dependencies](https://doc.rust-lang.org/cargo/reference/features.html#resolver-version-2-command-line-flags), and `mdbx` is default for the `slasher` crate. Even after the resolver got changed to v2 in #3697 compiling with `--no-default-features` _still_ wasn't turning off the slasher crate's default features, so I added `default-features = false` in all the places we depend on it.
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Issue Addressed
NA
## Proposed Changes
- Bump versions
## Sepolia Capella Upgrade
This release will enable the Capella fork on Sepolia. We are planning to publish this release on the 23rd of Feb 2023.
Users who can build from source and wish to do pre-release testing can use this branch.
## Additional Info
- [ ] Requires further testing
This is a correction to #3757.
The correction registers a peer that is being disconnected in the local peer manager db to ensure we are tracking the correct state.
## Issue Addressed
N/A
## Proposed Changes
The doppelganger tests were failing silently since the `PROPOSER_BOOST` config was not set. Sets the config and script returns an error if any subprocess fails.
## Issue Addressed
#3804
## Proposed Changes
- Add `total_balance` to the validator monitor and adjust the number of historical epochs which are cached.
- Allow certain values in the cache to be served out via the HTTP API without requiring a state read.
## Usage
```
curl -X POST "http://localhost:5052/lighthouse/ui/validator_info" -d '{"indices": [0]}' -H "Content-Type: application/json" | jq
```
```
{
"data": {
"validators": {
"0": {
"info": [
{
"epoch": 172981,
"total_balance": 36566388519
},
...
{
"epoch": 172990,
"total_balance": 36566496513
}
]
},
"1": {
"info": [
{
"epoch": 172981,
"total_balance": 36355797968
},
...
{
"epoch": 172990,
"total_balance": 36355905962
}
]
}
}
}
}
```
## Additional Info
This requires no historical states to operate which mean it will still function on the freshly checkpoint synced node, however because of this, the values will populate each epoch (up to a maximum of 10 entries).
Another benefit of this method, is that we can easily cache any other values which would normally require a state read and serve them via the same endpoint. However, we would need be cautious about not overly increasing block processing time by caching values from complex computations.
This also caches some of the validator metrics directly, rather than pulling them from the Prometheus metrics when the API is called. This means when the validator count exceeds the individual monitor threshold, the cached values will still be available.
Co-authored-by: Paul Hauner <paul@paulhauner.com>
* Modify comment to only include 4844
Capella only modifies per epoch processing by adding
`process_historical_summaries_update`, which does not change the realization of
justification or finality.
Whilst 4844 does not currently modify realization, the spec is not yet final
enough to say that it never will.
* Clarify address change verification comment
The verification of the address change doesn't really have anything to do with
the current epoch. I think this was just a copy-paste from a function like
`verify_exit`.
* Add extra encoding/decoding tests
* Remove TODO
The method LGTM
* Remove `FreeAttestation`
This is an ancient relic, I'm surprised it still existed!
* Add paranoid check for eip4844 code
This is not technically necessary, but I think it's nice to be explicit about
EIP4844 consensus code for the time being.
* Reduce big-O complexity of address change pruning
I'm not sure this is *actually* useful, but it might come in handy if we see a
ton of address changes at the fork boundary. I know the devops team have been
testing with ~100k changes, so maybe this will help in that case.
* Revert "Reduce big-O complexity of address change pruning"
This reverts commit e7d93e6cc7.
* Remove CapellaReadiness::NotSynced
Some EEs have a habit of flipping between synced/not-synced, which causes some
spurious "Not read for the merge" messages back before the merge. For the
merge, if the EE wasn't synced the CE simple wouldn't go through the transition
(due to optimistic sync stuff). However, we don't have that hard requirement
for Capella; the CE will go through the fork and just wait for the EE to catch
up. I think that removing `NotSynced` here will avoid false-positives on the
"Not ready logs..". We'll be creating other WARN/ERRO logs if the EE isn't
synced, anyway.
* Change some Capella readiness logging
There's two changes here:
1. Shorten the log messages, for readability.
2. Change the hints.
Connecting a Capella-ready LH to a non-Capella-ready EE gives this log:
```
WARN Not ready for Capella info: The execution endpoint does not appear to support the required engine api methods for Capella: Required Methods Unsupported: engine_getPayloadV2 engine_forkchoiceUpdatedV2 engine_newPayloadV2, service: slot_notifier
```
This variant of error doesn't get a "try updating" style hint, when it's the
one that needs it. This is because we detect the method-not-found reponse from
the EE and return default capabilities, rather than indicating that the request
fails. I think it's fair to say that an EE upgrade is required whenever it
doesn't provide the required methods.
I changed the `ExchangeCapabilitiesFailed` message since that can only happen
when the EE fails to respond with anything other than success or not-found.
## Proposed Changes
* Bump Go from 1.17 to 1.20. The latest Geth release v1.11.0 requires 1.18 minimum.
* Prevent a cache miss during payload building by using the right fee recipient. This prevents Geth v1.11.0 from building a block with 0 transactions. The payload building mechanism is overhauled in the new Geth to improve the payload every 2s, and the tests were failing because we were falling back on a `getPayload` call with no lookahead due to `get_payload_id` cache miss caused by the mismatched fee recipient. Alternatively we could hack the tests to send `proposer_preparation_data`, but I think the static fee recipient is simpler for now.
* Add support for optionally enabling Lighthouse logs in the integration tests. Enable using `cargo run --release --features logging/test_logger`. This was very useful for debugging.
## Issue Addressed
I discovered this issue while implementing [this test](https://github.com/jimmygchen/lighthouse/blob/test-example/beacon_node/network/src/beacon_processor/tests.rs#L895), where I tried to manipulate the slot clock with:
`rig.chain.slot_clock.set_current_time(duration);`
however the change doesn't get reflected in the `slot_clock` in `ReprocessQueue`, and I realised `slot_clock` was cloned a few times in the code, and therefore changing the time in `rig.chain.slot_clock` doesn't have any effect in `ReprocessQueue`.
I've incorporated the suggestion from the @paulhauner and @michaelsproul - wrapping the `ManualSlotClock.current_time` (`RwLock<Duration>)` in an `Arc`, and the above test now passes.
Let's see if this breaks any existing tests :)
## Issue Addressed
Windows tests for subscription and unsubscriptions fail in CI sporadically. We usually ignore this failures, so this PR aims to help reduce the failure noise. Associated issue is https://github.com/sigp/lighthouse/issues/3960
On heavily crowded networks, we are seeing many attempted connections to our node every second.
Often these connections come from peers that have just been disconnected. This can be for a number of reasons including:
- We have deemed them to be not as useful as other peers
- They have performed poorly
- They have dropped the connection with us
- The connection was spontaneously lost
- They were randomly removed because we have too many peers
In all of these cases, if we have reached or exceeded our target peer limit, there is no desire to accept new connections immediately after the disconnect from these peers. In fact, it often costs us resources to handle the established connections and defeats some of the logic of dropping them in the first place.
This PR adds a timeout, that prevents recently disconnected peers from reconnecting to us.
Technically we implement a ban at the swarm layer to prevent immediate re connections for at least 10 minutes. I decided to keep this light, and use a time-based LRUCache which only gets updated during the peer manager heartbeat to prevent added stress of polling a delay map for what could be a large number of peers.
This cache is bounded in time. An extra space bound could be added should people consider this a risk.
Co-authored-by: Diva M <divma@protonmail.com>
## Issue Addressed
The documentation referring to build from source mismatches with the what gitworkflow uses.
aa5b7ef783/book/src/installation-source.md (L118-L120)
## Proposed Changes
Because the github workflow uses `cross` to build from source and for that build there is different env variable `CROSS_FEATURES` so need pass at the compile time.
## Additional Info
Verified that existing `-dev` builds does not contains the `minimal` spec enabled.
```bash
> docker run --rm --name node-5-cl-lighthouse sigp/lighthouse:latest-amd64-unstable-dev lighthouse --version
Lighthouse v3.4.0-aa5b7ef
BLS library: blst-portable
SHA256 hardware acceleration: true
Allocator: jemalloc
Specs: mainnet (true), minimal (false), gnosis (true)
```
## Issue Addressed
Fix a bug introduced by #3696. The bug is not expected to occur frequently, so releasing this PR is non-urgent.
## Proposed Changes
* Add a variant to `StoreOp` that allows a raw KV operation to be passed around.
* Return to using `self.store.do_atomically` rather than `self.store.hot_db.do_atomically`. This streamlines the write back into a single call and makes our auto-revert work again.
* Prevent `import_block_update_shuffling_cache` from failing block import. This is an outstanding bug from before v3.4.0 which may have contributed to some random unexplained database corruption.
## Additional Info
In #3696 I split the database write into two calls, one to convert the `StoreOp`s to `KeyValueStoreOp`s and one to write them. This had the unfortunate side-effect of damaging our atomicity guarantees in case of a write error. If the first call failed, we would be left with the block in fork choice but not on-disk (or the snapshot cache), which would prevent us from processing any descendant blocks. On `unstable` the first call is very unlikely to fail unless the disk is full, but on `tree-states` the conversion is more involved and a user reported database corruption after it failed in a way that should have been recoverable.
Additionally, as @emhane observed, #3696 also inadvertently removed the import of the new block into the block cache. Although this seems like it could have negatively impacted performance, there are several mitigating factors:
- For regular block processing we should almost always load the parent block (and state) from the snapshot cache.
- We often load blinded blocks, which bypass the block cache anyway.
- Metrics show no noticeable increase in the block cache miss rate with v3.4.0.
However, I expect the block cache _will_ be useful again in `tree-states`, so it is restored to use by this PR.
## Issue Addressed
NA
## Proposed Changes
Our `ERRO` stream has been rather noisy since the merge due to some unexpected behaviours of builders and EEs. Now that we've been running post-merge for a while, I think we can drop some of these `ERRO` to `WARN` so we're not "crying wolf".
The modified logs are:
#### `ERRO Execution engine call failed`
I'm seeing this quite frequently on Geth nodes. They seem to timeout when they're busy and it rarely indicates a serious issue. We also have logging across block import, fork choice updating and payload production that raise `ERRO` or `CRIT` when the EE times out, so I think we're not at risk of silencing actual issues.
#### `ERRO "Builder failed to reveal payload"`
In #3775 we reduced this log from `CRIT` to `ERRO` since it's common for builders to fail to reveal the block to the producer directly whilst still broadcasting it to the networ. I think it's worth dropping this to `WARN` since it's rarely interesting.
I elected to stay with `WARN` since I really do wish builders would fulfill their API promises by returning the block to us. Perhaps I'm just being pedantic here, I could be convinced otherwise.
#### `ERRO "Relay error when registering validator(s)"`
It seems like builders and/or mev-boost struggle to handle heavy loads of validator registrations. I haven't observed issues with validators not actually being registered, but I see timeouts on these endpoints many times a day. It doesn't seem like this `ERRO` is worth it.
#### `ERRO Error fetching block for peer ExecutionLayerErrorPayloadReconstruction`
This means we failed to respond to a peer on the P2P network with a block they requested because of an error in the `execution_layer`. It's very common to see timeouts or incomplete responses on this endpoint whilst the EE is busy and I don't think it's important enough for an `ERRO`. As long as the peer count stays high, I don't think the user needs to be actively concerned about how we're responding to peers.
## Additional Info
NA
Resolves the cargo-audit failure caused by https://rustsec.org/advisories/RUSTSEC-2023-0010.
I also removed the ignore for `RUSTSEC-2020-0159` as we are no longer using a vulnerable version of `chrono`. We still need the other ignore for `time 0.1` because we depend on it via `sloggers -> chrono -> time 0.1`.
## Proposed Changes
Remove the `[patch]` for `fixed-hash`.
We pinned it years ago in #2710 to fix `arbitrary` support. Nowadays the 0.7 version of `fixed-hash` is only used by the `web3` crate and doesn't need `arbitrary`.
~~Blocked on #3916 but could be merged in the same Bors batch.~~
## Issue Addressed
NA
## Description
We were missing an edge case when checking to see if a block is a descendant of the finalized checkpoint. This edge case is described for one of the tests in this PR:
a119edc739/consensus/proto_array/src/proto_array_fork_choice.rs (L1018-L1047)
This bug presented itself in the following mainnet log:
```
Jan 26 15:12:42.841 ERRO Unable to validate attestation error: MissingBeaconState(0x7c30cb80ec3d4ec624133abfa70e4c6cfecfca456bfbbbff3393e14e5b20bf25), peer_id: 16Uiu2HAm8RPRciXJYtYc5c3qtCRdrZwkHn2BXN3XP1nSi1gxHYit, type: "unaggregated", slot: Slot(5660161), beacon_block_root: 0x4a45e59da7cb9487f4836c83bdd1b741b4f31c67010c7ae343fa6771b3330489
```
Here the BN is rejecting an attestation because of a "missing beacon state". Whilst it was correct to reject the attestation, it should have rejected it because it attests to a block that conflicts with finality rather than claiming that the database is inconsistent.
The block that this attestation points to (`0x4a45`) is block `C` in the above diagram. It is a non-canonical block in the first slot of an epoch that conflicts with the finalized checkpoint. Due to our lazy pruning of proto array, `0x4a45` was still present in proto-array. Our missed edge-case in [`ForkChoice::is_descendant_of_finalized`](38514c07f2/consensus/fork_choice/src/fork_choice.rs (L1375-L1379)) would have indicated to us that the block is a descendant of the finalized block. Therefore, we would have accepted the attestation thinking that it attests to a descendant of the finalized *checkpoint*.
Since we didn't have the shuffling for this erroneously processed block, we attempted to read its state from the database. This failed because we prune states from the database by keeping track of the tips of the chain and iterating back until we find a finalized block. This would have deleted `C` from the database, hence the `MissingBeaconState` error.
## Issue Addressed
Resolves#2521
## Proposed Changes
Add a metric that indicates the next attestation duty slot for all managed validators in the validator client.
## Issue Addressed
NA
## Proposed Changes
Removes the "Participation Rate" since it references an undefined variable: `previous_epoch_attesting_gwei`.
I didn't replace it with anything since I think "Justification/Finalization Rate" already expresses what it was trying to express.
## Additional Info
NA
## Issue Addressed
Resolves the cargo-audit failure caused by https://rustsec.org/advisories/RUSTSEC-2023-0010.
I also removed the ignore for `RUSTSEC-2020-0159` as we are no longer using a vulnerable version of `chrono`. We still need the other ignore for `time 0.1` because we depend on it via `sloggers -> chrono -> time 0.1`.
## Issue Addressed
Adds self rate limiting options, mainly with the idea to comply with peer's rate limits in small testnets
## Proposed Changes
Add a hidden flag `self-limiter` this can take no value, or customs values to configure quotas per protocol
## Additional Info
### How to use
`--self-limiter` will turn on the self rate limiter applying the same params we apply to inbound requests (requests from other peers)
`--self-limiter "beacon_blocks_by_range:64/1"` will turn on the self rate limiter for ALL protocols, but change the quota for bbrange to 64 requested blocks per 1 second.
`--self-limiter "beacon_blocks_by_range:64/1;ping:1/10"` same as previous one, changing the quota for ping as well.
### Caveats
- The rate limiter is either on or off for all protocols. I added the custom values to be able to change the quotas per protocol so that some protocols can be given extremely loose or tight quotas. I think this should satisfy every need even if we can't technically turn off rate limits per protocol.
- This reuses the rate limiter struct for the inbound requests so there is this ugly part of the code in which we need to deal with the inbound only protocols (light client stuff) if this becomes too ugly as we add lc protocols, we might want to split the rate limiters. I've checked this and looks doable with const generics to avoid so much code duplication
### Knowing if this is on
```
Feb 06 21:12:05.493 DEBG Using self rate limiting params config: OutboundRateLimiterConfig { ping: 2/10s, metadata: 1/15s, status: 5/15s, goodbye: 1/10s, blocks_by_range: 1024/10s, blocks_by_root: 128/10s }, service: libp2p_rpc, service: libp2p
```
## Proposed Changes
There are some features that are enabled/disabled with the `FEATURES` env variable. This PR would introduce a pattern to introduce docker images based on those features. This can be useful later on to have specific images for some experimental features in the future.
## Additional Info
We at Lodesart need to have `minimal` spec support for some cross-client network testing. To make it efficient on the CI, we tend to use minimal preset.
* Add first efforts at broadcast
* Tidy
* Move broadcast code to client
* Progress with broadcast impl
* Rename to address change
* Fix compile errors
* Use `while` loop
* Tidy
* Flip broadcast condition
* Switch to forgetting individual indices
* Always broadcast when the node starts
* Refactor into two functions
* Add testing
* Add another test
* Tidy, add more testing
* Tidy
* Add test, rename enum
* Rename enum again
* Tidy
* Break loop early
* Add V15 schema migration
* Bump schema version
* Progress with migration
* Update beacon_node/client/src/address_change_broadcast.rs
Co-authored-by: Michael Sproul <micsproul@gmail.com>
* Fix typo in function name
---------
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Proposed Changes
Remove the `[patch]` for `fixed-hash`.
We pinned it years ago in #2710 to fix `arbitrary` support. Nowadays the 0.7 version of `fixed-hash` is only used by the `web3` crate and doesn't need `arbitrary`.
~~Blocked on #3916 but could be merged in the same Bors batch.~~
* Use Local Payload if More Profitable than Builder
* Rename clone -> clone_from_ref
* Minimize Clones of GetPayloadResponse
* Cleanup & Fix Tests
* Added Tests for Payload Choice by Profit
* Fix Outdated Comments
## Proposed Changes
Clippy 1.67.0 put us on blast for the size of some of our errors, most of them written by me ( 👀 ). This PR shrinks the size of `BeaconChainError` by dropping some extraneous info and boxing an inner error which should only occur infrequently anyway.
For the `AttestationSlashInfo` and `BlockSlashInfo` I opted to ignore the lint as they are always used in a `Result<A, Info>` where `A` is a similar size. This means they don't bloat the size of the `Result`, so it's a bit annoying for Clippy to report this as an issue.
I also chose to ignore `clippy::uninlined-format-args` because I think the benefit-to-churn ratio is too low. E.g. sometimes we have long identifiers in `format!` args and IMO the non-inlined form is easier to read:
```rust
// I prefer this...
format!(
"{} did {} to {}",
REALLY_LONG_CONSTANT_NAME,
ANOTHER_REALLY_LONG_CONSTANT_NAME,
regular_long_identifier_name
);
// To this
format!("{REALLY_LONG_CONSTANT_NAME} did {ANOTHER_REALLY_LONG_CONSTANT_NAME} to {regular_long_identifier_name}");
```
I tried generating an automatic diff with `cargo clippy --fix` but it came out at:
```
250 files changed, 1209 insertions(+), 1469 deletions(-)
```
Which seems like a bad idea when we'd have to back-merge it to `capella` and `eip4844` 😱
Currently there is a race between receiving blocks and receiving light client optimistic updates (in unstable), which results in processing errors. This is a continuation of PR #3693 and seeks to progress on issue #3651
Add the parent_root to ReprocessQueueMessage::BlockImported so we can remove blocks from queue when a block arrives that has the same parent root. We use the parent root as opposed to the block_root because the LightClientOptimisticUpdate does not contain the block_root.
If light_client_optimistic_update.attested_header.canonical_root() != head_block.message().parent_root() then we queue the update. Otherwise we process immediately.
michaelsproul came up with this idea.
The code was heavily based off of the attestation reprocessing.
I have not properly tested this to see if it works as intended.
* Use eth1_withdrawal_credential in Some Test States
* Update beacon_node/genesis/src/interop.rs
Co-authored-by: Michael Sproul <micsproul@gmail.com>
* Update beacon_node/genesis/src/interop.rs
Co-authored-by: Michael Sproul <micsproul@gmail.com>
* Increase validator sizes
* Pick next sync committee message
Co-authored-by: Michael Sproul <micsproul@gmail.com>
Co-authored-by: Paul Hauner <paul@paulhauner.com>
* Import BLS to execution changes before Capella
* Test for BLS to execution change HTTP API
* Pack BLS to execution changes in LIFO order
* Remove unused var
* Clippy
## Proposed Changes
Another `tree-states` motivated PR, this adds `jemalloc` as the default allocator, with an option to use the system allocator by compiling with `FEATURES="" make`.
- [x] Metrics
- [x] Test on Windows
- [x] Test on macOS
- [x] Test with `musl`
- [x] Metrics dashboard on `lighthouse-metrics` (https://github.com/sigp/lighthouse-metrics/pull/37)
Co-authored-by: Michael Sproul <micsproul@gmail.com>
We recently ran a large-block experiment on the testnet and plan to do a further experiment on mainnet.
Although the metrics recovered from lighthouse nodes were quite useful, I think we could do with greater resolution in the block delay metrics and get some specific values for each block (currently these can be lost to large exponential histogram buckets).
This PR increases the resolution of the block delay histogram buckets, but also introduces a new metric which records the last block delay. Depending on the polling resolution of the metric server, we can lose some block delay information, however it will always give us a specific value and we will not lose exact data based on poor resolution histogram buckets.
## Issue Addressed
No issue has been raised for these broken links.
## Proposed Changes
Update links with the new URLs for the same document.
## Additional Info
~The link for the [Lighthouse Development Updates](https://eepurl.com/dh9Lvb/) mailing list is also broken, but I can't find the correct link.~
Co-authored-by: Paul Hauner <paul@paulhauner.com>
## Issue Addressed
#3853
## Proposed Changes
Added `INFO` level logs for requesting and receiving the unsigned block.
## Additional Info
Logging for successfully publishing the signed block is already there. And seemingly there is a log for when "We realize we are going to produce a block" in the `start_update_service`: `info!(log, "Block production service started");
`. Is there anywhere else you'd like to see logging around this event?
Co-authored-by: GeemoCandama <104614073+GeemoCandama@users.noreply.github.com>
## Issue Addressed
#3780
## Proposed Changes
Add error reporting that notifies the node operator that the `voting_keystore_path` in their `validator_definitions.yml` file may be incorrect.
## Additional Info
There is more info in issue #3780
Co-authored-by: Paul Hauner <paul@paulhauner.com>
## Proposed Changes
Decouple the stdout and logfile formats by adding the `--logfile-format` CLI flag.
This behaves identically to the existing `--log-format` flag, but instead will only affect the logs written to the logfile.
The `--log-format` flag will no longer have any effect on the contents of the logfile.
## Additional Info
This avoids being a breaking change by causing `logfile-format` to default to the value of `--log-format` if it is not provided.
This means that users who were previously relying on being able to use a JSON formatted logfile will be able to continue to use `--log-format JSON`.
Users who want to use JSON on stdout and default logs in the logfile, will need to pass the following flags: `--log-format JSON --logfile-format DEFAULT`
Issue #3112
Add `Filter::recover` to the GET chain to handle rejections specifically as 404 NOT FOUND
Making a request to `http://localhost:5052/not_real` now returns the following:
```
{
"code": 404,
"message": "NOT_FOUND",
"stacktraces": []
}
```
Co-authored-by: Paul Hauner <paul@paulhauner.com>
## Issue Addressed
Currently there is a race between receiving blocks and receiving light client optimistic updates (in unstable), which results in processing errors. This is a continuation of PR #3693 and seeks to progress on issue #3651
## Proposed Changes
Add the parent_root to ReprocessQueueMessage::BlockImported so we can remove blocks from queue when a block arrives that has the same parent root. We use the parent root as opposed to the block_root because the LightClientOptimisticUpdate does not contain the block_root.
If light_client_optimistic_update.attested_header.canonical_root() != head_block.message().parent_root() then we queue the update. Otherwise we process immediately.
## Additional Info
michaelsproul came up with this idea.
The code was heavily based off of the attestation reprocessing.
I have not properly tested this to see if it works as intended.
* Use eth1_withdrawal_credential in Some Test States
* Update beacon_node/genesis/src/interop.rs
Co-authored-by: Michael Sproul <micsproul@gmail.com>
* Update beacon_node/genesis/src/interop.rs
Co-authored-by: Michael Sproul <micsproul@gmail.com>
* Increase validator sizes
* Pick next sync committee message
Co-authored-by: Michael Sproul <micsproul@gmail.com>
Co-authored-by: Paul Hauner <paul@paulhauner.com>
* Import BLS to execution changes before Capella
* Test for BLS to execution change HTTP API
* Pack BLS to execution changes in LIFO order
* Remove unused var
* Clippy
## Proposed Changes
Another `tree-states` motivated PR, this adds `jemalloc` as the default allocator, with an option to use the system allocator by compiling with `FEATURES="" make`.
- [x] Metrics
- [x] Test on Windows
- [x] Test on macOS
- [x] Test with `musl`
- [x] Metrics dashboard on `lighthouse-metrics` (https://github.com/sigp/lighthouse-metrics/pull/37)
Co-authored-by: Michael Sproul <micsproul@gmail.com>
We recently ran a large-block experiment on the testnet and plan to do a further experiment on mainnet.
Although the metrics recovered from lighthouse nodes were quite useful, I think we could do with greater resolution in the block delay metrics and get some specific values for each block (currently these can be lost to large exponential histogram buckets).
This PR increases the resolution of the block delay histogram buckets, but also introduces a new metric which records the last block delay. Depending on the polling resolution of the metric server, we can lose some block delay information, however it will always give us a specific value and we will not lose exact data based on poor resolution histogram buckets.
## Issue Addressed
No issue has been raised for these broken links.
## Proposed Changes
Update links with the new URLs for the same document.
## Additional Info
~The link for the [Lighthouse Development Updates](https://eepurl.com/dh9Lvb/) mailing list is also broken, but I can't find the correct link.~
Co-authored-by: Paul Hauner <paul@paulhauner.com>
## Issue Addressed
#3853
## Proposed Changes
Added `INFO` level logs for requesting and receiving the unsigned block.
## Additional Info
Logging for successfully publishing the signed block is already there. And seemingly there is a log for when "We realize we are going to produce a block" in the `start_update_service`: `info!(log, "Block production service started");
`. Is there anywhere else you'd like to see logging around this event?
Co-authored-by: GeemoCandama <104614073+GeemoCandama@users.noreply.github.com>
## Issue Addressed
#3780
## Proposed Changes
Add error reporting that notifies the node operator that the `voting_keystore_path` in their `validator_definitions.yml` file may be incorrect.
## Additional Info
There is more info in issue #3780
Co-authored-by: Paul Hauner <paul@paulhauner.com>
## Proposed Changes
Decouple the stdout and logfile formats by adding the `--logfile-format` CLI flag.
This behaves identically to the existing `--log-format` flag, but instead will only affect the logs written to the logfile.
The `--log-format` flag will no longer have any effect on the contents of the logfile.
## Additional Info
This avoids being a breaking change by causing `logfile-format` to default to the value of `--log-format` if it is not provided.
This means that users who were previously relying on being able to use a JSON formatted logfile will be able to continue to use `--log-format JSON`.
Users who want to use JSON on stdout and default logs in the logfile, will need to pass the following flags: `--log-format JSON --logfile-format DEFAULT`
## Issue Addressed
Issue #3112
## Proposed Changes
Add `Filter::recover` to the GET chain to handle rejections specifically as 404 NOT FOUND
## Additional Info
Making a request to `http://localhost:5052/not_real` now returns the following:
```
{
"code": 404,
"message": "NOT_FOUND",
"stacktraces": []
}
```
Co-authored-by: Paul Hauner <paul@paulhauner.com>
* add historical summaries
* fix tree hash caching, disable the sanity slots test with fake crypto
* add ssz static HistoricalSummary
* only store historical summaries after capella
* Teach `UpdatePattern` about Capella
* Tidy EF tests
* Clippy
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
## Proposed Changes
Update all dependencies to new semver-compatible releases with `cargo update`. Importantly this patches a Tokio vuln: https://rustsec.org/advisories/RUSTSEC-2023-0001. I don't think we were affected by the vuln because it only applies to named pipes on Windows, but it's still good hygiene to patch.
## Issue Addressed
NA
## Proposed Changes
Myself and others (#3678) have observed that when running with lots of validators (e.g., 1000s) the cardinality is too much for Prometheus. I've seen Prometheus instances just grind to a halt when we turn the validator monitor on for our testnet validators (we have 10,000s of Goerli validators). Additionally, the debug log volume can get very high with one log per validator, per attestation.
To address this, the `bn --validator-monitor-individual-tracking-threshold <INTEGER>` flag has been added to *disable* per-validator (i.e., non-aggregated) metrics/logging once the validator monitor exceeds the threshold of validators. The default value is `64`, which is a finger-to-the-wind value. I don't actually know the value at which Prometheus starts to become overwhelmed, but I've seen it work with ~64 validators and I've seen it *not* work with 1000s of validators. A default of `64` seems like it will result in a breaking change to users who are running millions of dollars worth of validators whilst resulting in a no-op for low-validator-count users. I'm open to changing this number, though.
Additionally, this PR starts collecting aggregated Prometheus metrics (e.g., total count of head hits across all validators), so that high-validator-count validators still have some interesting metrics. We already had logging for aggregated values, so nothing has been added there.
I've opted to make this a breaking change since it can be rather damaging to your Prometheus instance to accidentally enable the validator monitor with large numbers of validators. I've crashed a Prometheus instance myself and had a report from another user who's done the same thing.
## Additional Info
NA
## Breaking Changes Note
A new label has been added to the validator monitor Prometheus metrics: `total`. This label tracks the aggregated metrics of all validators in the validator monitor (as opposed to each validator being tracking individually using its pubkey as the label).
Additionally, a new flag has been added to the Beacon Node: `--validator-monitor-individual-tracking-threshold`. The default value is `64`, which means that when the validator monitor is tracking more than 64 validators then it will stop tracking per-validator metrics and only track the `all_validators` metric. It will also stop logging per-validator logs and only emit aggregated logs (the exception being that exit and slashing logs are always emitted).
These changes were introduced in #3728 to address issues with untenable Prometheus cardinality and log volume when using the validator monitor with high validator counts (e.g., 1000s of validators). Users with less than 65 validators will see no change in behavior (apart from the added `all_validators` metric). Users with more than 65 validators who wish to maintain the previous behavior can set something like `--validator-monitor-individual-tracking-threshold 999999`.
## Issue Addressed
Recent discussions with other client devs about optimistic sync have revealed a conceptual issue with the optimisation implemented in #3738. In designing that feature I failed to consider that the execution node checks the `blockHash` of the execution payload before responding with `SYNCING`, and that omitting this check entirely results in a degradation of the full node's validation. A node omitting the `blockHash` checks could be tricked by a supermajority of validators into following an invalid chain, something which is ordinarily impossible.
## Proposed Changes
I've added verification of the `payload.block_hash` in Lighthouse. In case of failure we log a warning and fall back to verifying the payload with the execution client.
I've used our existing dependency on `ethers_core` for RLP support, and a new dependency on Parity's `triehash` crate for the Merkle patricia trie. Although the `triehash` crate is currently unmaintained it seems like our best option at the moment (it is also used by Reth, and requires vastly less boilerplate than Parity's generic `trie-root` library).
Block hash verification is pretty quick, about 500us per block on my machine (mainnet).
The optimistic finalized sync feature can be disabled using `--disable-optimistic-finalized-sync` which forces full verification with the EL.
## Additional Info
This PR also introduces a new dependency on our [`metastruct`](https://github.com/sigp/metastruct) library, which was perfectly suited to the RLP serialization method. There will likely be changes as `metastruct` grows, but I think this is a good way to start dogfooding it.
I took inspiration from some Parity and Reth code while writing this, and have preserved the relevant license headers on the files containing code that was copied and modified.
I've needed to do this work in order to do some episub testing.
This version of libp2p has not yet been released, so this is left as a draft for when we wish to update.
Co-authored-by: Diva M <divma@protonmail.com>
Our custom RPC implementation is lagging from the libp2p v50 version.
We are going to need to change a bunch of function names and would be nice to have consistent ordering of function names inside the handlers.
This is a precursor to the libp2p upgrade to minimize merge conflicts in function ordering.
- there was a bug in responding range blob requests where we would incorrectly label the first slot of an epoch as a non-skipped slot if it were skipped. this bug did not exist in the code for responding to block range request because the logic error was mitigated by defensive coding elsewhere
- there was a bug where a block received during range sync without a corresponding blob (and vice versa) was incorrectly interpreted as a stream termination
- RPC size limit fixes.
- Our blob cache was dead locking so I removed use of it for now.
- Because of our change in finalized sync batch size from 2 to 1 and our transition to using exact epoch boundaries for batches (rather than one slot past the epoch boundary), we need to sync finalized sync to 2 epochs + 1 slot past our peer's finalized slot in order to finalize the chain locally.
- use fork context bytes in rpc methods on both the server and client side
The notion of "phases" doesn't exist anymore in the Ethereum roadmap. Also fix dead link to roadmap.
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Issue Addressed
While testing withdrawals with @ethDreamer we noticed lighthouse is sending empty batches when an error occurs. As LH peer receiving this, we would consider this a low tolerance action because the peer is claiming the batch is right and is empty.
## Proposed Changes
If any kind of error occurs, send a error response instead
## Additional Info
Right now we don't handle such thing as a partial batch with an error. If an error is received, the whole batch is discarded. Because of this it makes little sense to send partial batches that end with an error, so it's better to do the proposed solution instead of sending empty batches.
## Proposed Changes
Update the Gnosis chain bootnodes. The current list of Gnosis bootnodes were abandoned at some point before the Gnosis merge and are now failing to bootstrap peers. There's a workaround list of bootnodes here: https://docs.gnosischain.com/updates/20221208-temporary-bootnodes
The list from this PR represents the long-term bootnodes run by the Gnosis team. We will also try to set up SigP bootnodes for Gnosis chain at some point.
## Proposed Changes
With proposer boosting implemented (#2822) we have an opportunity to re-org out late blocks.
This PR adds three flags to the BN to control this behaviour:
* `--disable-proposer-reorgs`: turn aggressive re-orging off (it's on by default).
* `--proposer-reorg-threshold N`: attempt to orphan blocks with less than N% of the committee vote. If this parameter isn't set then N defaults to 20% when the feature is enabled.
* `--proposer-reorg-epochs-since-finalization N`: only attempt to re-org late blocks when the number of epochs since finalization is less than or equal to N. The default is 2 epochs, meaning re-orgs will only be attempted when the chain is finalizing optimally.
For safety Lighthouse will only attempt a re-org under very specific conditions:
1. The block being proposed is 1 slot after the canonical head, and the canonical head is 1 slot after its parent. i.e. at slot `n + 1` rather than building on the block from slot `n` we build on the block from slot `n - 1`.
2. The current canonical head received less than N% of the committee vote. N should be set depending on the proposer boost fraction itself, the fraction of the network that is believed to be applying it, and the size of the largest entity that could be hoarding votes.
3. The current canonical head arrived after the attestation deadline from our perspective. This condition was only added to support suppression of forkchoiceUpdated messages, but makes intuitive sense.
4. The block is being proposed in the first 2 seconds of the slot. This gives it time to propagate and receive the proposer boost.
## Additional Info
For the initial idea and background, see: https://github.com/ethereum/consensus-specs/pull/2353#issuecomment-950238004
There is also a specification for this feature here: https://github.com/ethereum/consensus-specs/pull/3034
Co-authored-by: Michael Sproul <micsproul@gmail.com>
Co-authored-by: pawan <pawandhananjay@gmail.com>
## Issue Addressed
NA
## Proposed Changes
This is a *potentially* contentious change, but I find it annoying that the validator monitor logs `WARN` and `ERRO` for imperfect attestations. Perfect attestation performance is unachievable (don't believe those photo-shopped beauty magazines!) since missed and poorly-packed blocks by other validators will reduce your performance.
When the validator monitor is on with 10s or more validators, I find the logs are washed out with ERROs that are not worth investigating. I suspect that users who really want to know if validators are missing attestations can do so by matching the content of the log, rather than the log level.
I'm open to feedback about this, especially from anyone who is relying on the current log levels.
## Additional Info
NA
## Breaking Changes Notes
The validator monitor will no longer emit `WARN` and `ERRO` logs for sub-optimal attestation performance. The logs will now be emitted at `INFO` level. This change was introduced to avoid cluttering the `WARN` and `ERRO` logs with alerts that are frequently triggered by the actions of other network participants (e.g., a missed block) and require no action from the user.
## Issue Addressed
Implementing the light_client_gossip topics but I'm not there yet.
Which issue # does this PR address?
Partially #3651
## Proposed Changes
Add light client gossip topics.
Please list or describe the changes introduced by this PR.
I'm going to Implement light_client_finality_update and light_client_optimistic_update gossip topics. Currently I've attempted the former and I'm seeking feedback.
## Additional Info
I've only implemented the light_client_finality_update topic because I wanted to make sure I was on the correct path. Also checking that the gossiped LightClientFinalityUpdate is the same as the locally constructed one is not implemented because caching the updates will make this much easier. Could someone give me some feedback on this please?
Please provide any additional information. For example, future considerations
or information useful for reviewers.
Co-authored-by: GeemoCandama <104614073+GeemoCandama@users.noreply.github.com>
## Issue Addressed
NA
## Proposed Changes
In #3725 I introduced a `CRIT` log for unrevealed payloads, against @michaelsproul's [advice](https://github.com/sigp/lighthouse/pull/3725#discussion_r1034142113). After being woken up in the middle of the night by a block that was not revealed to the BN but *was* revealed to the network, I have capitulated. This PR implements @michaelsproul's suggestion and reduces the severity to `ERRO`.
Additionally, I have dropped a `CRIT` to an `ERRO` for when a block is published late. The block in question was indeed published late on the network, however now that we have builders that can slow down block production I don't think the error is "actionable" enough to warrant a `CRIT` for the user.
## Additional Info
NA
## Issue Addressed
#3766
## Proposed Changes
Adds an endpoint to get the graffiti that will be used for the next block proposal for each validator.
## Usage
```bash
curl -H "Authorization: Bearer api-token" http://localhost:9095/lighthouse/ui/graffiti | jq
```
```json
{
"data": {
"0x81283b7a20e1ca460ebd9bbd77005d557370cabb1f9a44f530c4c4c66230f675f8df8b4c2818851aa7d77a80ca5a4a5e": "mr f was here",
"0xa3a32b0f8b4ddb83f1a0a853d81dd725dfe577d4f4c3db8ece52ce2b026eca84815c1a7e8e92a4de3d755733bf7e4a9b": "mr v was here",
"0x872c61b4a7f8510ec809e5b023f5fdda2105d024c470ddbbeca4bc74e8280af0d178d749853e8f6a841083ac1b4db98f": null
}
}
```
## Additional Info
This will only return graffiti that the validator client knows about.
That is from these 3 sources:
1. Graffiti File
2. validator_definitions.yml
3. The `--graffiti` flag on the VC
If the graffiti is set on the BN, it will not be returned. This may warrant an additional endpoint on the BN side which can be used in the event the endpoint returns `null`.
## Proposed Changes
Adds docs for the following endpoints:
- `/lighthouse/analysis/attestation_performance`
- `/lighthouse/analysis/block_packing_efficiency`
## Issue Addressed
#3724
## Proposed Changes
Exposes certain `validator_monitor` as an endpoint on the HTTP API. Will only return metrics for validators which are actively being monitored.
### Usage
```bash
curl -X GET "http://localhost:5052/lighthouse/ui/validator_metrics" -H "accept: application/json" | jq
```
```json
{
"data": {
"validators": {
"12345": {
"attestation_hits": 10,
"attestation_misses": 0,
"attestation_hit_percentage": 100,
"attestation_head_hits": 10,
"attestation_head_misses": 0,
"attestation_head_hit_percentage": 100,
"attestation_target_hits": 5,
"attestation_target_misses": 5,
"attestation_target_hit_percentage": 50
}
}
}
}
```
## Additional Info
Based on #3756 which should be merged first.
* Add API endpoint to count statuses of all validators (#3756)
* Delete DB schema migrations for v11 and earlier (#3761)
Co-authored-by: Mac L <mjladson@pm.me>
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
## Proposed Changes
Now that the Gnosis merge is scheduled, all users should have upgraded beyond Lighthouse v3.0.0. Accordingly we can delete schema migrations for versions prior to v3.0.0.
## Additional Info
I also deleted the state cache stuff I added in #3714 as it turned out to be useless for the light client proofs due to the one-slot offset.
## Issue Addressed
#3724
## Proposed Changes
Adds an endpoint to quickly count the number of occurances of each status in the validator set.
## Usage
```bash
curl -X GET "http://localhost:5052/lighthouse/ui/validator_count" -H "accept: application/json" | jq
```
```json
{
"data": {
"active_ongoing":479508,
"active_exiting":0,
"active_slashed":0,
"pending_initialized":28,
"pending_queued":0,
"withdrawal_possible":933,
"withdrawal_done":0,
"exited_unslashed":0,
"exited_slashed":3
}
}
```
## Issue Addressed
Closes https://github.com/sigp/lighthouse/issues/2327
## Proposed Changes
This is an extension of some ideas I implemented while working on `tree-states`:
- Cache the indexed attestations from blocks in the `ConsensusContext`. Previously we were re-computing them 3-4 times over.
- Clean up `import_block` by splitting each part into `import_block_XXX`.
- Move some stuff off hot paths, specifically:
- Relocate non-essential tasks that were running between receiving the payload verification status and priming the early attester cache. These tasks are moved after the cache priming:
- Attestation observation
- Validator monitor updates
- Slasher updates
- Updating the shuffling cache
- Fork choice attestation observation now happens at the end of block verification in parallel with payload verification (this seems to save 5-10ms).
- Payload verification now happens _before_ advancing the pre-state and writing it to disk! States were previously being written eagerly and adding ~20-30ms in front of verifying the execution payload. State catchup also sometimes takes ~500ms if we get a cache miss and need to rebuild the tree hash cache.
The remaining task that's taking substantial time (~20ms) is importing the block to fork choice. I _think_ this is because of pull-tips, and we should be able to optimise it out with a clever total active balance cache in the state (which would be computed in parallel with payload verification). I've decided to leave that for future work though. For now it can be observed via the new `beacon_block_processing_post_exec_pre_attestable_seconds` metric.
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Issue Addressed
our bootnodes as of now support only ipv4. this makes it so that they support ipv6
## Proposed Changes
- Adds code necessary to update the bootnodes to run on dual stack nodes and therefore contact and store ipv6 nodes.
- Adds some metrics about connectivity type of stored peers. It might have been nice to see some metrics over the sessions but that feels out of scope right now.
## Additional Info
- some code quality improvements sneaked in since the changes seemed small
- I think it depends on the OS, but enabling mapped addresses on an ipv6 node without dual stack support enabled could fail silently, making these nodes effectively ipv6 only. In the future I'll probably change this to use two sockets, which should fail loudly
## Issue Addressed
#3704
## Proposed Changes
Adds is_syncing_finalized: bool parameter for block verification functions. Sets the payload_verification_status to Optimistic if is_syncing_finalized is true. Uses SyncState in NetworkGlobals in BeaconProcessor to retrieve the syncing status.
## Additional Info
I could implement FinalizedSignatureVerifiedBlock if you think it would be nicer.
## Issue Addressed
NA
## Proposed Changes
This PR sets out to improve the logging/metrics experience when interacting with the builder. Namely, it:
- Adds/changes metrics (see "Metrics Changes" section).
- Adds new logs which show the duration of requests to the builder/local EL.
- Refactors existing logs for consistency and so that the `parent_hash` is include in all relevant logs (we can grep for this field when trying to trace the flow of block production).
Additionally, when I was implementing this PR I noticed that we skip some verification of the builder payload in the scenario where the builder return `Ok` but the local EL returns with `Err`. Namely, we were skipping the bid signature and other values like parent hash and prev randao. In this PR I've changed it so we *always* check these values and reject the bid if they're incorrect. With these changes, we'll sometimes choose to skip a proposal rather than propose something invalid -- that's the only side-effect to the changes that I can see.
## Metrics Changes
- Changed: `execution_layer_request_times`:
- `method = "get_blinded_payload_local"`: time taken to get a payload from a local EE.
- `method = "get_blinded_payload_builder"`: time taken to get a blinded payload from a builder.
- `method = "post_blinded_payload_builder"`: time taken to get a builder to reveal a payload they've previously supplied us.
- `execution_layer_get_payload_outcome`
- `outcome = "success"`: we successfully produced a payload from a builder or local EE.
- `outcome = "failure"`: we were unable to get a payload from a builder or local EE.
- New: `execution_layer_builder_reveal_payload_outcome`
- `outcome = "success"`: a builder revealed a payload from a signed, blinded block.
- `outcome = "failure"`: the builder did not reveal the payload.
- New: `execution_layer_get_payload_source`
- `type = "builder"`: we used a payload from a builder to produce a block.
- `type = "local"`: we used a payload from a local EE to produce a block.
- New: `execution_layer_get_payload_builder_rejections` has a `reason` field to describe why we rejected a payload from a builder.
- New: `execution_layer_payload_bids` tracks the bid (in gwei) from the builder or local EE (local EE not yet supported, waiting on EEs to expose the value). Can only record values that fit inside an i64 (roughly 9 million ETH).
## Additional Info
NA
## Issue Addressed
Related to #3672
## Proposed Changes
- Added a guide to run a node. Mainly, copy and paste from 'Merge Migration' and 'Checkpoint Sync'.
- Ranked it high in ToC:
- Introduction
- Installation
- Run a Node
- Become a Validator
...
- Hid 'Merge Migration' in ToC.
## Additional Info
- Should I add/rephrase/delete something?
- Now there is some redundancy:
- 'Run a node' and 'Checkpoint Sync' contain similar information.
- Same for 'Run a node' and 'Become a Validator'.
Co-authored-by: kevinbogner <114221396+kevinbogner@users.noreply.github.com>
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Issue Addressed
#3723
## Proposed Changes
Adds a new CLI flag `--gui` which enables all the various flags required for the gui to function properly.
Currently enables the `--http` and `--validator-monitor-auto` flags.
## Issue Addressed
#3732
## Proposed Changes
Add a CLI flag to allow users to opt out of the restrictive permissions of the log files.
## Additional Info
This is not recommended for most users. The log files can contain sensitive information such as validator indices, public keys and API tokens (see #2438). However some users using a multi-user setup may find this helpful if they understand the risks involved.
## Issue Addressed
Partially addresses #3651
## Proposed Changes
Adds server-side support for light_client_bootstrap_v1 topic
## Additional Info
This PR, creates each time a bootstrap without using cache, I do not know how necessary a cache is in this case as this topic is not supposed to be called frequently and IMHO we can just prevent abuse by using the limiter, but let me know what you think or if there is any caveat to this, or if it is necessary only for the sake of good practice.
Co-authored-by: Pawan Dhananjay <pawandhananjay@gmail.com>
* add a rt is_blob_batch
* use the mixed type everywhere
* glue
* more glue
* minor fixes
* fix range tests
* filling in the gaps
* moore filling in the gaps
## Issue Addressed
NA
## Proposed Changes
- Bump versions
- Pin the `nethermind` version since our method of getting the latest tags on `master` is giving us an old version (`1.14.1`).
- Increase timeout for execution engine startup.
## Additional Info
- [x] ~Awaiting further testing~
## Issue Addressed
Partially addresses #3707
## Proposed Changes
Drop `ERRO` log to `WARN` until we identify the exact conditions that lead to this case.
Add a message which hopefully reassures users who only see this log once 😅
Add the block hash to the error message in case it will prove useful in debugging the root cause.
## Issue Addressed
<!--Which issue # does this PR address?-->
Removed some unnecessary `mut`. 🙂
<!--
## Proposed Changes
Please list or describe the changes introduced by this PR.
-->
<!--
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
-->
## Proposed Changes
With a few different changes to the gossip topics in flight (light clients, Capella, 4844, etc) I think this simplification makes sense. I noticed it while plumbing through a new Capella topic.
## Issue Addressed
Closes#3709
## Proposed Changes
Add the job `compile-with-beta-compiler` to `test-suite`. This job has the following steps:
1. Use `actions/checkout@v3`. (Needed to run make in a later step.)
2. Install the dependencies listed in [build from source guide](https://lighthouse-book.sigmaprime.io/installation-source.html).
3. Change the compiler to the current beta version with `rustup override`.
4. Run `make`.
This PR adds some health endpoints for the beacon node and the validator client.
Specifically it adds the endpoint:
`/lighthouse/ui/health`
These are not entirely stable yet. But provide a base for modification for our UI.
These also may have issues with various platforms and may need modification.
## Issue Addressed
Closes https://github.com/sigp/lighthouse/issues/3656
## Proposed Changes
* Replace `set-output` by `$GITHUB_OUTPUT` usage
* Avoid rate-limits when installing `protoc` by making authenticated requests (continuation of https://github.com/sigp/lighthouse/pull/3621)
* Upgrade all Ubuntu 18.04 usage to 22.04 (18.04 is end of life)
* Upgrade macOS-latest to explicit macOS-12 to silence warning
* Use `actions/checkout@v3` and `actions/cache@v3` to avoid deprecated NodeJS v12
## Additional Info
Can't silence the NodeJS warnings entirely due to https://github.com/sigp/lighthouse/issues/3705. Can fix that in future.
## Issue Addressed
Closes#3612
## Proposed Changes
- Iterates through BNs until it finds a non-optimistic head.
A slight change in error behavior:
- Previously: `spawn_contribution_tasks` did not return an error for a non-optimistic block head. It returned `Ok(())` logged a warning.
- Now: `spawn_contribution_tasks` returns an error if it cannot find a non-optimistic block head. The caller of `spawn_contribution_tasks` then logs the error as a critical error.
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Issue Addressed
Part of https://github.com/sigp/lighthouse/issues/3651.
## Proposed Changes
Add a flag for enabling the light client server, which should be checked before gossip/RPC traffic is processed (e.g. https://github.com/sigp/lighthouse/pull/3693, https://github.com/sigp/lighthouse/pull/3711). The flag is available at runtime from `beacon_chain.config.enable_light_client_server`.
Additionally, a new method `BeaconChain::with_mutable_state_for_block` is added which I envisage being used for computing light client updates. Unfortunately its performance will be quite poor on average because it will only run quickly with access to the tree hash cache. Each slot the tree hash cache is only available for a brief window of time between the head block being processed and the state advance at 9s in the slot. When the state advance happens the cache is moved and mutated to get ready for the next slot, which makes it no longer useful for merkle proofs related to the head block. Rather than spend more time trying to optimise this I think we should continue prototyping with this code, and I'll make sure `tree-states` is ready to ship before we enable the light client server in prod (cf. https://github.com/sigp/lighthouse/pull/3206).
## Additional Info
I also fixed a bug in the implementation of `BeaconState::compute_merkle_proof` whereby the tree hash cache was moved with `.take()` but never put back with `.restore()`.
## Issue Addressed
#3702
Which issue # does this PR address?
#3702
## Proposed Changes
Added checkpoint-sync-url-timeout flag to cli. Added timeout field to ClientGenesis::CheckpointSyncUrl to utilize timeout set
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
Co-authored-by: GeemoCandama <104614073+GeemoCandama@users.noreply.github.com>
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Issue Addressed
Closes#3460
## Proposed Changes
`blocks` and `block_min_delay` are never updated in the epoch summary
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Issue Addressed
This PR addresses partially #3651
## Proposed Changes
This PR adds the following methods:
* a new method to trait `TreeHash`, `hash_tree_leaves` which returns all the Merkle leaves of the ssz object.
* a new method to `BeaconState`: `compute_merkle_proof` which generates a specific merkle proof for given depth and index by using the `hash_tree_leaves` as leaves function.
## Additional Info
Now here is some rationale on why I decided to go down this route: adding a new function to commonly used trait is a pain but was necessary to make sure we have all merkle leaves for every object, that is why I just added `hash_tree_leaves` in the trait and not `compute_merkle_proof` as well. although it would make sense it gives us code duplication/harder review time and we just need it from one specific object in one specific usecase so not worth the effort YET. In my humble opinion.
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Issue Addressed
Which issue # does this PR address?
## Proposed Changes
* Add v3.2 and v3.3 to database migrations table
* Remove docs on `--subscribe-all-subnets` and `--import-all-attestations` from redundancy docs
* Clarify that the merge has already occurred on the merge migration page
## Issue Addressed
NA
## Proposed Changes
Adds clarification to an error log when there is an error submitting a validator registration.
There seems to be a few cases where relays return errors during validator registration, including spurious timeouts and when a validator has been very recently activated/made pending.
Changing this log helps indicate that it's "just another registration error" rather than something more serious. I didn't drop this to a `WARN` since I still have hope we can eliminate these errors completely by chatting with relays and adjusting timeouts.
## Additional Info
NA
## Issue Addressed
New lints for rust 1.65
## Proposed Changes
Notable change is the identification or parameters that are only used in recursion
## Additional Info
na
## Summary
The deposit cache now has the ability to finalize deposits. This will cause it to drop unneeded deposit logs and hashes in the deposit Merkle tree that are no longer required to construct deposit proofs. The cache is finalized whenever the latest finalized checkpoint has a new `Eth1Data` with all deposits imported.
This has three benefits:
1. Improves the speed of constructing Merkle proofs for deposits as we can just replay deposits since the last finalized checkpoint instead of all historical deposits when re-constructing the Merkle tree.
2. Significantly faster weak subjectivity sync as the deposit cache can be transferred to the newly syncing node in compressed form. The Merkle tree that stores `N` finalized deposits requires a maximum of `log2(N)` hashes. The newly syncing node then only needs to download deposits since the last finalized checkpoint to have a full tree.
3. Future proofing in preparation for [EIP-4444](https://eips.ethereum.org/EIPS/eip-4444) as execution nodes will no longer be required to store logs permanently so we won't always have all historical logs available to us.
## More Details
Image to illustrate how the deposit contract merkle tree evolves and finalizes along with the resulting `DepositTreeSnapshot`

## Other Considerations
I've changed the structure of the `SszDepositCache` so once you load & save your database from this version of lighthouse, you will no longer be able to load it from older versions.
Co-authored-by: ethDreamer <37123614+ethDreamer@users.noreply.github.com>
## Issue Addressed
Updates discv5
Pending on
- [x] #3547
- [x] Alex upgrades his deps
## Proposed Changes
updates discv5 and the enr crate. The only relevant change would be some clear indications of ipv4 usage in lighthouse
## Additional Info
Functionally, this should be equivalent to the prev version.
As draft pending a discv5 release
## Issue Addressed
There are few spelling and grammar errors in the book.
## Proposed Changes
Corrected those spelling and grammar errors in the below files
- book/src/advanced-release-candidates.md
- book/src/advanced_networking.md
- book/src/builders.md
- book/src/key-management.md
- book/src/merge-migration.md
- book/src/wallet-create.md
Co-authored-by: Kausik Das <kausik007007@gmail.com>
Co-authored-by: Kausik Das ✪ <kausik007007@gmail.com>
## Issue Addressed
This PR partially addresses #3651
## Proposed Changes
This PR adds the following containers types from [the lightclient specs](https://github.com/ethereum/consensus-specs/blob/dev/specs/altair/light-client/sync-protocol.md): `LightClientUpdate`, `LightClientFinalityUpdate`, `LightClientOptimisticUpdate` and `LightClientBootstrap`. It also implements the creation of each updates as delined by this [document](https://github.com/ethereum/consensus-specs/blob/dev/specs/altair/light-client/full-node.md).
## Additional Info
Here is a brief description of what each of these container signify:
`LightClientUpdate`: This container is only provided by server (full node) to lightclients when catching up new sync committees beetwen periods and we want possibly one lightclient update ready for each post-altair period the lighthouse node go over. it is needed in the resp/req in method `light_client_update_by_range`.
`LightClientFinalityUpdate/LightClientFinalityUpdate`: Lighthouse will need only the latest of each of this kind of updates, so no need to store them in the database, we can just store the latest one of each one in memory and then just supply them via gossip or respreq, only the latest ones are served by a full node. finality updates marks the transition to a new finalized header, while optimistic updates signify new non-finalized header which are imported optimistically.
`LightClientBootstrap`: This object is retrieved by lightclients during the bootstrap process after a finalized checkpoint is retrieved, ideally we want to store a LightClientBootstrap for each finalized root and then serve each of them by finalized root in respreq protocol id `light_client_bootstrap`.
Little digression to how we implement the creation of each updates: the creation of a optimistic/finality update is just a version of the lightclient_update creation mechanism with less fields being set, there is underlying concept of inheritance, if you look at the specs it becomes very obvious that a lightclient update is just an extension of a finality update and a finality update an extension to an optimistic update.
## Extra note
`LightClientStore` is not implemented as it is only useful as internal storage design for the lightclient side.
* add capella gossip boiler plate
* get everything compiling
Co-authored-by: realbigsean <sean@sigmaprime.io
Co-authored-by: Mark Mackey <mark@sigmaprime.io>
* small cleanup
* small cleanup
* cargo fix + some test cleanup
* improve block production
* add fixme for potential panic
Co-authored-by: Mark Mackey <mark@sigmaprime.io>
## Issue Addressed
This reverts commit ca9dc8e094 (PR #3559) with some modifications.
## Proposed Changes
Unfortunately that PR introduced a performance regression in fork choice. The optimisation _intended_ to build the exit and pubkey caches on the head state _only if_ they were not already built. However, due to the head state always being cloned without these caches, we ended up building them every time the head changed, leading to a ~70ms+ penalty on mainnet.
fcfd02aeec/beacon_node/beacon_chain/src/canonical_head.rs (L633-L636)
I believe this is a severe enough regression to justify immediately releasing v3.2.1 with this change.
## Additional Info
I didn't fully revert #3559, because there were some unrelated deletions of dead code in that PR which I figured we may as well keep.
An alternative would be to clone the extra caches, but this likely still imposes some cost, so in the interest of applying a conservative fix quickly, I think reversion is the best approach. The optimisation from #3559 was not even optimising a particularly significant path, it was mostly for VCs running larger numbers of inactive keys. We can re-do it in the `tree-states` world where cache clones are cheap.
## Issue Addressed
NA
## Proposed Changes
Bump version to `v3.2.0`
## Additional Info
- ~~Blocked on #3597~~
- ~~Blocked on #3645~~
- ~~Blocked on #3653~~
- ~~Requires additional testing~~
## Issue Addressed
I missed this from https://github.com/sigp/lighthouse/pull/3491. peers were being banned at the behaviour level only. The identify errors are explained by this as well
## Proposed Changes
Add banning and unbanning
## Additional Info
Befor,e having tests that catch this was hard because the swarm was outside the behaviour. We could now have tests that prevent something like this in the future
## Issue Addressed
I noticed that [this build](https://github.com/sigp/lighthouse/actions/runs/3269950873/jobs/5378036501) wasn't marked failed by Bors when the `syncing-simulator-ubuntu` job failed. This is because that job is absent from the `bors.toml` config.
## Proposed Changes
Add missing jobs to Bors config so that they are required:
- `syncing-simulator-ubuntu`
- `slasher-tests`
- `disallowed-from-async-lint`
The `disallowed-from-async-lint` was previously allowed to fail because it was considered beta, but I think it's stable enough now we may as well require it.
Overrides any previous option that enables the eth1 service.
Useful for operating a `light` beacon node.
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Issue Addressed
Add flag to lengthen execution layer timeouts
Which issue # does this PR address?
#3607
## Proposed Changes
Added execution-timeout-multiplier flag and a cli test to ensure the execution layer config has the multiplier set correctly.
Please list or describe the changes introduced by this PR.
Add execution_timeout_multiplier to the execution layer config as Option<u32> and pass the u32 to HttpJsonRpc.
## Additional Info
Not certain that this is the best way to implement it so I'd appreciate any feedback.
Please provide any additional information. For example, future considerations
or information useful for reviewers.
## Issue Addressed
Fix a bug in block production that results in blocks with 0 attestations during the first slot of an epoch.
The bug is marked by debug logs of the form:
> DEBG Discarding attestation because of missing ancestor, block_root: 0x3cc00d9c9e0883b2d0db8606278f2b8423d4902f9a1ee619258b5b60590e64f8, pivot_slot: 4042591
It occurs when trying to look up the shuffling decision root for an attestation from a slot which is prior to fork choice's finalized block. This happens frequently when proposing in the first slot of the epoch where we have:
- `current_epoch == n`
- `attestation.data.target.epoch == n - 1`
- attestation shuffling epoch `== n - 3` (decision block being the last block of `n - 3`)
- `state.finalized_checkpoint.epoch == n - 2` (first block of `n - 2` is finalized)
Hence the shuffling decision slot is out of range of the fork choice backwards iterator _by a single slot_.
Unfortunately this bug was hidden when we weren't pruning fork choice, and then reintroduced in v2.5.1 when we fixed the pruning (https://github.com/sigp/lighthouse/releases/tag/v2.5.1). There's no way to turn that off or disable the filtering in our current release, so we need a new release to fix this issue.
Fortunately, it also does not occur on every epoch boundary because of the gradual pruning of fork choice every 256 blocks (~8 epochs):
01e84b71f5/consensus/proto_array/src/proto_array_fork_choice.rs (L16)01e84b71f5/consensus/proto_array/src/proto_array.rs (L713-L716)
So the probability of proposing a 0-attestation block given a proposal assignment is approximately `1/32 * 1/8 = 0.39%`.
## Proposed Changes
- Load the block's shuffling ID from fork choice and verify it against the expected shuffling ID of the head state. This code was initially written before we had settled on a representation of shuffling IDs, so I think it's a nice simplification to make use of them here rather than more ad-hoc logic that fundamentally does the same thing.
## Additional Info
Thanks to @moshe-blox for noticing this issue and bringing it to our attention.
## Issue Addressed
Closes https://github.com/sigp/lighthouse/issues/2371
## Proposed Changes
Backport some changes from `tree-states` that remove duplicated calculations of the `proposer_index`.
With this change the proposer index should be calculated only once for each block, and then plumbed through to every place it is required.
## Additional Info
In future I hope to add more data to the consensus context that is cached on a per-epoch basis, like the effective balances of validators and the base rewards.
There are some other changes to remove indexing in tests that were also useful for `tree-states` (the `tree-states` types don't implement `Index`).
## Issue Addressed
Implements new optimistic sync test format from https://github.com/ethereum/consensus-specs/pull/2982.
## Proposed Changes
- Add parsing and runner support for the new test format.
- Extend the mock EL with a set of canned responses keyed by block hash. Although this doubles up on some of the existing functionality I think it's really nice to use compared to the `preloaded_responses` or static responses. I think we could write novel new opt sync tests using these primtives much more easily than the previous ones. Forks are natively supported, and different responses to `forkchoiceUpdated` and `newPayload` are also straight-forward.
## Additional Info
Blocked on merge of the spec PR and release of new test vectors.
## Issue Addressed
While digging around in some logs I noticed that queries for validators by pubkey were taking 10ms+, which seemed too long. This was due to a loop through the entire validator registry for each lookup.
## Proposed Changes
Rather than using a loop through the register, this PR utilises the pubkey cache which is usually initialised at the head*. In case the cache isn't built, we fall back to the previous loop logic. In the vast majority of cases I expect the cache will be built, as the validator client queries at the `head` where all caches should be built.
## Additional Info
*I had to modify the cache build that runs after fork choice to build the pubkey cache. I think it had been optimised out, perhaps accidentally. I think it's preferable to have the exit cache and the pubkey cache built on the head state, as they are required for verifying deposits and exits respectively, and we may as well build them off the hot path of block processing. Previously they'd get built the first time a deposit or exit needed to be verified.
I've deleted the unused `map_state` function which was obsoleted by `map_state_and_execution_optimistic`.
## Issue Addressed
Which issue # does this PR address?
#2629
## Proposed Changes
Please list or describe the changes introduced by this PR.
1. ci would dowload the bls test cases from https://github.com/ethereum/bls12-381-tests/
2. all the bls test cases(except eth ones) would use cases in the archive from step one
3. The bls test cases from https://github.com/ethereum/consensus-spec-tests would stay there and no use . For the future , these bls test cases would be remove suggested from https://github.com/ethereum/consensus-spec-tests/issues/25 . So it would do no harm and compatible for future cases.
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
Question:
I am not sure if I should implement tests about `deserialization_G1`, `deserialization_G2` and `hash_to_G2` for the issue.
## Proposed Changes
In this change I've added a new beacon_node cli flag `--execution-jwt-secret-key` for passing the JWT secret directly as string.
Without this flag, it was non-trivial to pass a secrets file containing a JWT secret key without compromising its contents into some management repo or fiddling around with manual file mounts for cloud-based deployments.
When used in combination with environment variables, the secret can be injected into container-based systems like docker & friends quite easily.
It's both possible to either specify the file_path to the JWT secret or pass the JWT secret directly.
I've modified the docs and attached a test as well.
## Additional Info
The logic has been adapted a bit so that either one of `--execution-jwt` or `--execution-jwt-secret-key` must be set when specifying `--execution-endpoint` so that it's still compatible with the semantics before this change and there's at least one secret provided.
## Issue Addressed
#2847
## Proposed Changes
Add under a feature flag the required changes to subscribe to long lived subnets in a deterministic way
## Additional Info
There is an additional required change that is actually searching for peers using the prefix, but I find that it's best to make this change in the future
## Issue Addressed
Adding CLI tests for logging flags: log-color and disable-log-timestamp
Which issue # does this PR address?
#3588
## Proposed Changes
Add CLI tests for logging flags as described in #3588
Please list or describe the changes introduced by this PR.
Added logger_config to client::Config as suggested. Implemented Default for LoggerConfig based on what was being done elsewhere in the repo. Created 2 tests for each flag addressed.
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
## Issue Addressed
N/A
## Proposed Changes
With https://github.com/sigp/lighthouse/pull/3214 we made it such that you can either have 1 auth endpoint or multiple non auth endpoints. Now that we are post merge on all networks (testnets and mainnet), we cannot progress a chain without a dedicated auth execution layer connection so there is no point in having a non-auth eth1-endpoint for syncing deposit cache.
This code removes all fallback related code in the eth1 service. We still keep the single non-auth endpoint since it's useful for testing.
## Additional Info
This removes all eth1 fallback related metrics that were relevant for the monitoring service, so we might need to change the api upstream.
## Issue Addressed
The release CI is currently broken due to the addition of the `protoc` dependency. Here's a failure of the release flow running on my fork: https://github.com/michaelsproul/lighthouse/actions/runs/3155541478/jobs/5134317334
## Proposed Changes
- Install `protoc` on Windows and Mac so that it's available for `cargo install`.
- Install an x86_64 binary in the Cross image for the aarch64 platform: we need a binary that runs on the host, _not_ on the target.
- Fix `macos` local testnet CI by using the Github API key to dodge rate limiting (this issue: https://github.com/actions/runner-images/issues/602).
## Proposed Changes
Add a new Cargo compilation profile called `maxperf` which enables more aggressive compiler optimisations at the expense of compilation time.
Some rough initial benchmarks show that this can provide up to a 25% reduction to run time for CPU bound tasks like block processing: https://docs.google.com/spreadsheets/d/15jHuZe7lLHhZq9Nw8kc6EL0Qh_N_YAYqkW2NQ_Afmtk/edit
The numbers in that spreadsheet compare the `consensus-context` branch from #3604 to the same branch compiled with the `maxperf` profile using:
```
PROFILE=maxperf make install-lcli
```
## Additional Info
The downsides of the maxperf profile are:
- It increases compile times substantially, which will particularly impact low-spec hardware. Compiling `lcli` is about 3x slower. Compiling Lighthouse is about 5x slower on my 5950X: 17m 38s rather than 3m 28s.
As a result I think we should not enable this everywhere by default.
- **Option 1**: enable by default for our released binaries. This gives the majority of users the fastest version of `lighthouse` possible, at the expense of slowing down our release CI. Source builds will continue to use the default `release` profile unless users opt-in to `maxperf`.
- **Option 2**: enable by default for source builds. This gives users building from source an edge, but makes them pay for it with compilation time.
I think I would prefer Option 1. I'll try doing some benchmarking to see how long a maxperf build of Lighthouse would take on GitHub actions.
Credit to Nicholas Nethercote for documenting these options in the Rust Performance Book: https://nnethercote.github.io/perf-book/build-configuration.html.
## Issue Addressed
Resolves#3516
## Proposed Changes
Adds a beacon fallback function for running a beacon node http query on all available fallbacks instead of returning on a first successful result. Uses the new `run_on_all` method for attestation and sync committee subscriptions.
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
## Proposed Changes
Add some docs on checking the builder configuration, which is a frequently asked question on Discord.
## Additional Info
My text editor also insisted on stripping some trailing newlines, but can put 'em back if we want
## Issue Addressed
fixes lints from the last rust release
## Proposed Changes
Fix the lints, most of the lints by `clippy::question-mark` are false positives in the form of https://github.com/rust-lang/rust-clippy/issues/9518 so it's allowed for now
## Additional Info
## Issue Addressed
🐞 in which we don't actually unsubscribe from a random long lived subnet when it expires
## Proposed Changes
Remove code addressing a specific case in which we are subscribed to all subnets and handle the removal of the long lived subnet. I don't think the special case code is particularly important as, if someone is running with that many validators to be subscribed to all subnets, it should use `--subscribe-all-subnets` instead
## Additional Info
Noticed on some test nodes climbing bandwidth usage periodically (around 27hours, the time of subnet expirations) I'm running this code to test this does not happen anymore, but I think it should be good now
## Issue Addressed
NA
## Proposed Changes
This PR attempts to fix the following spurious CI failure:
```
---- store_tests::garbage_collect_temp_states_from_failed_block stdout ----
thread 'store_tests::garbage_collect_temp_states_from_failed_block' panicked at 'disk store should initialize: DBError { message: "Error { message: \"IO error: lock /tmp/.tmp6DcBQ9/cold_db/LOCK: already held by process\" }" }', beacon_node/beacon_chain/tests/store_tests.rs:59:10
```
I believe that some async task is taking a clone of the store and holding it in some other thread for a short time. This creates a race-condition when we try to open a new instance of the store.
## Additional Info
NA
## Issue Addressed
Resolves#3573
## Proposed Changes
Fix the bytecode for the deposit contract deployment transaction and value for deposit transaction in the execution engine integration tests. Also verify that all published transaction make it to the execution payload and have a valid status.
## Issue Addressed
NA
## Proposed Changes
This PR removes duplicated block root computation.
Computing the `SignedBeaconBlock::canonical_root` has become more expensive since the merge as we need to compute the merke root of each transaction inside an `ExecutionPayload`.
Computing the root for [a mainnet block](https://beaconcha.in/slot/4704236) is taking ~10ms on my i7-8700K CPU @ 3.70GHz (no sha extensions). Given that our median seen-to-imported time for blocks is presently 300-400ms, removing a few duplicated block roots (~30ms) could represent an easy 10% improvement. When we consider that the seen-to-imported times include operations *after* the block has been placed in the early attester cache, we could expect the 30ms to be more significant WRT our seen-to-attestable times.
## Additional Info
NA
## Issue Addressed
NA
## Proposed Changes
Fixes an issue introduced in #3574 where I erroneously assumed that a `crossbeam_channel` multiple receiver queue was a *broadcast* queue. This is incorrect, each message will be received by *only one* receiver. The effect of this mistake is these logs:
```
Sep 20 06:56:17.001 INFO Synced slot: 4736079, block: 0xaa8a…180d, epoch: 148002, finalized_epoch: 148000, finalized_root: 0x2775…47f2, exec_hash: 0x2ca5…ffde (verified), peers: 6, service: slot_notifier
Sep 20 06:56:23.237 ERRO Unable to validate attestation error: CommitteeCacheWait(RecvError), peer_id: 16Uiu2HAm2Jnnj8868tb7hCta1rmkXUf5YjqUH1YPj35DCwNyeEzs, type: "aggregated", slot: Slot(4736047), beacon_block_root: 0x88d318534b1010e0ebd79aed60b6b6da1d70357d72b271c01adf55c2b46206c1
```
## Additional Info
NA
## Proposed Changes
Improve the payload pruning feature in several ways:
- Payload pruning is now entirely optional. It is enabled by default but can be disabled with `--prune-payloads false`. The previous `--prune-payloads-on-startup` flag from #3565 is removed.
- Initial payload pruning on startup now runs in a background thread. This thread will always load the split state, which is a small fraction of its total work (up to ~300ms) and then backtrack from that state. This pruning process ran in 2m5s on one Prater node with good I/O and 16m on a node with slower I/O.
- To work with the optional payload pruning the database function `try_load_full_block` will now attempt to load execution payloads for finalized slots _if_ pruning is currently disabled. This gives users an opt-out for the extensive traffic between the CL and EL for reconstructing payloads.
## Additional Info
If the `prune-payloads` flag is toggled on and off then the on-startup check may not see any payloads to delete and fail to clean them up. In this case the `lighthouse db prune_payloads` command should be used to force a manual sweep of the database.
## Issue Addressed
https://github.com/ethereum/beacon-APIs/pull/222
## Proposed Changes
Update Lighthouse's randao verification API to match the `beacon-APIs` spec. We implemented the API before spec stabilisation, and it changed slightly in the course of review.
Rather than a flag `verify_randao` taking a boolean value, the new API uses a `skip_randao_verification` flag which takes no argument. The new spec also requires the randao reveal to be present and equal to the point-at-infinity when `skip_randao_verification` is set.
I've also updated the `POST /lighthouse/analysis/block_rewards` API to take blinded blocks as input, as the execution payload is irrelevant and we may want to assess blocks produced by builders.
## Additional Info
This is technically a breaking change, but seeing as I suspect I'm the only one using these parameters/APIs, I think we're OK to include this in a patch release.
## Issue Addressed
Closes https://github.com/sigp/lighthouse/issues/3556
## Proposed Changes
Delete finalized execution payloads from the database in two places:
1. When running the finalization migration in `migrate_database`. We delete the finalized payloads between the last split point and the new updated split point. _If_ payloads are already pruned prior to this then this is sufficient to prune _all_ payloads as non-canonical payloads are already deleted by the head pruner, and all canonical payloads prior to the previous split will already have been pruned.
2. To address the fact that users will update to this code _after_ the merge on mainnet (and testnets), we need a one-off scan to delete the finalized payloads from the canonical chain. This is implemented in `try_prune_execution_payloads` which runs on startup and scans the chain back to the Bellatrix fork or the anchor slot (if checkpoint synced after Bellatrix). In the case where payloads are already pruned this check only imposes a single state load for the split state, which shouldn't be _too slow_. Even so, a flag `--prepare-payloads-on-startup=false` is provided to turn this off after it has run the first time, which provides faster start-up times.
There is also a new `lighthouse db prune_payloads` subcommand for users who prefer to run the pruning manually.
## Additional Info
The tests have been updated to not rely on finalized payloads in the database, instead using the `MockExecutionLayer` to reconstruct them. Additionally a check was added to `check_chain_dump` which asserts the non-existence or existence of payloads on disk depending on their slot.
## Issue Addressed
Fixes a potential regression in memory fragmentation identified by @paulhauner here: https://github.com/sigp/lighthouse/pull/3371#discussion_r931770045.
## Proposed Changes
Immediately allocate a vector with sufficient size to hold all decoded elements in SSZ decoding. The `size_hint` is derived from the range iterator here:
2983235650/consensus/ssz/src/decode/impls.rs (L489)
## Additional Info
I'd like to test this out on some infra for a substantial duration to see if it affects total fragmentation.
## Issue Addressed
NA
## Proposed Changes
I've noticed that our block hashing times increase significantly after the merge. I did some flamegraph-ing and noticed that we're allocating a `Vec` for each byte of each execution payload transaction. This seems like unnecessary work and a bit of a fragmentation risk.
This PR switches to `SmallVec<[u8; 32]>` for the packed encoding of `TreeHash`. I believe this is a nice simple optimisation with no downside.
### Benchmarking
These numbers were computed using #3580 on my desktop (i7 hex-core). You can see a bit of noise in the numbers, that's probably just my computer doing other things. Generally I found this change takes the time from 10-11ms to 8-9ms. I can also see all the allocations disappear from flamegraph.
This is the block being benchmarked: https://beaconcha.in/slot/4704236
#### Before
```
[2022-09-15T21:44:19Z INFO lcli::block_root] Run 980: 10.553003ms
[2022-09-15T21:44:19Z INFO lcli::block_root] Run 981: 10.563737ms
[2022-09-15T21:44:19Z INFO lcli::block_root] Run 982: 10.646352ms
[2022-09-15T21:44:19Z INFO lcli::block_root] Run 983: 10.628532ms
[2022-09-15T21:44:19Z INFO lcli::block_root] Run 984: 10.552112ms
[2022-09-15T21:44:19Z INFO lcli::block_root] Run 985: 10.587778ms
[2022-09-15T21:44:19Z INFO lcli::block_root] Run 986: 10.640526ms
[2022-09-15T21:44:19Z INFO lcli::block_root] Run 987: 10.587243ms
[2022-09-15T21:44:19Z INFO lcli::block_root] Run 988: 10.554748ms
[2022-09-15T21:44:19Z INFO lcli::block_root] Run 989: 10.551111ms
[2022-09-15T21:44:19Z INFO lcli::block_root] Run 990: 11.559031ms
[2022-09-15T21:44:19Z INFO lcli::block_root] Run 991: 11.944827ms
[2022-09-15T21:44:19Z INFO lcli::block_root] Run 992: 10.554308ms
[2022-09-15T21:44:19Z INFO lcli::block_root] Run 993: 11.043397ms
[2022-09-15T21:44:19Z INFO lcli::block_root] Run 994: 11.043315ms
[2022-09-15T21:44:19Z INFO lcli::block_root] Run 995: 11.207711ms
[2022-09-15T21:44:19Z INFO lcli::block_root] Run 996: 11.056246ms
[2022-09-15T21:44:19Z INFO lcli::block_root] Run 997: 11.049706ms
[2022-09-15T21:44:19Z INFO lcli::block_root] Run 998: 11.432449ms
[2022-09-15T21:44:19Z INFO lcli::block_root] Run 999: 11.149617ms
```
#### After
```
[2022-09-15T21:41:49Z INFO lcli::block_root] Run 980: 14.011653ms
[2022-09-15T21:41:49Z INFO lcli::block_root] Run 981: 8.925314ms
[2022-09-15T21:41:49Z INFO lcli::block_root] Run 982: 8.849563ms
[2022-09-15T21:41:49Z INFO lcli::block_root] Run 983: 8.893689ms
[2022-09-15T21:41:49Z INFO lcli::block_root] Run 984: 8.902964ms
[2022-09-15T21:41:49Z INFO lcli::block_root] Run 985: 8.942067ms
[2022-09-15T21:41:49Z INFO lcli::block_root] Run 986: 8.907088ms
[2022-09-15T21:41:49Z INFO lcli::block_root] Run 987: 9.346101ms
[2022-09-15T21:41:49Z INFO lcli::block_root] Run 988: 8.96142ms
[2022-09-15T21:41:49Z INFO lcli::block_root] Run 989: 9.366437ms
[2022-09-15T21:41:49Z INFO lcli::block_root] Run 990: 9.809334ms
[2022-09-15T21:41:49Z INFO lcli::block_root] Run 991: 9.541561ms
[2022-09-15T21:41:49Z INFO lcli::block_root] Run 992: 11.143518ms
[2022-09-15T21:41:49Z INFO lcli::block_root] Run 993: 10.821181ms
[2022-09-15T21:41:49Z INFO lcli::block_root] Run 994: 9.855973ms
[2022-09-15T21:41:49Z INFO lcli::block_root] Run 995: 10.941006ms
[2022-09-15T21:41:49Z INFO lcli::block_root] Run 996: 9.596155ms
[2022-09-15T21:41:49Z INFO lcli::block_root] Run 997: 9.121739ms
[2022-09-15T21:41:49Z INFO lcli::block_root] Run 998: 9.090019ms
[2022-09-15T21:41:49Z INFO lcli::block_root] Run 999: 9.071885ms
```
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
## Issue Addressed
NA
## Proposed Changes
Adds a simple tool for computing the block root of some block from a beacon-API or a file. This is useful for benchmarking.
## Additional Info
NA
## Issue Addressed
NA
## Proposed Changes
I have observed scenarios on Goerli where Lighthouse was receiving attestations which reference the same, un-cached shuffling on multiple threads at the same time. Lighthouse was then loading the same state from database and determining the shuffling on multiple threads at the same time. This is unnecessary load on the disk and RAM.
This PR modifies the shuffling cache so that each entry can be either:
- A committee
- A promise for a committee (i.e., a `crossbeam_channel::Receiver`)
Now, in the scenario where we have thread A and thread B simultaneously requesting the same un-cached shuffling, we will have the following:
1. Thread A will take the write-lock on the shuffling cache, find that there's no cached committee and then create a "promise" (a `crossbeam_channel::Sender`) for a committee before dropping the write-lock.
1. Thread B will then be allowed to take the write-lock for the shuffling cache and find the promise created by thread A. It will block the current thread waiting for thread A to fulfill that promise.
1. Thread A will load the state from disk, obtain the shuffling, send it down the channel, insert the entry into the cache and then continue to verify the attestation.
1. Thread B will then receive the shuffling from the receiver, be un-blocked and then continue to verify the attestation.
In the case where thread A fails to generate the shuffling and drops the sender, the next time that specific shuffling is requested we will detect that the channel is disconnected and return a `None` entry for that shuffling. This will cause the shuffling to be re-calculated.
## Additional Info
NA
## Issue Addressed
Fix a `cargo-audit` failure. We don't use `axum` for anything besides tests, but `cargo-audit` is failing due to this vulnerability in `axum-core`: https://rustsec.org/advisories/RUSTSEC-2022-0055
## Issue Addressed
Make sure gas limit examples in our docs represent sane values.
Thanks @dankrad for raising this in discord.
## Additional Info
We could also consider logging warnings about whether the gas limits configured are sane. Prysm has an open issue for this: https://github.com/prysmaticlabs/prysm/issues/10810
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
#3562
## Proposed Changes
Change the fork endpoint from `localhost` to `127.0.0.1` to match the ganache default listening host.
This way it doesn't try (and fail) to connect to `::1` on IPV6 machines.
## Additional Info
First PR
## Issue Addressed
#3285
## Proposed Changes
Adds support for specifying histogram with buckets and adds new metric buckets for metrics mentioned in issue.
## Additional Info
Need some help for the buckets.
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Proposed Changes
Add a section on the new community checkpoint sync endpoints in the book. This should help stakers sync faster even without having to create an account.
## Issue Addressed
We were unable to update lighthouse by running `cargo update` because some of the `mev-build-rs` deps weren't pinned. But `mev-build-rs` is now pinned here and includes it's own pinned commits for `ssz-rs` and `etheruem-consensus`
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
Resolves: #3550
Remove the `--strict-fee-recipient` flag. It will cause missed proposals prior to the bellatrix transition.
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
Related: #3550
Remove references to the `--strict-fee-recipient` flag in docs. The flag will cause missed proposals prior to the merge transition.
Co-authored-by: realbigsean <sean@sigmaprime.io>
Add flag 'log-color' which preserves colors of log when stdout is redirected to a file.
This is my first lighthouse PR, please let me know if I'm not following contribution guidelines, I welcome meta-feeback (feedback on git commit messages, git branch naming, and the contents of the description of this PR.)
## Issue Addressed
Solves https://github.com/sigp/lighthouse/issues/3527
## Proposed Changes
Adding a flag which enables log color preserving when stdout is redirected to a file.
### Usage
Below I demonstrate current behaviour (without using the new flag) and the new behaviur (when using new flag).
In the screenshot below, I have to panes, one on top running `lighthouse` which redirects to file `~/Desktop/test.log` and one pane in the bottom which runs `tail -f ~/Desktop/test.log`.
#### Current behaviour
```sh
lighthouse --network prater vc |& tee -a ~/Desktop/test.log
```
**Result is no colors**
<img width="1624" alt="current" src="https://user-images.githubusercontent.com/864410/188258226-bfcf8271-4c9e-474c-848e-ac92a60df25c.png">
#### New behaviour
```sh
lighthouse --network prater vc --log-color |& tee -a ~/Desktop/test.log
```
**Result is colors** 🔴🟢🔵🟡
<img width="1624" alt="new" src="https://user-images.githubusercontent.com/864410/188258223-7d9ecf09-92c8-4cba-8f24-bd4d88fc0353.png">
## Additional Info
I chose American spelling of "color" instead of Brittish "colour' since that was aligned with `slog`'s API - method`force_color()`, let me know if you prefer spelling "colour" instead. I also chose to let it be an arg not taking any argument, just like `logfile-compress` flag, rather than having to write `--log-color true`.
## Issue Addressed
Closes#3514
## Proposed Changes
- Change default monitoring endpoint frequency to 120 seconds to fit with 30k requests/month limit.
- Allow configuration of the monitoring endpoint frequency using `--monitoring-endpoint-frequency N` where `N` is a value in seconds.
## Issue Addressed
Resolves https://github.com/sigp/lighthouse/issues/3517
## Proposed Changes
Adds a `--builder-profit-threshold <wei value>` flag to the BN. If an external payload's value field is less than this value, the local payload will be used. The value of the local payload will not be checked (it can't really be checked until the engine API is updated to support this).
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
Add a flag that can increase count unrealized strictness, defaults to false
## Proposed Changes
Please list or describe the changes introduced by this PR.
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
Co-authored-by: realbigsean <seananderson33@gmail.com>
Co-authored-by: sean <seananderson33@gmail.com>
## Issue Addressed
[Have --checkpoint-sync-url timeout](https://github.com/sigp/lighthouse/issues/3478)
## Proposed Changes
I added a parameter for `get_bytes_opt_accept_header<U: IntoUrl>` which accept a timeout duration, and modified the body of `get_beacon_blocks_ssz` and `get_debug_beacon_states_ssz` to pass corresponding timeout durations.
## Issue Addressed
When requesting an index which is not active during `start_epoch`, Lighthouse returns:
```
curl "http://localhost:5052/lighthouse/analysis/attestation_performance/999999999?start_epoch=100000&end_epoch=100000"
```
```json
{
"code": 500,
"message": "INTERNAL_SERVER_ERROR: ParticipationCache(InvalidValidatorIndex(999999999))",
"stacktraces": []
}
```
This error occurs even when the index in question becomes active before `end_epoch` which is undesirable as it can prevent larger queries from completing.
## Proposed Changes
In the event the index is out-of-bounds (has not yet been activated), simply return all fields as `false`:
```
-> curl "http://localhost:5052/lighthouse/analysis/attestation_performance/999999999?start_epoch=100000&end_epoch=100000"
```
```json
[
{
"index": 999999999,
"epochs": {
"100000": {
"active": false,
"head": false,
"target": false,
"source": false
}
}
}
]
```
By doing this, we cover the case where a validator becomes active sometime between `start_epoch` and `end_epoch`.
## Additional Info
Note that this error only occurs for epochs after the Altair hard fork.
## Issue Addressed
We currently subscribe to attestation subnets as soon as the subscription arrives (one epoch in advance), this makes it so that subscriptions for future slots are scheduled instead of done immediately.
## Proposed Changes
- Schedule subscriptions to subnets for future slots.
- Finish removing hashmap_delay, in favor of [delay_map](https://github.com/AgeManning/delay_map). This was the only remaining service to do this.
- Subscriptions for past slots are rejected, before we would subscribe for one slot.
- Add a new test for subscriptions that are not consecutive.
## Additional Info
This is also an effort in making the code easier to understand
## Issue Addressed
Resolves#3524
## Proposed Changes
Log fee recipient in the `Validator exists in beacon chain` log. Logging in the BN already happens here 18c61a5e8b/beacon_node/beacon_chain/src/beacon_chain.rs (L3858-L3865)
I also think it's good practice to encourage users to set the fee recipient in the VC rather than the BN because of issues mentioned here https://github.com/sigp/lighthouse/issues/3432
Some example logs from prater:
```
Aug 30 03:47:09.922 INFO Validator exists in beacon chain fee_recipient: 0xab97_ad88, validator_index: 213615, pubkey: 0xb542b69ba14ddbaf717ca1762ece63a4804c08d38a1aadf156ae718d1545942e86763a1604f5065d4faa550b7259d651, service: duties
Aug 30 03:48:05.505 INFO Validator exists in beacon chain fee_recipient: Fee recipient for validator not set in validator_definitions.yml or provided with the `--suggested-fee-recipient flag`, validator_index: 210710, pubkey: 0xad5d67cc7f990590c7b3fa41d593c4cf12d9ead894be2311fbb3e5c733d8c1b909e9d47af60ea3480fb6b37946c35390, service: duties
```
Co-authored-by: Paul Hauner <paul@paulhauner.com>
## Issue Addressed
NA
## Proposed Changes
As we've seen on Prater, there seems to be a correlation between these messages
```
WARN Not enough time for a discovery search subnet_id: ExactSubnet { subnet_id: SubnetId(19), slot: Slot(3742336) }, service: attestation_service
```
... and nodes falling 20-30 slots behind the head for short periods. These nodes are running ~20k Prater validators.
After running some metrics, I can see that the `network_recv` channel is processing ~250k `AttestationSubscribe` messages per minute. It occurred to me that perhaps the `AttestationSubscribe` messages are "washing out" the `SendRequest` and `SendResponse` messages. In this PR I separate the `AttestationSubscribe` and `SyncCommitteeSubscribe` messages into their own queue so the `tokio::select!` in the `NetworkService` can still process the other messages in the `network_recv` channel without necessarily having to clear all the subscription messages first.
~~I've also added filter to the HTTP API to prevent duplicate subscriptions going to the network service.~~
## Additional Info
- Currently being tested on Prater
## Issue Addressed
I think the antithesis is failing due to an OOM which may be resolved by updating the ubuntu image it runs on. The lcli build looks like it's failing because the image lacks the `libclang` dependency
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
Partly resolves#3518
## Proposed Changes
Change the slot notifier to use `duration_to_next_slot` rather than an interval timer. This makes it robust against underlying clock changes.
## Issue Addressed
NA
## Proposed Changes
Adds more `debug` logging to help troubleshoot invalid execution payload blocks. I was doing some of this recently and found it to be challenging.
With this PR we should be able to grep `Invalid execution payload` and get one-liners that will show the block, slot and details about the proposer.
I also changed the log in `process_invalid_execution_payload` since it was a little misleading; the `block_root` wasn't necessary the block which had an invalid payload.
## Additional Info
NA
## Issue Addressed
NA
## Proposed Changes
This PR is motivated by a recent consensus failure in Geth where it returned `INVALID` for an `VALID` block. Without this PR, the only way to recover is by re-syncing Lighthouse. Whilst ELs "shouldn't have consensus failures", in reality it's something that we can expect from time to time due to the complex nature of Ethereum. Being able to recover easily will help the network recover and EL devs to troubleshoot.
The risk introduced with this PR is that genuinely INVALID payloads get a "second chance" at being imported. I believe the DoS risk here is negligible since LH needs to be restarted in order to re-process the payload. Furthermore, there's no reason to think that a well-performing EL will accept a truly invalid payload the second-time-around.
## Additional Info
This implementation has the following intricacies:
1. Instead of just resetting *invalid* payloads to optimistic, we'll also reset *valid* payloads. This is an artifact of our existing implementation.
1. We will only reset payload statuses when we detect an invalid payload present in `proto_array`
- This helps save us from forgetting that all our blocks are valid in the "best case scenario" where there are no invalid blocks.
1. If we fail to revert the payload statuses we'll log a `CRIT` and just continue with a `proto_array` that *does not* have reverted payload statuses.
- The code to revert statuses needs to deal with balances and proposer-boost, so it's a failure point. This is a defensive measure to avoid introducing new show-stopping bugs to LH.
## Issue Addressed
Relates to https://github.com/sigp/lighthouse/issues/3416
## Proposed Changes
- Add an `OfflineOnFailure` enum to the `first_success` method for querying beacon nodes so that a val registration request failure from the BN -> builder does not result in the BN being marked offline. This seems important because these failures could be coming directly from a connected relay and actually have no bearing on BN health. Other messages that are sent to a relay have a local fallback so shouldn't result in errors
- Downgrade the following log to a `WARN`
```
ERRO Unable to publish validator registrations to the builder network, error: All endpoints failed https://BN_B => RequestFailed(ServerMessage(ErrorMessage { code: 500, message: "UNHANDLED_ERROR: BuilderMissing", stacktraces: [] })), https://XXXX/ => Unavailable(Offline), [omitted]
```
## Additional Info
I think this change at least improves the UX of having a VC connected to some builder and some non-builder beacon nodes. I think we need to balance potentially alerting users that there is a BN <> VC misconfiguration and also allowing this type of fallback to work.
If we want to fully support this type of configuration we may want to consider adding a flag `--builder-beacon-nodes` and track whether a VC should be making builder queries on a per-beacon node basis. But I think the changes in this PR are independent of that type of extension.
PS: Sorry for the big diff here, it's mostly formatting changes after I added a new arg to a bunch of methods calls.
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Proposed Changes
This PR has two aims: to speed up attestation packing in the op pool, and to fix bugs in the verification of attester slashings, proposer slashings and voluntary exits. The changes are bundled into a single database schema upgrade (v12).
Attestation packing is sped up by removing several inefficiencies:
- No more recalculation of `attesting_indices` during packing.
- No (unnecessary) examination of the `ParticipationFlags`: a bitfield suffices. See `RewardCache`.
- No re-checking of attestation validity during packing: the `AttestationMap` provides attestations which are "correct by construction" (I have checked this using Hydra).
- No SSZ re-serialization for the clunky `AttestationId` type (it can be removed in a future release).
So far the speed-up seems to be roughly 2-10x, from 500ms down to 50-100ms.
Verification of attester slashings, proposer slashings and voluntary exits is fixed by:
- Tracking the `ForkVersion`s that were used to verify each message inside the `SigVerifiedOp`. This allows us to quickly re-verify that they match the head state's opinion of what the `ForkVersion` should be at the epoch(s) relevant to the message.
- Storing the `SigVerifiedOp` on disk rather than the raw operation. This allows us to continue track the fork versions after a reboot.
This is mostly contained in this commit 52bb1840ae.
## Additional Info
The schema upgrade uses the justified state to re-verify attestations and compute `attesting_indices` for them. It will drop any attestations that fail to verify, by the logic that attestations are most valuable in the few slots after they're observed, and are probably stale and useless by the time a node restarts. Exits and proposer slashings and similarly re-verified to obtain `SigVerifiedOp`s.
This PR contains a runtime killswitch `--paranoid-block-proposal` which opts out of all the optimisations in favour of closely verifying every included message. Although I'm quite sure that the optimisations are correct this flag could be useful in the event of an unforeseen emergency.
Finally, you might notice that the `RewardCache` appears quite useless in its current form because it is only updated on the hot-path immediately before proposal. My hope is that in future we can shift calls to `RewardCache::update` into the background, e.g. while performing the state advance. It is also forward-looking to `tree-states` compatibility, where iterating and indexing `state.{previous,current}_epoch_participation` is expensive and needs to be minimised.
## Proposed Changes
Address a few shortcomings of the book noticed by users:
- Remove description of redundant execution nodes
- Use an Infura eth1 node rather than an eth2 node in the merge migration example
- Add an example of the fee recipient address format (we support addresses without the 0x prefix, but 0x prefixed feels more canonical).
- Clarify that Windows support is no longer beta
- Add a link to the MSRV to the build-from-source instructions
## Issue Addressed
NA
## Proposed Changes
Indicate that local keystores are `readonly: Some(false)` rather than `None` via the `/eth/v1/keystores` method on the VC API.
I'll mark this as backwards-incompat so we remember to mention it in the release notes. There aren't any type-level incompatibilities here, just a change in how Lighthouse responds to responses.
## Additional Info
- Blocked on #3464
## Issue Addressed
Resolves#3448
## Proposed Changes
Removes a known failure that wasn't actually a known failure. The tests declare this block invalid and we refuse to import it due to `ExecutionPayloadError(UnverifiedNonOptimisticCandidate)`.
This is correct since there is only one "eth1" block included in this test and two are required to trigger the merge (pre- and post-TTD blocks). It is slot 1 (tick = 12s) when this block is imported so the import must be prevented by `SAFE_SLOTS_TO_IMPORT_OPTIMISTICALLY`.
I'm not sure where I got the idea in #3448 that this test needed retrospective checking, that seems like a false assumption in hindsight.
## Additional Info
- Blocked on #3464
## Issue Addressed
#3465
## Proposed Changes
Filter out any validator registrations for validators that are not `active` or `pending`. I'm adding this filtering the beacon node because all the information is readily available there. In other parts of the VC we are usually sending per-validator requests based on duties from the BN. And duties will only be provided for active validators so we don't have this type of filtering elsewhere in the VC.
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
#3032
## Proposed Changes
Pause sync when ee is offline. Changes include three main parts:
- Online/offline notification system
- Pause sync
- Resume sync
#### Online/offline notification system
- The engine state is now guarded behind a new struct `State` that ensures every change is correctly notified. Notifications are only sent if the state changes. The new `State` is behind a `RwLock` (as before) as the synchronization mechanism.
- The actual notification channel is a [tokio::sync::watch](https://docs.rs/tokio/latest/tokio/sync/watch/index.html) which ensures only the last value is in the receiver channel. This way we don't need to worry about message order etc.
- Sync waits for state changes concurrently with normal messages.
#### Pause Sync
Sync has four components, pausing is done differently in each:
- **Block lookups**: Disabled while in this state. We drop current requests and don't search for new blocks. Block lookups are infrequent and I don't think it's worth the extra logic of keeping these and delaying processing. If we later see that this is required, we can add it.
- **Parent lookups**: Disabled while in this state. We drop current requests and don't search for new parents. Parent lookups are even less frequent and I don't think it's worth the extra logic of keeping these and delaying processing. If we later see that this is required, we can add it.
- **Range**: Chains don't send batches for processing to the beacon processor. This is easily done by guarding the channel to the beacon processor and giving it access only if the ee is responsive. I find this the simplest and most powerful approach since we don't need to deal with new sync states and chain segments that are added while the ee is offline will follow the same logic without needing to synchronize a shared state among those. Another advantage of passive pause vs active pause is that we can still keep track of active advertised chain segments so that on resume we don't need to re-evaluate all our peers.
- **Backfill**: Not affected by ee states, we don't pause.
#### Resume Sync
- **Block lookups**: Enabled again.
- **Parent lookups**: Enabled again.
- **Range**: Active resume. Since the only real pause range does is not sending batches for processing, resume makes all chains that are holding read-for-processing batches send them.
- **Backfill**: Not affected by ee states, no need to resume.
## Additional Info
**QUESTION**: Originally I made this to notify and change on synced state, but @pawanjay176 on talks with @paulhauner concluded we only need to check online/offline states. The upcheck function mentions extra checks to have a very up to date sync status to aid the networking stack. However, the only need the networking stack would have is this one. I added a TODO to review if the extra check can be removed
Next gen of #3094
Will work best with #3439
Co-authored-by: Pawan Dhananjay <pawandhananjay@gmail.com>
## Proposed Changes
Update the merge migration docs to encourage updating mainnet configs _now_!
The docs are also updated to recommend _against_ `--suggested-fee-recipient` on the beacon node (https://github.com/sigp/lighthouse/issues/3432).
Additionally the `--help` for the CLI is updated to match with a few small semantic changes:
- `--execution-jwt` is no longer allowed without `--execution-endpoint`. We've ended up without a default for `--execution-endpoint`, so I think that's fine.
- The flags related to the JWT are only allowed if `--execution-jwt` is provided.
## Issue Addressed
NA
## Proposed Changes
Bump versions to v3.0.0
## Additional Info
- ~~Blocked on #3439~~
- ~~Blocked on #3459~~
- ~~Blocked on #3463~~
- ~~Blocked on #3462~~
- ~~Requires further testing~~
Co-authored-by: Michael Sproul <michael@sigmaprime.io>
## Issue Addressed
NA
## Proposed Changes
Run fork choice when the head is 256 slots from the wall-clock slot, rather than 4.
The reason we don't *always* run FC is so that it doesn't slow us down during sync. As the comments state, setting the value to 256 means that we'd only have one interrupting fork-choice call if we were syncing at 20 slots/sec.
## Additional Info
NA
## Issue Addressed
NA
## Proposed Changes
Adds some metrics so we can track payload status responses from the EE. I think this will be useful for troubleshooting and alerting.
I also bumped the `BecaonChain::per_slot_task` to `debug` since it doesn't seem too noisy and would have helped us with some things we were debugging in the past.
## Additional Info
NA
## Issue Addressed
Recent changes to the Nethermind codebase removed the `rocksdb` git submodule in favour of a `nuget` package.
This appears to have broken our ability to build the latest release of Nethermind inside our integration tests.
## Proposed Changes
~Temporarily pin the version used for the Nethermind integration tests to `master`. This ensures we use the packaged version of `rocksdb`. This is only necessary until a new release of Nethermind is available.~
Use `git submodule update --init --recursive` to ensure the required submodules are pulled before building.
Co-authored-by: Diva M <divma@protonmail.com>
## Issue Addressed
NA
## Proposed Changes
Adds a test that was written whilst doing some testing. This PR does not make changes to production code, it just adds a test for already existing functionality.
## Additional Info
NA
## Proposed Changes
Match the timeouts from the `execution-apis` spec. Our existing values were already quite close so I don't imagine this change to be very disruptive.
The spec sets the timeout for `engine_getPayloadV1` to only 1 second, but we were already using a longer value of 2 seconds. I've kept the 2 second timeout as I don't think there's any need to fail faster when producing a payload.
There's no timeout specified for `eth_syncing` so I've matched it to the shortest timeout from the spec (1 second). I think the previous value of 250ms was likely too low and could have been contributing to spurious timeouts, particularly for remote ELs.
## Additional Info
The timeouts are defined on each endpoint in this document: https://github.com/ethereum/execution-apis/blob/main/src/engine/specification.md
## Issue Addressed
Fixes an issue whereby syncing a post-merge network without an execution endpoint would silently stall. Sync swallows the errors from block verification so previously there was no indication in the logs for why the node couldn't sync.
## Proposed Changes
Add an error log to the merge-readiness notifier for the case where the merge has already completed but no execution endpoint is configured.
## Issue Addressed
Closes https://github.com/sigp/lighthouse/issues/2962
## Proposed Changes
Build all caches on the checkpoint state before storing it in the database.
Additionally, fix a bug in `signature_verify_chain_segment` which prevented block verification from succeeding unless the previous epoch cache was already built. The previous epoch cache is required to verify the signatures of attestations included from previous epochs, even when all the blocks in the segment are from the same epoch.
The comments around `signature_verify_chain_segment` have also been updated to reflect the fact that it should only be used on a chain of blocks from a single epoch. I believe this restriction had already been added at some point in the past and that the current comments were just outdated (and I think because the proposer shuffling can change in the next epoch based on the blocks applied in the current epoch that this limitation is essential).
## Issue Addressed
NA
## Proposed Changes
Start issuing merge-readiness logs 2 weeks before the Bellatrix fork epoch. Additionally, if the Bellatrix epoch is specified and the use has configured an EL, always log merge readiness logs, this should benefit pro-active users.
### Lookahead Reasoning
- Bellatrix fork is:
- epoch 144896
- slot 4636672
- Unix timestamp: `1606824023 + (4636672 * 12) = 1662464087`
- GMT: Tue Sep 06 2022 11:34:47 GMT+0000
- Warning start time is:
- Unix timestamp: `1662464087 - 604800 * 2 = 1661254487`
- GMT: Tue Aug 23 2022 11:34:47 GMT+0000
The [current expectation](https://discord.com/channels/595666850260713488/745077610685661265/1007445305198911569) is that EL and CL clients will releases out by Aug 22nd at the latest, then an EF announcement will go out on the 23rd. If all goes well, LH will start alerting users about merge-readiness just after the announcement.
## Additional Info
NA
## Proposed Changes
Enable multiple database backends for the slasher, either MDBX (default) or LMDB. The backend can be selected using `--slasher-backend={lmdb,mdbx}`.
## Additional Info
In order to abstract over the two library's different handling of database lifetimes I've used `Box::leak` to give the `Environment` type a `'static` lifetime. This was the only way I could think of using 100% safe code to construct a self-referential struct `SlasherDB`, where the `OpenDatabases` refers to the `Environment`. I think this is OK, as the `Environment` is expected to live for the life of the program, and both database engines leave the database in a consistent state after each write. The memory claimed for memory-mapping will be freed by the OS and appropriately flushed regardless of whether the `Environment` is actually dropped.
We are depending on two `sigp` forks of `libmdbx-rs` and `lmdb-rs`, to give us greater control over MDBX OS support and LMDB's version.
## Issue Addressed
N/A
## Proposed Changes
Fix clippy lints for latest rust version 1.63. I have allowed the [derive_partial_eq_without_eq](https://rust-lang.github.io/rust-clippy/master/index.html#derive_partial_eq_without_eq) lint as satisfying this lint would result in more code that we might not want and I feel it's not required.
Happy to fix this lint across lighthouse if required though.
## Issue Addressed
Solves #3390
So after checking some logs @pawanjay176 got, we conclude that this happened because we blacklisted a chain after trying it "too much". Now here, in all occurrences it seems that "too much" means we got too many download failures. This happened very slowly, exactly because the batch is allowed to stay alive for very long times after not counting penalties when the ee is offline. The error here then was not that the batch failed because of offline ee errors, but that we blacklisted a chain because of download errors, which we can't pin on the chain but on the peer. This PR fixes that.
## Proposed Changes
Adds a missing piece of logic so that if a chain fails for errors that can't be attributed to an objectively bad behavior from the peer, it is not blacklisted. The issue at hand occurred when new peers arrived claiming a head that had wrongfully blacklisted, even if the original peers participating in the chain were not penalized.
Another notable change is that we need to consider a batch invalid if it processed correctly but its next non empty batch fails processing. Now since a batch can fail processing in non empty ways, there is no need to mark as invalid previous batches.
Improves some logging as well.
## Additional Info
We should do this regardless of pausing sync on ee offline/unsynced state. This is because I think it's almost impossible to ensure a processing result will reach in a predictable order with a synced notification from the ee. Doing this handles what I think are inevitable data races when we actually pause sync
This also fixes a return that reports which batch failed and caused us some confusion checking the logs
## Issue Addressed
I think we're running into this in our linkcheck, so I'm going to frist verify linkcheck fails on the current version, and then try downgrading it to see if it passes https://github.com/chronotope/chrono/issues/755
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
N/A
## Proposed Changes
If the build tree is not a git repository, the unit test will fail. This PR fixes the issue.
## Additional Info
N/A
## Issue Addressed
NA
## Proposed Changes
Removes three types of TODOs:
1. `execution_layer/src/lib.rs`: It was [determined](https://github.com/ethereum/consensus-specs/issues/2636#issuecomment-988688742) that there is no action required here.
2. `beacon_processor/worker/gossip_methods.rs`: Removed TODOs relating to peer scoring that have already been addressed via `epe.penalize_peer()`.
- It seems `cargo fmt` wanted to adjust some things here as well 🤷
3. `proto_array_fork_choice.rs`: it would be nice to remove that useless `bool` for cleanliness, but I don't think it's something we need to do and the TODO just makes things look messier IMO.
## Additional Info
There should be no functional changes to the code in this PR.
There are still some TODOs lingering, those ones require actual changes or more thought.
## Issue Addressed
Resolves#3388Resolves#2638
## Proposed Changes
- Return the `BellatrixPreset` on `/eth/v1/config/spec` by default.
- Allow users to opt out of this by providing `--http-spec-fork=altair` (unless there's a Bellatrix fork epoch set).
- Add the Altair constants from #2638 and make serving the constants non-optional (the `http-disable-legacy-spec` flag is deprecated).
- Modify the VC to only read the `Config` and not to log extra fields. This prevents it from having to muck around parsing the `ConfigAndPreset` fields it doesn't need.
## Additional Info
This change is backwards-compatible for the VC and the BN, but is marked as a breaking change for the removal of `--http-disable-legacy-spec`.
I tried making `Config` a `superstruct` too, but getting the automatic decoding to work was a huge pain and was going to require a lot of hacks, so I gave up in favour of keeping the default-based approach we have now.
## Issue Addressed
Resolves#3379
## Proposed Changes
Remove instances of `InvalidTerminalBlock` in lighthouse and use
`Invalid {latest_valid_hash: "0x0000000000000000000000000000000000000000000000000000000000000000"}`
to represent that status.
## Issue Addressed
- Resolves#3266
## Proposed Changes
Return 200 OK rather than an error when a block, attestation or sync message is already known.
Presently, we will log return an error which causes a BN to go "offline" from the VCs perspective which causes the fallback mechanism to do work to try and avoid and upcheck offline nodes. This can be observed as instability in the `vc_beacon_nodes_available_count` metric.
The current behaviour also causes scary logs for the user. There's nothing to *actually* be concerned about when we see duplicate messages, this can happen on fallback systems (see code comments).
## Additional Info
NA
## Issue Addressed
NA
## Proposed Changes
Update bootnodes for Prater. There are new IP addresses for the Sigma Prime nodes. Teku and Nimbus nodes were also added.
## Additional Info
Related: 24760cd4b4
## Issue Addressed
NA
## Proposed Changes
Modifies `lcli skip-slots` and `lcli transition-blocks` allow them to source blocks/states from a beaconAPI and also gives them some more features to assist with benchmarking.
## Additional Info
Breaks the current `lcli skip-slots` and `lcli transition-blocks` APIs by changing some flag names. It should be simple enough to figure out the changes via `--help`.
Currently blocked on #3263.
## Issue Addressed - N/A
## Proposed Changes
Adding badge to contribution docs that shows the number of minted GitPOAPs
## Additional Info
Hey all, this PR adds a [GitPOAP Badge](https://docs.gitpoap.io/api#get-v1repoownernamebadge) to the contribution docs that displays the number of minted GitPOAPs for this repository by contributors to this repo.
You can see an example of this in [our Documentation repository](https://github.com/gitpoap/gitpoap-docs#gitpoap-docs).
This should help would-be contributors as well as existing contributors find out that they will/have received GitPOAPs for their contributions.
CC: @colfax23 @kayla-henrie
Replaces: https://github.com/sigp/lighthouse/pull/3330
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Proposed Changes
Update the invalid head tests so that they work with the current default fork choice configuration.
Thanks @realbigsean for fixing the persistence test and the EF tests.
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
Resolves#3424
## Proposed Changes
This PR expands the merge migration docs to include (hopefully) clearer guidance on the steps required. It's inspired by @winksaville's work in #3426 but takes a more drastic approach to rewriting large sections.
* Add a prominent _When?_ section
* Add links to execution engine configuration guides
* Add links to community guides
* Fix the location of the _Strict fee recipient_ section
## Issue Addressed
#3418
## Proposed Changes
- Remove `eth/v2/validator/blinded_blocks/{slot}` as this endpoint does not exist in the spec.
- Return `version` in the `eth/v1/validator/blinded_blocks/{slot}` endpoint.
## Additional Info
Since this removes the `v2` endpoint, this is *technically* a breaking change, but as this does not exist in the spec users may or may not be relying on this.
Depending on what we feel is appropriate, I'm happy to edit this so we keep the `v2` endpoint for now but simply bring the `v1` endpoint in line with `v2`.
## Issue Addressed
Fixes#2967
## Proposed Changes
Collect validator indices alongside attestations when creating signed
attestations (and aggregates) for inclusion in the logs.
## Additional Info
This is my first time looking at Lighthouse source code and using Rust, so newbie feedback appreciated!
## Issue Addressed
A 204 from the connected builder just indicates there's no payload available from the builder, not that there's an issue. So I don't actually think this should be a warn. During the merge transition when we are pre-finalization a 204 will actually be expected. And maybe even longer if the relay chooses to delay providing payloads for a longer period post-merge.
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
https://github.com/status-im/nimbus-eth2/issues/3930
## Proposed Changes
We can trivially support beacon nodes which do not provide the `is_optimistic` field by wrapping the field in an `Option`.
## Issue Addressed
NA
## Proposed Changes
There was a regression in #3244 (released in v2.4.0) which stopped pruning fork choice (see [here](https://github.com/sigp/lighthouse/pull/3244#discussion_r935187485)).
This would form a very slow memory leak, using ~100mb per month. The release has been out for ~11 days, so users should not be seeing a dangerous increase in memory, *yet*.
Credits to @michaelsproul for noticing this 🎉
## Additional Info
NA
## Issue Addressed
NA
## Proposed Changes
Ensure that we read the current slot from the `fc_store` rather than the slot clock. This is because the `fc_store` will never allow the slot to go backwards, even if the system clock does. The `ProtoArray::find_head` function assumes a non-decreasing slot.
This issue can cause logs like this:
```
ERRO Error whist recomputing head, error: ForkChoiceError(ProtoArrayError("find_head failed: InvalidBestNode(InvalidBestNodeInfo { start_root: 0xb22655aa2ae23075a60bd40797b3ba220db33d6fb86fa7910f0ed48e34bda72f, justified_checkpoint: Checkpoint { epoch: Epoch(111569), root: 0xb22655aa2ae23075a60bd40797b3ba220db33d6fb86fa7910f0ed48e34bda72f }, finalized_checkpoint: Checkpoint { epoch: Epoch(111568), root: 0x6140797e40c587b0d3f159483bbc603accb7b3af69891979d63efac437f9896f }, head_root: 0xb22655aa2ae23075a60bd40797b3ba220db33d6fb86fa7910f0ed48e34bda72f, head_justified_checkpoint: Some(Checkpoint { epoch: Epoch(111568), root: 0x6140797e40c587b0d3f159483bbc603accb7b3af69891979d63efac437f9896f }), head_finalized_checkpoint: Some(Checkpoint { epoch: Epoch(111567), root: 0x59b913d37383a158a9ea5546a572acc79e2cdfbc904c744744789d2c3814c570 }) })")), service: beacon, module: beacon_chain::canonical_head:499
```
We expect nodes to automatically recover from this issue within seconds without any major impact. However, having *any* errors in the path of fork choice is undesirable and should be avoided.
## Additional Info
NA
## Proposed Changes
Add a list of schema version changes to the book.
I hope this will be helpful for users upgrading to v2.5.0, to know that they can downgrade to schema v9 to run v2.3.0/v2.4.0 or to schema v8 to run v2.2.0/v2.1.0.
## Issue Addressed
Fixes an issue identified by @remyroy whereby we were logging a recommendation to use `--eth1-endpoints` on merge-ready setups (when the execution layer was out of sync).
## Proposed Changes
I took the opportunity to clean up the other eth1-related logs, replacing "eth1" by "deposit contract" or "execution" as appropriate.
I've downgraded the severity of the `CRIT` log to `ERRO` and removed most of the recommendation text. The reason being that users lacking an execution endpoint will be informed by the new `WARN Not merge ready` log pre-Bellatrix, or the regular errors from block verification post-Bellatrix.
## Issue Addressed
NA
## Proposed Changes
This PR will make Lighthouse return blocks with invalid payloads via the API with `execution_optimistic = true`. This seems a bit awkward, however I think it's better than returning a 404 or some other error.
Let's consider the case where the only possible head is invalid (#3370 deals with this). In such a scenario all of the duties endpoints will start failing because the head is invalid. I think it would be better if the duties endpoints continue to work, because it's likely that even though the head is invalid the duties are still based upon valid blocks and we want the VC to have them cached. There's no risk to the VC here because we won't actually produce an attestation pointing to an invalid head.
Ultimately, I don't think it's particularly important for us to distinguish between optimistic and invalid blocks on the API. Neither should be trusted and the only *real* reason that we track this is so we can try and fork around the invalid blocks.
## Additional Info
- ~~Blocked on #3370~~
## Issue Addressed
Enable https://github.com/sigp/lighthouse/pull/3322 by default on all networks.
The feature can be opted out of using `--count-unrealized=false` (the CLI flag is updated to take a parameter).
## Issue Addressed
N/A
## Proposed Changes
Uses the `penalize_peer` function added in #3350 in sync methods as well. The existing code in sync methods missed the `ExecutionPayloadError::UnverifiedNonOptimisticCandidate` case.
## Issue Addressed
https://github.com/sigp/lighthouse/issues/3091
Extends https://github.com/sigp/lighthouse/pull/3062, adding pre-bellatrix block support on blinded endpoints and allowing the normal proposal flow (local payload construction) on blinded endpoints. This resulted in better fallback logic because the VC will not have to switch endpoints on failure in the BN <> Builder API, the BN can just fallback immediately and without repeating block processing that it shouldn't need to. We can also keep VC fallback from the VC<>BN API's blinded endpoint to full endpoint.
## Proposed Changes
- Pre-bellatrix blocks on blinded endpoints
- Add a new `PayloadCache` to the execution layer
- Better fallback-from-builder logic
## Todos
- [x] Remove VC transition logic
- [x] Add logic to only enable builder flow after Merge transition finalization
- [x] Tests
- [x] Fix metrics
- [x] Rustdocs
Co-authored-by: Mac L <mjladson@pm.me>
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
NA
## Proposed Changes
There are scenarios where the only viable head will have an invalid execution payload, in this scenario the `get_head` function on `proto_array` will return an error. We must recover from this scenario by importing blocks from the network.
This PR stops `BeaconChain::recompute_head` from returning an error so that we can't accidentally start down-scoring peers or aborting block import just because the current head has an invalid payload.
## Reviewer Notes
The following changes are included:
1. Allow `fork_choice.get_head` to fail gracefully in `BeaconChain::process_block` when trying to update the `early_attester_cache`; simply don't add the block to the cache rather than aborting the entire process.
1. Don't return an error from `BeaconChain::recompute_head_at_current_slot` and `BeaconChain::recompute_head` to defensively prevent calling functions from aborting any process just because the fork choice function failed to run.
- This should have practically no effect, since most callers were still continuing if recomputing the head failed.
- The outlier is that the API will return 200 rather than a 500 when fork choice fails.
1. Add the `ProtoArrayForkChoice::set_all_blocks_to_optimistic` function to recover from the scenario where we've rebooted and the persisted fork choice has an invalid head.
## Issue Addressed
Closes https://github.com/sigp/lighthouse/issues/3241
Closes https://github.com/sigp/lighthouse/issues/3242
## Proposed Changes
* [x] Implement logic to remove equivocating validators from fork choice per https://github.com/ethereum/consensus-specs/pull/2845
* [x] Update tests to v1.2.0-rc.1. The new test which exercises `equivocating_indices` is passing.
* [x] Pull in some SSZ abstractions from the `tree-states` branch that make implementing Vec-compatible encoding for types like `BTreeSet` and `BTreeMap`.
* [x] Implement schema upgrades and downgrades for the database (new schema version is V11).
* [x] Apply attester slashings from blocks to fork choice
## Additional Info
* This PR doesn't need the `BTreeMap` impl, but `tree-states` does, and I don't think there's any harm in keeping it. But I could also be convinced to drop it.
Blocked on #3322.
## Issue Addressed
The antithesis Docker builds starting failing once we made our MSRV later than 1.58. It seems like it was because there is a new "LLVM pass manager" used by rust by default in more recent versions. Adding a new flag disables usage of the new pass manager and allows builds to pass.
This adds a single flag to the antithesis `Dockerfile.libvoidstar`: `RUSTFLAGS="-Znew-llvm-pass-manager=no"`. But this flag requires us to use `nightly` so it also adds that, pinning to an arbitrary recent date.
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
#3369
## Proposed Changes
The goal is to make it possible to build Lighthouse without network access,
so builds can be reproducible.
This parallels the existing functionality in `common/deposit_contract/build.rs`,
which allows specifying a filename through the environment to avoid downloading
it. In this case, by specifying the version and making it available on the
filesystem, the existing logic will avoid a network download.
## Issue Addressed
Resolves#3351
## Proposed Changes
Returns a `ResourceUnavailable` rpc error if we are unable to serve full payloads to blocks by root and range requests because the execution layer is not synced.
## Additional Info
This PR also changes the penalties such that a `ResourceUnavailable` error is only penalized if it is an outgoing request. If we are syncing and aren't getting full block responses, then we don't have use for the peer. However, this might not be true for the incoming request case. We let the peer decide in this case if we are still useful or if we should be banned.
cc @divagant-martian please let me know if i'm missing something here.
## Issue Addressed
Unblock CI for this failure: https://github.com/sigp/lighthouse/runs/7529551988
The root cause is a disagreement between the test and Nethermind over whether the appropriate status for a payload with an unknown parent is SYNCING or ACCEPTED. According to the spec, SYNCING is correct so we should update the test to expect this correct behaviour. However Geth still returns `ACCEPTED`, so for now we allow either.
## Issue Addressed
Resolves#3151
## Proposed Changes
When fetching duties for sync committee contributions, check the value of `execution_optimistic` of the head block from the BN and refuse to sign any sync committee messages `if execution_optimistic == true`.
## Additional Info
- Is backwards compatible with older BNs
- Finding a way to add test coverage for this would be prudent. Open to suggestions.
## Issue Addressed
As specified in the [Beacon Chain API specs](https://github.com/ethereum/beacon-APIs/blob/master/apis/node/syncing.yaml#L32-L35) we should return `is_optimistic` as part of the response to a query for the `eth/v1/node/syncing` endpoint.
## Proposed Changes
Compute the optimistic status of the head and add it to the `SyncingData` response.
## Issue Addressed
Resolves#3267Resolves#3156
## Proposed Changes
- Move the log for fee recipient checks from proposer cache insertion into block proposal so we are directly checking what we get from the EE
- Only log when there is a discrepancy with the local EE, not when using the builder API. In the `builder-api` branch there is an `info` log when there is a discrepancy, I think it is more likely there will be a difference in fee recipient with the builder api because proposer payments might be made via a transaction in the block. Not really sure what patterns will become commong.
- Upgrade the log from a `warn` to an `error` - not actually sure which we want, but I think this is worth an error because the local EE with default transaction ordering I think should pretty much always use the provided fee recipient
- add a `strict-fee-recipient` flag to the VC so we only sign blocks with matching fee recipients. Falls back from the builder API to the local API if there is a discrepancy .
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
While messing with the deposit snapshot stuff, I had my proxy running and noticed the beacon node wasn't syncing the block cache continuously. There were long periods where it did nothing. I believe this was caused by a logical error introduced in #3234 that dealt with an issue that arose while syncing the block cache on Ropsten.
The problem is that when the block cache is initially syncing, it will trigger the logic that detects the cache is far behind the execution chain in time. This will trigger a batch syncing mechanism which is intended to sync further ahead than the chain would normally. But the batch syncing is actually slower than the range this function usually estimates (in this scenario).
## Proposed Changes
I believe I've fixed this function by taking the end of the range to be the maximum of (batch syncing range, usual range).
I've also renamed and restructured some things a bit. It's equivalent logic but I think it's more clear what's going on.
## Issue Addressed
Add a flag that optionally enables unrealized vote tracking. Would like to test out on testnets and benchmark differences in methods of vote tracking. This PR includes a DB schema upgrade to enable to new vote tracking style.
Co-authored-by: realbigsean <sean@sigmaprime.io>
Co-authored-by: Paul Hauner <paul@paulhauner.com>
Co-authored-by: sean <seananderson33@gmail.com>
Co-authored-by: Mac L <mjladson@pm.me>
## Issue Addressed
#3031
## Proposed Changes
Updates the following API endpoints to conform with https://github.com/ethereum/beacon-APIs/pull/190 and https://github.com/ethereum/beacon-APIs/pull/196
- [x] `beacon/states/{state_id}/root`
- [x] `beacon/states/{state_id}/fork`
- [x] `beacon/states/{state_id}/finality_checkpoints`
- [x] `beacon/states/{state_id}/validators`
- [x] `beacon/states/{state_id}/validators/{validator_id}`
- [x] `beacon/states/{state_id}/validator_balances`
- [x] `beacon/states/{state_id}/committees`
- [x] `beacon/states/{state_id}/sync_committees`
- [x] `beacon/headers`
- [x] `beacon/headers/{block_id}`
- [x] `beacon/blocks/{block_id}`
- [x] `beacon/blocks/{block_id}/root`
- [x] `beacon/blocks/{block_id}/attestations`
- [x] `debug/beacon/states/{state_id}`
- [x] `debug/beacon/heads`
- [x] `validator/duties/attester/{epoch}`
- [x] `validator/duties/proposer/{epoch}`
- [x] `validator/duties/sync/{epoch}`
Updates the following Server-Sent Events:
- [x] `events?topics=head`
- [x] `events?topics=block`
- [x] `events?topics=finalized_checkpoint`
- [x] `events?topics=chain_reorg`
## Backwards Incompatible
There is a very minor breaking change with the way the API now handles requests to `beacon/blocks/{block_id}/root` and `beacon/states/{state_id}/root` when `block_id` or `state_id` is the `Root` variant of `BlockId` and `StateId` respectively.
Previously a request to a non-existent root would simply echo the root back to the requester:
```
curl "http://localhost:5052/eth/v1/beacon/states/0xaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/root"
{"data":{"root":"0xaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"}}
```
Now it will return a `404`:
```
curl "http://localhost:5052/eth/v1/beacon/blocks/0xaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/root"
{"code":404,"message":"NOT_FOUND: beacon block with root 0xaaaa…aaaa","stacktraces":[]}
```
In addition to this is the block root `0x0000000000000000000000000000000000000000000000000000000000000000` previously would return the genesis block. It will now return a `404`:
```
curl "http://localhost:5052/eth/v1/beacon/blocks/0x0000000000000000000000000000000000000000000000000000000000000000"
{"code":404,"message":"NOT_FOUND: beacon block with root 0x0000…0000","stacktraces":[]}
```
## Additional Info
- `execution_optimistic` is always set, and will return `false` pre-Bellatrix. I am also open to the idea of doing something like `#[serde(skip_serializing_if = "Option::is_none")]`.
- The value of `execution_optimistic` is set to `false` where possible. Any computation that is reliant on the `head` will simply use the `ExecutionStatus` of the head (unless the head block is pre-Bellatrix).
Co-authored-by: Paul Hauner <paul@paulhauner.com>
## Issue Addressed
Closes https://github.com/sigp/lighthouse/issues/3189.
## Proposed Changes
- Always supply the justified block hash as the `safe_block_hash` when calling `forkchoiceUpdated` on the execution engine.
- Refactor the `get_payload` routine to use the new `ForkchoiceUpdateParameters` struct rather than just the `finalized_block_hash`. I think this is a nice simplification and that the old way of computing the `finalized_block_hash` was unnecessary, but if anyone sees reason to keep that approach LMK.
## Issue Addressed
- Resolves#3338
## Proposed Changes
This PR adds a new `--network goerli` flag that reuses the [Prater network configs](https://github.com/sigp/lighthouse/tree/stable/common/eth2_network_config/built_in_network_configs/prater).
As you'll see in #3338, there are several approaches to the problem of the Goerli/Prater alias. This approach achieves:
1. No duplication of the genesis state between Goerli and Prater.
- Upside: the genesis state for Prater is ~17mb, duplication would increase the size of the binary by that much.
2. When the user supplies `--network goerli`, they will get a datadir in `~/.lighthouse/goerli`.
- Upside: our docs stay correct when they declare a datadir is located at `~/.lighthouse/{network}`
- Downside: switching from `--network prater` to `--network goerli` will require some manual migration.
3. When using `--network goerli`, the [`config/spec`](https://ethereum.github.io/beacon-APIs/#/Config/getSpec) endpoint will return a [`CONFIG_NAME`](02a2b71d64/configs/mainnet.yaml (L11)) of "prater".
- Upside: VC running `--network prater` will still think it's on the same network as one using `--network goerli`.
- Downside: potentially confusing.
#3348 achieves the same goal as this PR with a different approach and set of trade-offs.
## Additional Info
### Notes for reviewers:
In e4896c2682 you'll see that I remove the `$name_str` by just using `stringify!($name_ident)` instead. This is a simplification that should have have been there in the first place.
Then, in 90b5e22fca I reclaim that second parameter with a new purpose; to specify the directory from which to load configs.
## Issue Addressed
Resolves#3249
## Proposed Changes
Log merge related parameters and EE status in the beacon notifier before the merge.
Co-authored-by: Paul Hauner <paul@paulhauner.com>
## Issue Addressed
* #3344
## Proposed Changes
There are a number of cases during block processing where we might get an `ExecutionPayloadError` but we shouldn't penalize peers. We were forgetting to enumerate all of the non-penalizing errors in every single match statement where we are making that decision. I created a function to make it explicit when we should and should not penalize peers and I used that function in all places where this logic is needed. This way we won't make the same mistake if we add another variant of `ExecutionPayloadError` in the future.
## Issue Addressed
Which issue # does this PR address?
## Proposed Changes
Please list or describe the changes introduced by this PR.
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
The lcli and antithesis docker builds are failing in unstable so bumping all the versions here
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
#3302
## Proposed Changes
Move the `reqwest::Client` from being initialized per-validator, to being initialized per distinct Web3Signer.
This is done by placing the `Client` into a `HashMap` keyed by the definition of the Web3Signer as specified by the `ValidatorDefintion`. This will allow multiple Web3Signers to be used with a single VC and also maintains backwards compatibility.
## Additional Info
This was done to reduce the memory used by the VC when connecting to a Web3Signer.
I set up a local testnet using [a custom script](https://github.com/macladson/lighthouse/tree/web3signer-local-test/scripts/local_testnet_web3signer) and ran a VC with 200 validator keys:
VC with Web3Signer:
- `unstable`: ~200MB
- With fix: ~50MB
VC with Local Signer:
- `unstable`: ~35MB
- With fix: ~35MB
> I'm seeing some fragmentation with the VC using the Web3Signer, but not when using a local signer (this is most likely due to making lots of http requests and dealing with lots of JSON objects). I tested the above using `MALLOC_ARENA_MAX=1` to try to reduce the fragmentation. Without it, the values are around +50MB for both `unstable` and the fix.
## Issue Addressed
Resolves#3316
## Proposed Changes
This PR fixes an issue where lighthouse created a transition block with `block.execution_payload().timestamp == terminal_block.timestamp` if the terminal block was created at the slot boundary.
## Issue Addressed
N/A
## Proposed Changes
Make simulator merge compatible. Adds a `--post_merge` flag to the eth1 simulator that enables a ttd and simulates the merge transition. Uses the `MockServer` in the execution layer test utils to simulate a dummy execution node.
Adds the merge transition simulation to CI.
## Issue Addressed
Resolves#3159
## Proposed Changes
Sends transactions to the EE before requesting for a payload in the `execution_integration_tests`. Made some changes to the integration tests in order to be able to sign and publish transactions to the EE:
1. `genesis.json` for both geth and nethermind was modified to include pre-funded accounts that we know private keys for
2. Using the unauthenticated port again in order to make `eth_sendTransaction` and calls from the `personal` namespace to import keys
Also added a `fcu` call with `PayloadAttributes` before calling `getPayload` in order to give EEs sufficient time to pack transactions into the payload.
Improves some of the functionality around single and parent block lookup.
Gives extra information about whether failures for lookups are related to processing or downloading.
This is entirely untested.
Co-authored-by: Diva M <divma@protonmail.com>
## Issue Addressed
Web3signer validators can't produce post-Bellatrix blocks.
## Proposed Changes
Add support for Bellatrix to web3signer validators.
## Additional Info
I am running validators with this code on Ropsten, but it may be a while for them to get a proposal.
## Proposed Changes
Adds some improvements I found when playing around with local testnets in #3335:
- When trying to kill processes, do not exit on a failure. (If a node fails to start due to a bug, the PID associated with it no longer exists. When trying to tear down the testnets, an error will be raised when it tries that PID and then will not try any PIDs following it. This change means it will continue and tear down the rest of the network.
- When starting the testnet, set `ulimit` to a high number. This allows the VCs to import 1000s of validators without running into limitations.
## Issue Addressed
Resolves#3314
## Proposed Changes
Add a module to encode/decode u256 types according to the execution layer encoding/decoding standards
https://github.com/ethereum/execution-apis/blob/main/src/engine/specification.md#structures
Updates `JsonExecutionPayloadV1.base_fee_per_gas`, `JsonExecutionPayloadHeaderV1.base_fee_per_gas` and `TransitionConfigurationV1.terminal_total_difficulty` to encode/decode according to standards
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Issue Addressed
Duplicate of #3269. Making this since @divagant-martian opened the previous PR and she can't approve her own PR 😄
Co-authored-by: Diva M <divma@protonmail.com>
## Issue Addressed
N/A
## Proposed Changes
Since Rust 1.62, we can use `#[derive(Default)]` on enums. ✨https://blog.rust-lang.org/2022/06/30/Rust-1.62.0.html#default-enum-variants
There are no changes to functionality in this PR, just replaced the `Default` trait implementation with `#[derive(Default)]`.
## Issue Addressed
NA
## Proposed Changes
After some discussion in Discord with @mkalinin it was raised that it was not the intention of the engine API to have CLs validate the `latest_valid_hash` (LVH) and all ancestors.
Whilst I believe the engine API is being updated such that the LVH *must* identify a valid hash or be set to some junk value, I'm not confident that we can rely upon the LVH as being valid (at least for now) due to the confusion surrounding it.
Being able to validate blocks via the LVH is a relatively minor optimisation; if the LVH value ends up becoming our head we'll send an fcU and get the VALID status there.
Falsely marking a block as valid has serious consequences and since it's a minor optimisation to use LVH I think that we don't take the risk.
For clarity, we will still *invalidate* the *descendants* of the LVH, we just wont *validate* the *ancestors*.
## Additional Info
NA
## Issue Addressed
Resolves#3176
## Proposed Changes
Continues from PRs by @divagant-martian to gradually remove EL redundancy (see #3284, #3257).
This PR achieves:
- Removes the `broadcast` and `first_success` methods. The functional impact is that every request to the EE will always be tried immediately, regardless of the cached `EngineState` (this resolves#3176). Previously we would check the engine state before issuing requests, this doesn't make sense in a single-EE world; there's only one EE so we might as well try it for every request.
- Runs the upcheck/watchdog routine once per slot rather than thrice. When we had multiple EEs frequent polling was useful to try and detect when the primary EE had come back online and we could switch to it. That's not as relevant now.
- Always creates logs in the `Engines::upcheck` function. Previously we would mute some logs since they could get really noisy when one EE was down but others were functioning fine. Now we only have one EE and are upcheck-ing it less, it makes sense to always produce logs.
This PR purposefully does not achieve:
- Updating all occurances of "engines" to "engine". I'm trying to keep the diff small and manageable. We can come back for this.
## Additional Info
NA
## Issue Addressed
- #3251
## Proposed Changes
Adds the release tag to the `disallowed_from_async` lint.
## Additional Info
~~I haven't run this locally yet due to (minor) complexity of running the lint, I'm seeing if it will work via Github.~~
## Issue Addressed
Resolves#3276.
## Proposed Changes
Add a timeout for the sync committee contributions at 1/4 the slot length such that we may be able to try backup beacon nodes in the case of contribution post failure.
## Additional Info
1/4 slot length seemed standard for the timeouts, but may want to decrease this to 1/2.
I did not find any timeout related / sync committee related tests, so there are no tests. Happy to write some with a bit of guidance.
## Issue Addressed
* #3173
## Proposed Changes
Moved all `fee_recipient_file` related logic inside the `ValidatorStore` as it makes more sense to have this all together there. I tested this with the validators I have on `mainnet-shadow-fork-5` and everything appeared to work well. Only technicality is that I can't get the method to return `401` when the authorization header is not specified (it returns `400` instead). Fixing this is probably quite difficult given that none of `warp`'s rejections have code `401`.. I don't really think this matters too much though as long as it fails.
## Issue Addressed
Follow up to https://github.com/sigp/lighthouse/pull/3290 that fixes a caching bug
## Proposed Changes
Build the committee cache for the new `POST /lighthouse/analysis/block_rewards` API. Due to an unusual quirk of the total active balance cache the API endpoint would sometimes fail after loading a state from disk which had a current epoch cache _but not_ a total active balance cache. This PR adds calls to build the caches immediately before they're required, and has been running smoothly with `blockdreamer` the last few days.
## Issue Addressed
Closes https://github.com/sigp/lighthouse/issues/3270
## Proposed Changes
Optimize the calculation of historic beacon committees in the HTTP API.
This is achieved by allowing committee caches to be constructed for historic epochs, and constructing these committee caches on the fly in the API. This is much faster than reconstructing the state at the requested epoch, which usually takes upwards of 20s, and sometimes minutes with SPRP=8192. The depth of the `randao_mixes` array allows us to look back 64K epochs/0.8 years from a single state, which is pretty awesome!
We always use the `state_id` provided by the caller, but will return a nice 400 error if the epoch requested is out of range for the state requested, e.g.
```bash
# Prater
curl "http://localhost:5052/eth/v1/beacon/states/3170304/committees?epoch=33538"
```
```json
{"code":400,"message":"BAD_REQUEST: epoch out of bounds, try state at slot 1081344","stacktraces":[]}
```
Queries will be fastest when aligned to `slot % SPRP == 0`, so the hint suggests a slot that is 0 mod 8192.
## Issue Addressed
Currently the execution-engine-integration test uses latest master for nethermind and geth, and right now the test fails using the latest unreleased commits.
## Proposed Changes
Fix the nethermind and geth revisions the test uses to the latest tag in each repo. This way we are not continuously testing unreleased code, which might even get reverted, and reduce the failures only to releases in each one.
Also improve error handling of the commands used to manage the git repos.
## Additional Info
na
Co-authored-by: Michael Sproul <micsproul@gmail.com>
## Overview
This rather extensive PR achieves two primary goals:
1. Uses the finalized/justified checkpoints of fork choice (FC), rather than that of the head state.
2. Refactors fork choice, block production and block processing to `async` functions.
Additionally, it achieves:
- Concurrent forkchoice updates to the EL and cache pruning after a new head is selected.
- Concurrent "block packing" (attestations, etc) and execution payload retrieval during block production.
- Concurrent per-block-processing and execution payload verification during block processing.
- The `Arc`-ification of `SignedBeaconBlock` during block processing (it's never mutated, so why not?):
- I had to do this to deal with sending blocks into spawned tasks.
- Previously we were cloning the beacon block at least 2 times during each block processing, these clones are either removed or turned into cheaper `Arc` clones.
- We were also `Box`-ing and un-`Box`-ing beacon blocks as they moved throughout the networking crate. This is not a big deal, but it's nice to avoid shifting things between the stack and heap.
- Avoids cloning *all the blocks* in *every chain segment* during sync.
- It also has the potential to clean up our code where we need to pass an *owned* block around so we can send it back in the case of an error (I didn't do much of this, my PR is already big enough 😅)
- The `BeaconChain::HeadSafetyStatus` struct was removed. It was an old relic from prior merge specs.
For motivation for this change, see https://github.com/sigp/lighthouse/pull/3244#issuecomment-1160963273
## Changes to `canonical_head` and `fork_choice`
Previously, the `BeaconChain` had two separate fields:
```
canonical_head: RwLock<Snapshot>,
fork_choice: RwLock<BeaconForkChoice>
```
Now, we have grouped these values under a single struct:
```
canonical_head: CanonicalHead {
cached_head: RwLock<Arc<Snapshot>>,
fork_choice: RwLock<BeaconForkChoice>
}
```
Apart from ergonomics, the only *actual* change here is wrapping the canonical head snapshot in an `Arc`. This means that we no longer need to hold the `cached_head` (`canonical_head`, in old terms) lock when we want to pull some values from it. This was done to avoid deadlock risks by preventing functions from acquiring (and holding) the `cached_head` and `fork_choice` locks simultaneously.
## Breaking Changes
### The `state` (root) field in the `finalized_checkpoint` SSE event
Consider the scenario where epoch `n` is just finalized, but `start_slot(n)` is skipped. There are two state roots we might in the `finalized_checkpoint` SSE event:
1. The state root of the finalized block, which is `get_block(finalized_checkpoint.root).state_root`.
4. The state root at slot of `start_slot(n)`, which would be the state from (1), but "skipped forward" through any skip slots.
Previously, Lighthouse would choose (2). However, we can see that when [Teku generates that event](de2b2801c8/data/beaconrestapi/src/main/java/tech/pegasys/teku/beaconrestapi/handlers/v1/events/EventSubscriptionManager.java (L171-L182)) it uses [`getStateRootFromBlockRoot`](de2b2801c8/data/provider/src/main/java/tech/pegasys/teku/api/ChainDataProvider.java (L336-L341)) which uses (1).
I have switched Lighthouse from (2) to (1). I think it's a somewhat arbitrary choice between the two, where (1) is easier to compute and is consistent with Teku.
## Notes for Reviewers
I've renamed `BeaconChain::fork_choice` to `BeaconChain::recompute_head`. Doing this helped ensure I broke all previous uses of fork choice and I also find it more descriptive. It describes an action and can't be confused with trying to get a reference to the `ForkChoice` struct.
I've changed the ordering of SSE events when a block is received. It used to be `[block, finalized, head]` and now it's `[block, head, finalized]`. It was easier this way and I don't think we were making any promises about SSE event ordering so it's not "breaking".
I've made it so fork choice will run when it's first constructed. I did this because I wanted to have a cached version of the last call to `get_head`. Ensuring `get_head` has been run *at least once* means that the cached values doesn't need to wrapped in an `Option`. This was fairly simple, it just involved passing a `slot` to the constructor so it knows *when* it's being run. When loading a fork choice from the store and a slot clock isn't handy I've just used the `slot` that was saved in the `fork_choice_store`. That seems like it would be a faithful representation of the slot when we saved it.
I added the `genesis_time: u64` to the `BeaconChain`. It's small, constant and nice to have around.
Since we're using FC for the fin/just checkpoints, we no longer get the `0x00..00` roots at genesis. You can see I had to remove a work-around in `ef-tests` here: b56be3bc2. I can't find any reason why this would be an issue, if anything I think it'll be better since the genesis-alias has caught us out a few times (0x00..00 isn't actually a real root). Edit: I did find a case where the `network` expected the 0x00..00 alias and patched it here: 3f26ac3e2.
You'll notice a lot of changes in tests. Generally, tests should be functionally equivalent. Here are the things creating the most diff-noise in tests:
- Changing tests to be `tokio::async` tests.
- Adding `.await` to fork choice, block processing and block production functions.
- Refactor of the `canonical_head` "API" provided by the `BeaconChain`. E.g., `chain.canonical_head.cached_head()` instead of `chain.canonical_head.read()`.
- Wrapping `SignedBeaconBlock` in an `Arc`.
- In the `beacon_chain/tests/block_verification`, we can't use the `lazy_static` `CHAIN_SEGMENT` variable anymore since it's generated with an async function. We just generate it in each test, not so efficient but hopefully insignificant.
I had to disable `rayon` concurrent tests in the `fork_choice` tests. This is because the use of `rayon` and `block_on` was causing a panic.
Co-authored-by: Mac L <mjladson@pm.me>
## Issue Addressed
NA
## Proposed Changes
This is a fairly simple micro-optimization to avoid using `Vec::grow`. I don't believe this will have a substantial effect on block processing times, however it was showing up in flamegraphs. I think it's worth making this change for general memory-hygiene.
## Additional Info
NA
## Issue Addressed
This PR is a subset of the changes in #3134. Unstable will still not function correctly with the new builder spec once this is merged, #3134 should be used on testnets
## Proposed Changes
- Removes redundancy in "builders" (servers implementing the builder spec)
- Renames `payload-builder` flag to `builder`
- Moves from old builder RPC API to new HTTP API, but does not implement the validator registration API (implemented in https://github.com/sigp/lighthouse/pull/3194)
Co-authored-by: sean <seananderson33@gmail.com>
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
Lays the groundwork for builder API changes by implementing the beacon-API's new `register_validator` endpoint
## Proposed Changes
- Add a routine in the VC that runs on startup (re-try until success), once per epoch or whenever `suggested_fee_recipient` is updated, signing `ValidatorRegistrationData` and sending it to the BN.
- TODO: `gas_limit` config options https://github.com/ethereum/builder-specs/issues/17
- BN only sends VC registration data to builders on demand, but VC registration data *does update* the BN's prepare proposer cache and send an updated fcU to a local EE. This is necessary for fee recipient consistency between the blinded and full block flow in the event of fallback. Having the BN only send registration data to builders on demand gives feedback directly to the VC about relay status. Also, since the BN has no ability to sign these messages anyways (so couldn't refresh them if it wanted), and validator registration is independent of the BN head, I think this approach makes sense.
- Adds upcoming consensus spec changes for this PR https://github.com/ethereum/consensus-specs/pull/2884
- I initially applied the bit mask based on a configured application domain.. but I ended up just hard coding it here instead because that's how it's spec'd in the builder repo.
- Should application mask appear in the api?
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Proposed Changes
Add a new HTTP endpoint `POST /lighthouse/analysis/block_rewards` which takes a vec of `BeaconBlock`s as input and outputs the `BlockReward`s for them.
Augment the `BlockReward` struct with the attestation data for attestations in the block, which simplifies access to this information from blockprint. Using attestation data I've been able to make blockprint up to 95% accurate across Prysm/Lighthouse/Teku/Nimbus. I hope to go even higher using a bunch of synthetic blocks produced for Prysm/Nimbus/Lodestar, which are underrepresented in the current training data.
## Proposed Changes
Update `Cross.toml` for the recently released Cross v0.2.2. This allows us to remove the dependency on my fork of the Cross Docker image, which was a maintenance burden and prone to bit-rot. This PR puts us back in sync with upstream Cross.
## Additional Info
Due to some bindgen errors on the default Cross images we seemingly need a full `clang-3.9` install. The `libclang-3.9-dev` package was found to be insufficient due to `stdarg.h` being missing.
In order to continue building locally all Lighthouse devs should update their local cross version with `cargo install cross`.
## Issue Addressed
Fixes#1864 and a bunch of other closed but unresolved issues.
## Proposed Changes
Allows the deposit caching to recover from `NonConsecutive` deposit errors by resetting the last processed block to the last valid deposit's block number. Still not sure of the underlying cause of this error, but this should recover the cache so we don't need `--eth1-purge-cache` anymore 🎉
A huge thanks to @one-three-three-seven for reproducing the error and providing the data that helped testing out the fix 🙌
Still needs a few more tests.
## Proposed Changes
Expand the set of paths tracked by the HTTP API metrics to include all paths hit by the validator client.
These paths were only partially updated for Altair, so we were missing some of the sync committee and v2 APIs.
## Issue Addressed
NA
## Proposed Changes
I used these logs when debugging a spurious failure with Infura and thought they might be nice to have around permanently.
There's no changes to functionality in this PR, just some additional `debug!` logs.
## Additional Info
NA
## Issue Addressed
Deprecates the step parameter in the blocks by range request
## Proposed Changes
- Modifies the BlocksByRangeRequest type to remove the step parameter and everywhere we took it into account before
- Adds a new type to still handle coding and decoding of requests that use the parameter
## Additional Info
I went with a deprecation over the type itself so that requests received outside `lighthouse_network` don't even need to deal with this parameter. After the deprecation period just removing the Old blocks by range request should be straightforward
## Issue Addressed
Following up from https://github.com/sigp/lighthouse/pull/3223#issuecomment-1158718102, it has been observed that the validator client uses vastly more memory in some compilation configurations than others. Compiling with Cross and then putting the binary into an Ubuntu 22.04 image seems to use 3x more memory than compiling with Cargo directly on Debian bullseye.
## Proposed Changes
Enable malloc metrics for the validator client. This will hopefully allow us to see the difference between the two compilation configs and compare heap fragmentation. This PR doesn't enable malloc tuning for the VC because it was found to perform significantly worse. The `--disable-malloc-tuning` flag is repurposed to just disable the metrics.
## Issue Addressed
Closes https://github.com/sigp/lighthouse/issues/2944
## Proposed Changes
Remove snapshots from the cache during sync rather than cloning them. This reduces unnecessary cloning and memory fragmentation during sync.
## Additional Info
This PR relies on the fact that the `block_delay` cache is not populated for blocks from sync. Relying on block delay may have the side effect that a change in `block_delay` calculation could lead to: a) more clones, if block delays are added for syncing blocks or b) less clones, if blocks near the head are erroneously provided without a `block_delay`. Case (a) would be a regression to the current status quo, and (b) is low-risk given we know that the snapshot cache is current susceptible to misses (hence `tree-states`).
## Issue Addressed
#2820
## Proposed Changes
The problem is that validator_monitor_prev_epoch metrics are updated only if there is EpochSummary present in summaries map for the previous epoch and it is not the case for the offline validator. Ensure that EpochSummary is inserted into summaries map also for the offline validators.
## Issue Addressed
Partly resolves https://github.com/sigp/lighthouse/issues/3032
## Proposed Changes
Extracts some of the functionality of #3094 into a separate PR as the original PR requires a bit more work.
Do not unnecessarily penalize peers when we fail to validate received execution payloads because our execution layer is offline.
## Issue Addressed
Which issue # does this PR address?
## Proposed Changes
Please list or describe the changes introduced by this PR.
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
## Issue Addressed
NA
## Proposed Changes
- Uses a `Vec` in `SingleEpochParticipationCache` rather than `HashMap` to speed up processing times at the cost of memory usage.
- Cache the result of `integer_sqrt` rather than recomputing for each validator.
- Cache `state.previous_epoch` rather than recomputing it for each validator.
### Benchmarks
Benchmarks on a recent mainnet state using #3252 to get timing.
#### Without this PR
```
lcli skip-slots --state-path /tmp/state-0x3cdc.ssz --partial-state-advance --slots 32 --state-root 0x3cdc33cd02713d8d6cc33a6dbe2d3a5bf9af1d357de0d175a403496486ff845e --runs 10
[2022-06-09T08:21:02Z INFO lcli::skip_slots] Using mainnet spec
[2022-06-09T08:21:02Z INFO lcli::skip_slots] Advancing 32 slots
[2022-06-09T08:21:02Z INFO lcli::skip_slots] Doing 10 runs
[2022-06-09T08:21:02Z INFO lcli::skip_slots] State path: "/tmp/state-0x3cdc.ssz"
SSZ decoding /tmp/state-0x3cdc.ssz: 43ms
[2022-06-09T08:21:03Z INFO lcli::skip_slots] Run 0: 245.718794ms
[2022-06-09T08:21:03Z INFO lcli::skip_slots] Run 1: 245.364782ms
[2022-06-09T08:21:03Z INFO lcli::skip_slots] Run 2: 255.866179ms
[2022-06-09T08:21:04Z INFO lcli::skip_slots] Run 3: 243.838909ms
[2022-06-09T08:21:04Z INFO lcli::skip_slots] Run 4: 250.431425ms
[2022-06-09T08:21:04Z INFO lcli::skip_slots] Run 5: 248.68765ms
[2022-06-09T08:21:04Z INFO lcli::skip_slots] Run 6: 262.051113ms
[2022-06-09T08:21:05Z INFO lcli::skip_slots] Run 7: 264.293967ms
[2022-06-09T08:21:05Z INFO lcli::skip_slots] Run 8: 293.202007ms
[2022-06-09T08:21:05Z INFO lcli::skip_slots] Run 9: 264.552017ms
```
#### With this PR:
```
lcli skip-slots --state-path /tmp/state-0x3cdc.ssz --partial-state-advance --slots 32 --state-root 0x3cdc33cd02713d8d6cc33a6dbe2d3a5bf9af1d357de0d175a403496486ff845e --runs 10
[2022-06-09T08:57:59Z INFO lcli::skip_slots] Run 0: 73.898678ms
[2022-06-09T08:57:59Z INFO lcli::skip_slots] Run 1: 75.536978ms
[2022-06-09T08:57:59Z INFO lcli::skip_slots] Run 2: 75.176104ms
[2022-06-09T08:57:59Z INFO lcli::skip_slots] Run 3: 76.460828ms
[2022-06-09T08:57:59Z INFO lcli::skip_slots] Run 4: 75.904195ms
[2022-06-09T08:58:00Z INFO lcli::skip_slots] Run 5: 75.53077ms
[2022-06-09T08:58:00Z INFO lcli::skip_slots] Run 6: 74.745572ms
[2022-06-09T08:58:00Z INFO lcli::skip_slots] Run 7: 75.823489ms
[2022-06-09T08:58:00Z INFO lcli::skip_slots] Run 8: 74.892055ms
[2022-06-09T08:58:00Z INFO lcli::skip_slots] Run 9: 76.333569ms
```
## Additional Info
NA
## Description
Add a new lint to CI that attempts to detect calls to functions like `block_on` from async execution contexts. This lint was written from scratch exactly for this purpose, on my fork of Clippy: https://github.com/michaelsproul/rust-clippy/tree/disallow-from-async
## Additional Info
- I've successfully detected the previous two issues we had with `block_on` by running the linter on the commits prior to each of these PRs: https://github.com/sigp/lighthouse/pull/3165, https://github.com/sigp/lighthouse/pull/3199.
- The lint runs on CI with `continue-on-error: true` so that if it fails spuriously it won't block CI.
- I think it would be good to merge this PR before https://github.com/sigp/lighthouse/pull/3244 so that we can lint the extensive executor-related changes in that PR.
- I aim to upstream the lint to Clippy, at which point building a custom version of Clippy from my fork will no longer be necessary. I imagine this will take several weeks or months though, because the code is currently a bit hacky and will need some renovations to pass review.
## Issue Addressed
Newer versions of MDBX have removed Windows and macOS support, so this PR pins MDBX at the last working version to prevent an accidental regression via `cargo update`.
## Additional Info
This is a short-term solution, if our pinned version of MDBX turns out to be buggy we will need to consider backporting patches from upstream to our own fork.
## Issue Addressed
Failures in our CI integration tests for Geth.
## Proposed Changes
Only connect to the authenticated execution endpoints during execution tests.
This is necessary now that it is impossible to connect to the `engine` api on an unauthenticated endpoint.
See https://github.com/ethereum/go-ethereum/pull/24997
## Additional Info
As these tests break semi-regularly, I have kept logs enabled to ease future debugging.
I've also updated the Nethermind tests, although these weren't broken. This should future-proof us if Nethermind decides to follow suit with Geth
## Issue Addressed
currently we count a failed attempt for a syncing chain even if the peer is not at fault. This makes us do more work if the chain fails, and heavily penalize peers, when we can simply retry. Inspired by a proposal I made to #3094
## Proposed Changes
If a batch fails but the peer is not at fault, do not count the attempt
Also removes some annoying logs
## Additional Info
We still get a counter on ignored attempts.. just in case
## Issue Addressed
na
## Proposed Changes
Updates libp2p to https://github.com/libp2p/rust-libp2p/pull/2662
## Additional Info
From comments on the relevant PRs listed, we should pay attention at peer management consistency, but I don't think anything weird will happen.
This is running in prater tok and sin
## Issue Addressed
Fixes a timing issue that results in spurious fork choice notifier failures:
```
WARN Error signalling fork choice waiter slot: 3962270, error: ForkChoiceSignalOutOfOrder { current: Slot(3962271), latest: Slot(3962270) }, service: beacon
```
There’s a fork choice run that is scheduled to run at the start of every slot by the `timer`, which creates a 12s interval timer when the beacon node starts up. The problem is that if there’s a bit of clock drift that gets corrected via NTP (or a leap second for that matter) then these 12s intervals will cease to line up with the start of the slot. This then creates the mismatch in slot number that we see above.
Lighthouse also runs fork choice 500ms before the slot begins, and these runs are what is conflicting with the start-of-slot runs. This means that the warning in current versions of Lighthouse is mostly cosmetic because fork choice is up to date with all but the most recent 500ms of attestations (which usually isn’t many).
## Proposed Changes
Fix the per-slot timer so that it continually re-calculates the duration to the start of the next slot and waits for that.
A side-effect of this change is that we may skip slots if the per-slot task takes >12s to run, but I think this is an unlikely scenario and an acceptable compromise.
## Issue Addressed
Reduces the effect of late blocks on overall node buildup
## Proposed Changes
change the capacity of the channels used to send work for reprocessing in the beacon processor, and to send back to the main processor task, to be 75% of the capacity of the channel for receiving new events
## Additional Info
The issues we've seen suggest we should still evaluate node performance under stress, with late blocks being a big factor.
Other changes that could help:
1. right now we have a cap for queued attestations for reprocessing that applies to the sum of aggregated and unaggregated attestations. We could consider adding a separate cap that favors aggregated ones.
2. solving #2848
## Issue Addressed
Fix for the eth1 cache sync issue observed on Ropsten.
## Proposed Changes
Ropsten blocks are so infrequent that they broke our algorithm for downloading eth1 blocks. We currently try to download forwards from the last block in our cache to the block with block number [`remote_highest_block - FOLLOW_DISTANCE + FOLLOW_DISTANCE / ETH1_BLOCK_TIME_TOLERANCE_FACTOR`](6f732986f1/beacon_node/eth1/src/service.rs (L489-L492)). With the tolerance set to 4 this is insufficient because we lag by 1536 blocks, which is more like ~14 hours on Ropsten. This results in us having an incomplete eth1 cache, because we should cache all blocks between -16h and -8h. Even if we were to set the tolerance to 2 for the largest allowance, we would only look back 1024 blocks which is still more than 8 hours.
For example consider this block https://ropsten.etherscan.io/block/12321390. The block from 1536 blocks earlier is 14 hours and 20 minutes before it: https://ropsten.etherscan.io/block/12319854. The block from 1024 blocks earlier is https://ropsten.etherscan.io/block/12320366, 8 hours and 48 minutes before.
- This PR introduces a new CLI flag called `--eth1-cache-follow-distance` which can be used to set the distance manually.
- A new dynamic catchup mechanism is added which detects when the cache is lagging the true eth1 chain and tries to download more blocks within the follow distance in order to catch up.
## Issue Addressed
N/A
## Proposed Changes
Preemptively switch Nethermind integration tests to use the `master` branch along with the baked in `kiln` config.
## Additional Info
There have been some spurious timeouts across CI so this also increases the timeout to 20s.
## Issue Addressed
#3156
## Proposed Changes
Emit a `WARN` log whenever the value of `fee_recipient` as returned from the EE is different from the value of `suggested_fee_recipient` as set on the BN, for example by the `--suggested-fee-recipient` CLI flag.
## Additional Info
I have set the log level to `WARN` since it is legal behaviour (meaning it isn't really an error but is important to know when it is occurring).
If we feel like this behaviour is almost always undesired (caused by a misconfiguration or malicious EE) then an `ERRO` log would be more appropriate. Happy to change it in that case.
## Issue Addressed
N/A
## Proposed Changes
Use stable version of ubuntu base image in dockerfile instead of using latest. This will help in narrowing down issues with docker images.
## Proposed Changes
Speed up epoch processing by around 10% by inlining methods from the `safe_arith` crate.
The Rust standard library uses `#[inline]` for the `checked_` functions that we're wrapping, so it makes sense for us to inline them too.
## Additional Info
I conducted a brief statistical test on the block at slot [3858336](https://beaconcha.in/block/3858336) applied to the state at slot 3858335, which requires an epoch transition. The command used for testing was:
```
lcli transition-blocks --testnet-dir ./common/eth2_network_config/built_in_network_configs/mainnet --no-signature-verification state.ssz block.ssz output.ssz
```
The testing found that inlining reduced the epoch transition time from 398ms to 359ms, a reduction of 9.77%, which was found to be statistically significant with a two-tailed t-test (p < 0.01). Data and intermediate calculations can be found here: https://docs.google.com/spreadsheets/d/1tlf3eFjz3dcXeb9XVOn21953uYpc9RdQapPtcHGH1PY
## Issue Addressed
We were logging `out_finalized_epoch` instead of `our_finalized_epoch`. I noticed this ages ago but only just got around to fixing it.
## Additional Info
I also reformatted the log line to respect the line length limit (`rustfmt` won't do it because it gets confused by the `;` in slog's log macros).
## Proposed Changes
It's reasonably often that we want to manually convert an attestation to indexed form. This PR adds an `lcli` command for doing this, using an SSZ state and a list of JSON attestations (as extracted from a JSON block) as input.
## Issue Addressed
NA
## Proposed Changes
Please list or describe the changes introduced by this PR.
## Additional Info
- Pending testing on our infra. **Please do not merge**
## Issue Addressed
#3212
## Proposed Changes
Move chain segments coming from back-fill syncing from highest priority to lowest
## Additional Info
If this does not solve the issue, next steps would be lowering the batch size for back-fill sync, and as last resort throttling the processing of these chain segments
## Issue Addressed
#3154
## Proposed Changes
Add three new metrics for the VC:
1. `vc_beacon_nodes_synced_count`
2. `vc_beacon_nodes_available_count`
3. `vc_beacon_nodes_total_count`
Their values mirror the values present in the following log line:
```
Apr 08 17:25:17.000 INFO Connected to beacon node(s) synced: 4, available: 4, total: 4, service: notifier
```
## Issue Addressed
Fixes an issue that @paulhauner found with the v2.3.0 release candidate whereby the fork choice runs introduced by #3168 tripped over each other during sync:
```
May 24 23:06:40.542 WARN Error signalling fork choice waiter slot: 3884129, error: ForkChoiceSignalOutOfOrder { current: Slot(3884131), latest: Slot(3884129) }, service: beacon
```
This can occur because fork choice is called from the state advance _and_ the per-slot task. When one of these runs takes a long time it can end up finishing after a run from a later slot, tripping the error above. The problem is resolved by not running either of these fork choice calls during sync.
Additionally, these parallel fork choice runs were causing issues in the database:
```
May 24 07:49:05.098 WARN Found a chain that should already have been pruned, head_slot: 92925, head_block_root: 0xa76c7bf1b98e54ed4b0d8686efcfdf853484e6c2a4c67e91cbf19e5ad1f96b17, service: beacon
May 24 07:49:05.101 WARN Database migration failed error: HotColdDBError(FreezeSlotError { current_split_slot: Slot(92608), proposed_split_slot: Slot(92576) }), service: beacon
```
In this case, two fork choice calls triggering the finalization processing were being processed out of order due to differences in their processing time, causing the background migrator to try to advance finalization _backwards_ 😳. Removing the parallel fork choice runs from sync effectively addresses the issue, because these runs are most likely to have different finalized checkpoints (because of the speed at which fork choice advances during sync). In theory it's still possible to process updates out of order if any other fork choice runs end up completing out of order, but this should be much less common. Fixing out of order fork choice runs in general is difficult as it requires architectural changes like serialising fork choice updates through a single thread, or locking fork choice along with the head when it is mutated (https://github.com/sigp/lighthouse/pull/3175).
## Proposed Changes
* Don't run per-slot fork choice during sync (if head is older than 4 slots)
* Don't run state-advance fork choice during sync (if head is older than 4 slots)
* Check for monotonic finalization updates in the background migrator. This is a good defensive check to have, and I'm not sure why we didn't have it before (we may have had it and wrongly removed it).
## Proposed Changes
Add documentation for the `lighthouse db migate` command, which users will be able to use to downgrade from Lighthouse v2.3.0 on non-merge networks (mainnet & Prater).
I think it's important to get this into the live instance of the book so we can link to it from the v2.3.0 release notes.
*This PR was adapted from @pawanjay176's work in #3197.*
## Issue Addressed
Fixes a regression in https://github.com/sigp/lighthouse/pull/3168
## Proposed Changes
https://github.com/sigp/lighthouse/pull/3168 added calls to `fork_choice` in `BeaconChain::per_slot_task` function. This leads to a panic as `per_slot_task` is called from an async context which calls fork choice, which then calls `block_on`.
This PR changes the timer to call the `per_slot_task` function in a blocking thread.
Co-authored-by: Pawan Dhananjay <pawandhananjay@gmail.com>
## Issue Addressed
Removes the build status badge from the main README.md. I don't think it actually serves a purpose and it also has the downside that a spurious failure gives us a red badge. For example, v2.2.1 failed with a [spurious failure](https://github.com/sigp/lighthouse/runs/5984392665?check_suite_focus=true) and I can't see a way to re-trigger that run. It will be red until our next release.
The same test suite runs when we merge into `unstable`, so those tests must have already passed in order for the commits to get onto `stable` (assuming our workflow is followed). Github will send notifications on failed CI, so we'll still be alerted to a failure without checking this badge.
## Issue Addressed
This fixes the low-hanging Clippy lints introduced in Rust 1.61 (due any hour now). It _ignores_ one lint, because fixing it requires a structural refactor of the validator client that needs to be done delicately. I've started on that refactor and will create another PR that can be reviewed in more depth in the coming days. I think we should merge this PR in the meantime to unblock CI.
## Issue Addressed
NA
## Proposed Changes
Adds the configuration for the upcoming merge of the Ropsten network, as per:
https://github.com/eth-clients/merge-testnets/pull/9
Use the Ropsten network with: `lighthouse --network ropsten`
## Additional Info
This is still a work-in-progress. We should wait for the eth-clients/merge-testnets PR to be approved before merging this into our `unstable`.
## Issue Addressed
Upcoming spec change https://github.com/ethereum/consensus-specs/pull/2878
## Proposed Changes
1. Run fork choice at the start of every slot, and wait for this run to complete before proposing a block.
2. As an optimisation, also run fork choice 3/4 of the way through the slot (at 9s), _dequeueing attestations for the next slot_.
3. Remove the fork choice run from the state advance timer that occurred before advancing the state.
## Additional Info
### Block Proposal Accuracy
This change makes us more likely to propose on top of the correct head in the presence of re-orgs with proposer boost in play. The main scenario that this change is designed to address is described in the linked spec issue.
### Attestation Accuracy
This change _also_ makes us more likely to attest to the correct head. Currently in the case of a skipped slot at `slot` we only run fork choice 9s into `slot - 1`. This means the attestations from `slot - 1` aren't taken into consideration, and any boost applied to the block from `slot - 1` is not removed (it should be). In the language of the linked spec issue, this means we are liable to attest to C, even when the majority voting weight has already caused a re-org to B.
### Why remove the call before the state advance?
If we've run fork choice at the start of the slot then it has already dequeued all the attestations from the previous slot, which are the only ones eligible to influence the head in the current slot. Running fork choice again is unnecessary (unless we run it for the next slot and try to pre-empt a re-org, but I don't currently think this is a great idea).
### Performance
Based on Prater testing this adds about 5-25ms of runtime to block proposal times, which are 500-1000ms on average (and spike to 5s+ sometimes due to state handling issues 😢 ). I believe this is a small enough penalty to enable it by default, with the option to disable it via the new flag `--fork-choice-before-proposal-timeout 0`. Upcoming work on block packing and state representation will also reduce block production times in general, while removing the spikes.
### Implementation
Fork choice gets invoked at the start of the slot via the `per_slot_task` function called from the slot timer. It then uses a condition variable to signal to block production that fork choice has been updated. This is a bit funky, but it seems to work. One downside of the timer-based approach is that it doesn't happen automatically in most of the tests. The test added by this PR has to trigger the run manually.
## Issue Addressed
@z3n-chada is currently getting a `PayloadIdUnavailable` error when connecting lighthouse to Erigon and it's difficult to discern why so this just logs out the response status from the EE when we hit an `PayloadIdUnavailable` error
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
Web3Signer validators do not support client authentication. This means the `--tls-known-clients-file` option on Web3Signer can't be used with Lighthouse.
## Proposed Changes
Add two new fields to Web3Signer validators, `client_identity_path` and `client_identity_password`, which specify the path and password for a PKCS12 file containing a certificate and private key. If `client_identity_path` is present, use the certificate for SSL client authentication.
## Additional Info
I am successfully validating on Prater using client authentication with Web3Signer and client authentication.
## Issue Addressed
#3141
## Proposed Changes
Changes the algorithm for proposing blocks from
```
For each BN (first success):
- Produce a block
- Sign the block and store its root in the slashing protection DB
- Publish the block
```
to
```
For each BN (first success):
- Produce a block
Sign the block and store its root in the slashing protection DB
For each BN (first success):
- Publish the block
```
Separating the producing from the publishing makes sure that we only add a signed block once to the slashing DB.
## Issue Addressed
Which issue # does this PR address?
#3114
## Proposed Changes
1. introduce `mime` package
2. Parse `Accept` field in the header with `mime`
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
## Proposed Changes
Remove support for DB migrations that support upgrading from schema's below version 5. This is mostly for cosmetic/code quality reasons as in most circumstances upgrading from versions of Lighthouse this old will almost always require a re-sync.
## Additional Info
The minimum supported database schema is now version 5.
## Issue Addressed
N/A
## Proposed Changes
Prevents the early attester cache from producing attestations to future blocks. This bug could result in a missed head vote if the BN was requested to produce an attestation for an earlier slot than the head block during the (usually) short window of time between verifying a block and setting it as the head.
This bug was noticed in an [Antithesis](https://andreagrieser.com/) test and diagnosed by @realbigsean.
## Additional Info
NA
# Description
Since the `TaskExecutor` currently requires a `Weak<Runtime>`, it's impossible to use it in an async test where the `Runtime` is created outside our scope. Whilst we *could* create a new `Runtime` instance inside the async test, dropping that `Runtime` would cause a panic (you can't drop a `Runtime` in an async context).
To address this issue, this PR creates the `enum Handle`, which supports either:
- A `Weak<Runtime>` (for use in our production code)
- A `Handle` to a runtime (for use in testing)
In theory, there should be no change to the behaviour of our production code (beyond some slightly different descriptions in HTTP 500 errors), or even our tests. If there is no change, you might ask *"why bother?"*. There are two PRs (#3070 and #3175) that are waiting on these fixes to introduce some new tests. Since we've added the EL to the `BeaconChain` (for the merge), we are now doing more async stuff in tests.
I've also added a `RuntimeExecutor` to the `BeaconChainTestHarness`. Whilst that's not immediately useful, it will become useful in the near future with all the new async testing.
Code simplifications using `Option`/`Result` combinators to make pattern-matches a tad simpler.
Opinions on these loosely held, happy to adjust in review.
Tool-aided by [comby-rust](https://github.com/huitseeker/comby-rust).
## Proposed Changes
Remove the `lcli` code which performs block packing analysis.
The `lcli` code has been deprecated by a more performant version available in the HTTP API added in #2879.
## Additional Info
Any applications depending on the `lcli` code should migrate to the version in the HTTP API.
The only feature which is unavailable in the API version is an estimate of live/dead validators. This was originally used to determine a closer approximation of block packing efficiencies since offline validators have a disproportionate impact on efficiencies. However the implimentation in `lcli` is a poor approximation which cannot account for a multitude of factors. It is recommended to simply calculate relative efficiencies instead or use a more advanced method of determining live/dead validators.
## Proposed Changes
Reduce post-merge disk usage by not storing finalized execution payloads in Lighthouse's database.
⚠️ **This is achieved in a backwards-incompatible way for networks that have already merged** ⚠️. Kiln users and shadow fork enjoyers will be unable to downgrade after running the code from this PR. The upgrade migration may take several minutes to run, and can't be aborted after it begins.
The main changes are:
- New column in the database called `ExecPayload`, keyed by beacon block root.
- The `BeaconBlock` column now stores blinded blocks only.
- Lots of places that previously used full blocks now use blinded blocks, e.g. analytics APIs, block replay in the DB, etc.
- On finalization:
- `prune_abanonded_forks` deletes non-canonical payloads whilst deleting non-canonical blocks.
- `migrate_db` deletes finalized canonical payloads whilst deleting finalized states.
- Conversions between blinded and full blocks are implemented in a compositional way, duplicating some work from Sean's PR #3134.
- The execution layer has a new `get_payload_by_block_hash` method that reconstructs a payload using the EE's `eth_getBlockByHash` call.
- I've tested manually that it works on Kiln, using Geth and Nethermind.
- This isn't necessarily the most efficient method, and new engine APIs are being discussed to improve this: https://github.com/ethereum/execution-apis/pull/146.
- We're depending on the `ethers` master branch, due to lots of recent changes. We're also using a workaround for https://github.com/gakonst/ethers-rs/issues/1134.
- Payload reconstruction is used in the HTTP API via `BeaconChain::get_block`, which is now `async`. Due to the `async` fn, the `blocking_json` wrapper has been removed.
- Payload reconstruction is used in network RPC to serve blocks-by-{root,range} responses. Here the `async` adjustment is messier, although I think I've managed to come up with a reasonable compromise: the handlers take the `SendOnDrop` by value so that they can drop it on _task completion_ (after the `fn` returns). Still, this is introducing disk reads onto core executor threads, which may have a negative performance impact (thoughts appreciated).
## Additional Info
- [x] For performance it would be great to remove the cloning of full blocks when converting them to blinded blocks to write to disk. I'm going to experiment with a `put_block` API that takes the block by value, breaks it into a blinded block and a payload, stores the blinded block, and then re-assembles the full block for the caller.
- [x] We should measure the latency of blocks-by-root and blocks-by-range responses.
- [x] We should add integration tests that stress the payload reconstruction (basic tests done, issue for more extensive tests: https://github.com/sigp/lighthouse/issues/3159)
- [x] We should (manually) test the schema v9 migration from several prior versions, particularly as blocks have changed on disk and some migrations rely on being able to load blocks.
Co-authored-by: Paul Hauner <paul@paulhauner.com>
## Proposed Changes
Remove the bulky part of the EE integration test directory from the Docker build context so that we don't have to send 10GB of junk to the Docker daemon when building an image.
## Issue Addressed
#3068
## Proposed Changes
Adds support for remote key API.
## Additional Info
Needed to add `is_local_keystore` argument to `delete_definition_and_keystore` to know if we want to delete local or remote key. Previously this wasn't necessary because remotekeys(web3signers) could be deleted.
## Issue Addressed
Resolves#3102
## Proposed Changes
- https://github.com/sigp/lighthouse/issues/3102#issuecomment-1114835063
- This is not an ideal solution, since the commit hash is missing from version number, but I think it is sufficient.
## Additional Info
I've tested ... :
- `fallback` is updated via `change_version.sh`.
```shell
$ cd scripts/
$ ./change_version.sh 2.2.1 2.2.2
$ git diff ../common/lighthouse_version/src/lib.rs
```
```diff
@ common/lighthouse_version/src/lib.rs:20 @ pub const VERSION: &str = git_version!(
// NOTE: using --match instead of --exclude for compatibility with old Git
"--match=thiswillnevermatchlol"
],
- prefix = "Lighthouse/v2.2.1-",
- fallback = "Lighthouse/v2.2.1"
+ prefix = "Lighthouse/v2.2.2-",
+ fallback = "Lighthouse/v2.2.2"
);
```
- a package built without git info prints expected version number (v2.2.1).
```shell
$ git archive HEAD --output=/tmp/lighthouse.zip
$ cd /tmp
$ unzip lighthouse.zip
$ cd lighthouse
$ cargo build --release
$ target/release/lighthouse --version
Lighthouse v2.2.1
BLS library: blst
SHA256 hardware acceleration: false
Specs: mainnet (true), minimal (false), gnosis (false)
```
## Issue Addressed
Fix a panic due to misuse of the Tokio executor when processing a forkchoiceUpdated response. We were previously calling `process_invalid_execution_payload` from the async function `update_execution_engine_forkchoice_async`, which resulted in a panic because `process_invalid_execution_payload` contains a call to fork choice, which ultimately calls `block_on`.
An example backtrace can be found here: https://gist.github.com/michaelsproul/ac5da03e203d6ffac672423eaf52fb20
## Proposed Changes
Wrap the call to `process_invalid_execution_payload` in a `spawn_blocking` so that `block_on` is no longer called from an async context.
## Additional Info
- I've been thinking about how to catch bugs like this with static analysis (a new Clippy lint).
- The payload validation tests have been re-worked to support distinct responses from the mock EE for newPayload and forkchoiceUpdated. Three new tests have been added covering the `Invalid`, `InvalidBlockHash` and `InvalidTerminalBlock` cases.
- I think we need a bunch more tests of different legal and illegal variations
## Proposed Changes
Recently, changes to Nethermind's Kiln branch have broken our integration tests.
This PR updates the chainspec to Kiln to ensure proper compatibility.
## Issue Addressed
N/A
## Proposed Changes
Previously, we were using `Sleep::is_elapsed()` to check if the shutdown timeout had triggered without polling the sleep. This PR polls the sleep timer.
## Issue Addressed
We still ping peers that are considered in a disconnecting state
## Proposed Changes
Do not ping peers once we decide they are disconnecting
Upgrade logs about ignored rpc messages
## Additional Info
--
## Issue Addressed
NA
## Proposed Changes
Disallow the production of attestations and retrieval of unaggregated attestations when they reference an optimistic head. Add tests to this end.
I also moved `BeaconChain::produce_unaggregated_attestation_for_block` to the `BeaconChainHarness`. It was only being used during tests, so it's nice to stop pretending it's production code. I also needed something that could produce attestations to optimistic blocks in order to simulate scenarios where the justified checkpoint is determined invalid (if no one would attest to an optimistic block, we could never justify it and then flip it to invalid).
## Additional Info
- ~~Blocked on #3126~~
## Issue Addressed
In very rare occasions we've seen most if not all our peers in a chain with which we don't agree. Purging these peers can take a very long time: number of retries of the chain. Meanwhile sync is caught in a loop trying the chain again and again. This makes it so that we fast track purging peers via registering the failed chain to prevent retrying for some time (30 seconds). Longer times could be dangerous since a chain can fail if a batch fails to download for example. In this case, I think it's still acceptable to fast track purging peers since they are nor providing the required info anyway
Co-authored-by: Divma <26765164+divagant-martian@users.noreply.github.com>
## Issue Addressed
Addresses sync stalls on v2.2.0 (i.e. https://github.com/sigp/lighthouse/issues/3147).
## Additional Info
I've avoided doing a full `cargo update` because I noticed there's a new patch version of libp2p and thought it could do with some more testing.
Co-authored-by: Paul Hauner <paul@paulhauner.com>
## Issue Addressed
NA
## Proposed Changes
Fixes an issue introduced in #3088 which was causing unnecessary `crit` logs on networks without Bellatrix enabled.
## Additional Info
NA
## Issue Addressed
N/A
## Proposed Changes
https://github.com/sigp/lighthouse/pull/3133 changed the rpc type limits to be fork aware i.e. if our current fork based on wall clock slot is Altair, then we apply only altair rpc type limits. This is a bug because phase0 blocks can still be sent over rpc and phase 0 block minimum size is smaller than altair block minimum size. So a phase0 block with `size < SIGNED_BEACON_BLOCK_ALTAIR_MIN` will return an `InvalidData` error as it doesn't pass the rpc types bound check.
This error can be seen when we try syncing pre-altair blocks with size smaller than `SIGNED_BEACON_BLOCK_ALTAIR_MIN`.
This PR fixes the issue by also accounting for forks earlier than current_fork in the rpc limits calculation in the `rpc_block_limits_by_fork` function. I decided to hardcode the limits in the function because that seemed simpler than calculating previous forks based on current fork and doing a min across forks. Adding a new fork variant is simple and can the limits can be easily checked in a review.
Adds unit tests and modifies the syncing simulator to check the syncing from across fork boundaries.
The syncing simulator's block 1 would always be of phase 0 minimum size (404 bytes) which is smaller than altair min block size (since block 1 contains no attestations).
## Issue Addressed
NA
## Proposed Changes
Ensures that a `VALID` response from a `forkchoiceUpdate` call will update that block in `ProtoArray`.
I also had to modify the mock execution engine so it wouldn't return valid when all payloads were supposed to be some other static value.
## Additional Info
NA
## Issue Addressed
NA
## Proposed Changes
- Adds more checks to prevent importing blocks atop parent with invalid execution payloads.
- Adds a test for these conditions.
## Additional Info
NA
## Proposed Changes
Cut release v2.2.0 including proposer boost.
## Additional Info
I also updated the clippy lints for the imminent release of Rust 1.60, although LH v2.2.0 will continue to compile using Rust 1.58 (our MSRV).
## Proposed Changes
I did some gardening 🌳 in our dependency tree:
- Remove duplicate versions of `warp` (git vs patch)
- Remove duplicate versions of lots of small deps: `cpufeatures`, `ethabi`, `ethereum-types`, `bitvec`, `nix`, `libsecp256k1`.
- Update MDBX (should resolve#3028). I tested and Lighthouse compiles on Windows 11 now.
- Restore `psutil` back to upstream
- Make some progress updating everything to rand 0.8. There are a few crates stuck on 0.7.
Hopefully this puts us on a better footing for future `cargo audit` issues, and improves compile times slightly.
## Additional Info
Some crates are held back by issues with `zeroize`. libp2p-noise depends on [`chacha20poly1305`](https://crates.io/crates/chacha20poly1305) which depends on zeroize < v1.5, and we can only have one version of zeroize because it's post 1.0 (see https://github.com/rust-lang/cargo/issues/6584). The latest version of `zeroize` is v1.5.4, which is used by the new versions of many other crates (e.g. `num-bigint-dig`). Once a new version of chacha20poly1305 is released we can update libp2p-noise and upgrade everything to the latest `zeroize` version.
I've also opened a PR to `blst` related to zeroize: https://github.com/supranational/blst/pull/111
## Issue Addressed
N/A
## Proposed Changes
Fix the upper bound for blocks by root responses to be equal to the max merge block size instead of altair.
Further make the rpc response limits fork aware.
## Proposed Changes
Increase the default `--slots-per-restore-point` to 8192 for a 4x reduction in freezer DB disk usage.
Existing nodes that use the previous default of 2048 will be left unchanged. Newly synced nodes (with or without checkpoint sync) will use the new 8192 default.
Long-term we could do away with the freezer DB entirely for validator-only nodes, but this change is much simpler and grants us some extra space in the short term. We can also roll it out gradually across our nodes by purging databases one by one, while keeping the Ansible config the same.
## Additional Info
We ignore a change from 2048 to 8192 if the user hasn't set the 8192 explicitly. We fire a debug log in the case where we do ignore:
```
DEBG Ignoring slots-per-restore-point config in favour of on-disk value, on_disk: 2048, config: 8192
```
## Proposed Changes
Mitigate the fork choice attacks described in [_Three Attacks on Proof-of-Stake Ethereum_](https://arxiv.org/abs/2110.10086) by enabling proposer boost @ 70% on mainnet.
Proposer boost has been running with stability on Prater for a few months now, and is safe to roll out gradually on mainnet. I'll argue that the financial impact of rolling out gradually is also minimal.
Consider how a proposer-boosted validator handles two types of re-orgs:
## Ex ante re-org (from the paper)
In the mitigated attack, a malicious proposer releases their block at slot `n + 1` late so that it re-orgs the block at the slot _after_ them (at slot `n + 2`). Non-boosting validators will follow this re-org and vote for block `n + 1` in slot `n + 2`. Boosted validators will vote for `n + 2`. If the boosting validators are outnumbered, there'll be a re-org to the malicious block from `n + 1` and validators applying the boost will have their slot `n + 2` attestations miss head (and target on an epoch boundary). Note that all the attesters from slot `n + 1` are doomed to lose their head vote rewards, but this is the same regardless of boosting.
Therefore, Lighthouse nodes stand to miss slightly more head votes than other nodes if they are in the minority while applying the proposer boost. Once the proposer boost nodes gain a majority, this trend reverses.
## Ex post re-org (using the boost)
The other type of re-org is an ex post re-org using the strategy described here: https://github.com/sigp/lighthouse/pull/2860. With this strategy, boosted nodes will follow the attempted re-org and again lose a head vote if the re-org is unsuccessful. Once boosting is widely adopted, the re-orgs will succeed and the non-boosting validators will lose out.
I don't think there are (m)any validators applying this strategy, because it is irrational to attempt it before boosting is widely adopted. Therefore I think we can safely ignore this possibility.
## Risk Assessment
From observing re-orgs on mainnet I don't think ex ante re-orgs are very common. I've observed around 1 per day for the last month on my node (see: https://gist.github.com/michaelsproul/3b2142fa8fe0ff767c16553f96959e8c), compared to 2.5 ex post re-orgs per day.
Given one extra slot per day where attesting will cause a missed head vote, each individual validator has a 1/32 chance of being assigned to that slot. So we have an increase of 1/32 missed head votes per validator per day in expectation. Given that we currently see ~7 head vote misses per validator per day due to late/missing blocks (and re-orgs), this represents only a (1/32)/7 = 0.45% increase in missed head votes in expectation. I believe this is so small that we shouldn't worry about it. Particularly as getting proposer boost deployed is good for network health and may enable us to drive down the number of late blocks over time (which will decrease head vote misses).
## TL;DR
Enable proposer boost now and release ASAP, as financial downside is a 0.45% increase in missed head votes until widespread adoption.
## Proposed Changes
Add a `lighthouse db` command with three initial subcommands:
- `lighthouse db version`: print the database schema version.
- `lighthouse db migrate --to N`: manually upgrade (or downgrade!) the database to a different version.
- `lighthouse db inspect --column C`: log the key and size in bytes of every value in a given `DBColumn`.
This PR lays the groundwork for other changes, namely:
- Mark's fast-deposit sync (https://github.com/sigp/lighthouse/pull/2915), for which I think we should implement a database downgrade (from v9 to v8).
- My `tree-states` work, which already implements a downgrade (v10 to v8).
- Standalone purge commands like `lighthouse db purge-dht` per https://github.com/sigp/lighthouse/issues/2824.
## Additional Info
I updated the `strum` crate to 0.24.0, which necessitated some changes in the network code to remove calls to deprecated methods.
Thanks to @winksaville for the motivation, and implementation work that I used as a source of inspiration (https://github.com/sigp/lighthouse/pull/2685).
## Issue Addressed
MEV boost compatibility
## Proposed Changes
See #2987
## Additional Info
This is blocked on the stabilization of a couple specs, [here](https://github.com/ethereum/beacon-APIs/pull/194) and [here](https://github.com/flashbots/mev-boost/pull/20).
Additional TODO's and outstanding questions
- [ ] MEV boost JWT Auth
- [ ] Will `builder_proposeBlindedBlock` return the revealed payload for the BN to propogate
- [ ] Should we remove `private-tx-proposals` flag and communicate BN <> VC with blinded blocks by default once these endpoints enter the beacon-API's repo? This simplifies merge transition logic.
Co-authored-by: realbigsean <seananderson33@gmail.com>
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
N/A
## Proposed Changes
- Update the JSON-RPC id field for both our request and response objects to be a `serde_json::Value` rather than a `u32`. This field could be a string or a number according to the JSON-RPC 2.0 spec. We only ever set it to a number, but if, for example, we get a response that wraps this number in quotes, we would fail to deserialize it. I think because we're not doing any validation around this id otherwise, we should be less strict with it in this regard.
## Additional Info
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
NA
## Proposed Changes
In the first Goerli shadow-fork, Lighthouse was getting timeouts from Geth which prevented the LH+Geth pair from progressing.
There's not a whole lot of information I can use to set these timeouts. The most interesting pieces of information I have are quotes from Marius from Geth:
- *"Fcu also needs to construct the block which can take 2sec"* ([Discord](https://discord.com/channels/595666850260713488/910910348922589184/958006487052066836))
- *"2 sec should be ok for new payload, weird that it times out"* ([Discord](https://discord.com/channels/595666850260713488/910910348922589184/958006487052066836))
I don't think we should be so worried about getting these timeouts correct now. No one really knows how long the various EEs are going to take, it's a bit too early in development. With these changes I'm giving some headroom so that we don't fail just because EEs are quite optimized enough. I've set the value to 6s (half a mainnet slot), since I think anything beyond 6s is an interesting problem that we want to know about sooner rather than later.
## Additional Info
NA
## Issue Addressed
N/A
## Proposed Changes
Set the engine state to `EngineState::Offline` if the engine api call fails during broadcast. This caused issues while pausing sync when the execution engine is offline because `EngineState` always returned `Synced`.
## Issue Addressed
N/A
## Proposed Changes
The slashing db import log showed the latest proposed block in the db as `latest block` which might be potentially confusing.
## Proposed Changes
Allow Lighthouse to speculatively create blocks via the `/eth/v1/validators/blocks` endpoint by optionally skipping the RANDAO verification that we introduced in #2740. When `verify_randao=false` is passed as a query parameter the `randao_reveal` is not required to be present, and if present will only be lightly checked (must be a valid BLS sig). If `verify_randao` is omitted it defaults to true and Lighthouse behaves exactly as it did previously, hence this PR is backwards-compatible.
I'd like to get this change into `unstable` pretty soon as I've got 3 projects building on top of it:
- [`blockdreamer`](https://github.com/michaelsproul/blockdreamer), which mocks block production every slot in order to fingerprint clients
- analysis of Lighthouse's block packing _optimality_, which uses `blockdreamer` to extract interesting instances of the attestation packing problem
- analysis of Lighthouse's block packing _performance_ (as in speed) on the `tree-states` branch
## Additional Info
Having tested `blockdreamer` with Prysm, Nimbus and Teku I noticed that none of them verify the randao signature on `/eth/v1/validator/blocks`. I plan to open a PR to the `beacon-APIs` repo anyway so that this parameter can be standardised in case the other clients add RANDAO verification by default in future.
## Issue Addressed
No issue, just updating merge ASCII art.
## Proposed Changes
Updating ASCII art for merge.
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
## Issue Addressed
#3103
## Proposed Changes
Parse `http-address` and `metrics-address` as `IpAddr` for both the beacon node and validator client to support IPv6 addresses.
Also adjusts parsing of CORS origins to allow for IPv6 addresses.
## Usage
You can now set `http-address` and/or `metrics-address` flags to IPv6 addresses.
For example, the following:
`lighthouse bn --http --http-address :: --metrics --metrics-address ::1`
will expose the beacon node HTTP server on `[::]` (equivalent of `0.0.0.0` in IPv4) and the metrics HTTP server on `localhost` (the equivalent of `127.0.0.1` in IPv4)
The beacon node API can then be accessed by:
`curl "http://[server-ipv6-address]:5052/eth/v1/some_endpoint"`
And the metrics server api can be accessed by:
`curl "http://localhost:5054/metrics"` or by `curl "http://[::1]:5054/metrics"`
## Additional Info
On most Linux distributions the `v6only` flag is set to `false` by default (see the section for the `IPV6_V6ONLY` flag in https://www.man7.org/linux/man-pages/man7/ipv6.7.html) which means IPv4 connections will continue to function on a IPv6 address (providing it is appropriately mapped). This means that even if the Lighthouse API is running on `::` it is also possible to accept IPv4 connections.
However on Windows, this is not the case. The `v6only` flag is set to `true` so binding to `::` will only allow IPv6 connections.
## Issue Addressed
Removes the await points in sync waiting for a processor response for rpc block processing. Built on top of #3029
This also handles a couple of bugs in the previous code and adds a relatively comprehensive test suite.
## Issue Addressed
Attempt to fix CI
## Proposed Changes
- ~~install `node-gyp-build` which should look for prebuilt binaries for `@truffle-suite/bigint_buffer`. This should make it so we don't have to build it directly. See: https://github.com/trufflesuite/ganache/pull/1414~~ this didn't work
- This also uses the `setup-node` action because it includes caching. Sort of a shot in the dark, but the ganache github repo uses it and the failures seem to be for missing files in a node cache
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
Hopefully makes windows ganache installation more reliable.
## Proposed Changes
- use `chocolatey` to install windows build tools. This seems to often be the prescribed solution for `node gyp` issues. `chocolatey` is used here because `npm install --global --production windows-build-tools` hangs in github actions
## Additional Info
I still haven't found why the prior installation technique would sometimes work, the `windows-2019` environments seem to be identical across successes and failures. I think this should be re-run a few times to see if it can consistently pass
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
No issue
## Proposed Changes
Correct typos in book
## Additional Info
Nothing to add
Co-authored-by: Emilia Hane <58548332+emhane@users.noreply.github.com>
## Issue Addressed
Fix the `cargo-audit` failure for the recent openssl bug involving parsing of untrusted certificates (CVE-2022-0778).
## Additional Info
Lighthouse loads remote certificates in the following cases:
* When connecting to an eth1 node (`--eth1-endpoints`).
* When connecting to a beacon node from the VC (`--beacon-nodes`).
* When connecting to a beacon node for checkpoint sync (`--checkpoint-sync-url`).
In all of these cases we are already placing a lot of trust in the server at the other end, however due to the scope for MITM attacks we are still potentially vulnerable. E.g. an ISP could inject an invalid certificate for the remote host which would cause Lighthouse to hang indefinitely.
## Proposed Changes
Set a minimum supported Rust version (MSRV) in the `Cargo.toml` for the Lighthouse binary so that attempts to compile it with an outdated compiler fail immediately with a clear error.
To ensure that the codebase builds with the MSRV I've also added a Github actions job that runs `cargo check` using the MSRV extracted from `Cargo.toml`. This will force us to keep it up to date.
I opted to use `cargo check` rather than Clippy because Clippy frequently introduces new lints that we adopt, so our MSRV for Clippy is usually the most recent Rust version, while the MSRV for building Lighthouse is older.
## Issue Addressed
NA
## Proposed Changes
Address a CI failure in the release suite.
Example: https://github.com/sigp/lighthouse/actions/runs/1984266187
## Additional Info
I believe we should merge this into `unstable` and `stable`. Then, move the `v2.1.4` commit to target the commit with the updated CI. It's sad that v2.1.4 has two commits, but they're functionally equivalent for users.
## Issue Addressed
NA
## Proposed Changes
- Bump version to `v2.1.4`
- Run `cargo update`
## Additional Info
I think this release should be published around the 15th of March.
Presently `blocked` for testing on our infrastructure.
## Issue Addressed
#3073
## Proposed Changes
Add around `SAFE_SLOTS_TO_IMPORT_OPTIMISTICALLY` in the API
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
Which issue # does this PR address?
## Proposed Changes
Please list or describe the changes introduced by this PR.
## Additional Info
Please provide any additional information. For example, future considerations
or information useful for reviewers.
Co-authored-by: Pawan Dhananjay <pawandhananjay@gmail.com>
Co-authored-by: realbigsean <sean@sigmaprime.io>
## Issue Addressed
This address an issue which was preventing checkpoint-sync.
When the node starts from checkpoint sync, the head block and the finalized block are the same value. We did not respect this when sending a `forkchoiceUpdated` (fcU) call to the EL and were expecting fork choice to hold the *finalized ancestor of the head* and returning an error when it didn't.
This PR uses *only fork choice* for sending fcU updates. This is actually quite nice and avoids some atomicity issues between `chain.canonical_head` and `chain.fork_choice`. Now, whenever `chain.fork_choice.get_head` returns a value we also cache the values required for the next fcU call.
## TODO
- [x] ~~Blocked on #3043~~
- [x] Ensure there isn't a warn message at startup.
## Issue Addressed
Don't send an fcU message at startup if it's pre-genesis. The startup fcU message is not critical, not required by the spec, so it's fine to avoid it for networks that start post-Bellatrix fork.
## Issue Addressed
Presently if the VC is configured with a fee recipient it will error out when sending fee-recipient preparations to a beacon node that doesn't yet support the API:
```
Mar 08 22:23:36.236 ERRO Unable to publish proposer preparation error: All endpoints failed https://eth2-beacon-prater.infura.io/ => RequestFailed(StatusCode(404)), service: preparation
```
This doesn't affect other VC duties, but could be a source of anxiety for users trying to do the right thing and configure their fee recipients in advance.
## Proposed Changes
Change the preparation service to only send preparations if the current slot is later than 2 epochs before the Bellatrix hard fork epoch.
## Additional Info
I've tagged this v2.1.4 as I think it's a small change that's worth having for the next release
## Issue Addressed
Resolves#2936
## Proposed Changes
Adds functionality for calling [`validator/prepare_beacon_proposer`](https://ethereum.github.io/beacon-APIs/?urls.primaryName=dev#/Validator/prepareBeaconProposer) in advance.
There is a `BeaconChain::prepare_beacon_proposer` method which, which called, computes the proposer for the next slot. If that proposer has been registered via the `validator/prepare_beacon_proposer` API method, then the `beacon_chain.execution_layer` will be provided the `PayloadAttributes` for us in all future forkchoiceUpdated calls. An artificial forkchoiceUpdated call will be created 4s before each slot, when the head updates and when a validator updates their information.
Additionally, I added strict ordering for calls from the `BeaconChain` to the `ExecutionLayer`. I'm not certain the `ExecutionLayer` will always maintain this ordering, but it's a good start to have consistency from the `BeaconChain`. There are some deadlock opportunities introduced, they are documented in the code.
## Additional Info
- ~~Blocked on #2837~~
Co-authored-by: realbigsean <seananderson33@GMAIL.com>
## Issue Addressed
Resolves#3015
## Proposed Changes
Add JWT token based authentication to engine api requests. The jwt secret key is read from the provided file and is used to sign tokens that are used for authenticated communication with the EL node.
- [x] Interop with geth (synced `merge-devnet-4` with the `merge-kiln-v2` branch on geth)
- [x] Interop with other EL clients (nethermind on `merge-devnet-4`)
- [x] ~Implement `zeroize` for jwt secrets~
- [x] Add auth server tests with `mock_execution_layer`
- [x] Get auth working with the `execution_engine_integration` tests
Co-authored-by: Paul Hauner <paul@paulhauner.com>
## Issue Addressed
#3010
## Proposed Changes
- move log debounce time latch to `./common/logging`
- add timelatch to limit logging for `attestations_delay_queue` and `queued_block_roots`
## Additional Info
- Is a separate crate for the time latch preferred?
- `elapsed()` could take `LOG_DEBOUNCE_INTERVAL ` as an argument to allow for different granularity.
## Issue Addressed
Addresses spec changes from v1.1.0:
- https://github.com/ethereum/consensus-specs/pull/2830
- https://github.com/ethereum/consensus-specs/pull/2846
## Proposed Changes
* Downgrade the REJECT for `HeadBlockFinalized` to an IGNORE. This applies to both unaggregated and aggregated attestations.
## Additional Info
I thought about also changing the penalty for `UnknownTargetRoot` but I don't think it's reachable in practice.
## Issue Addressed
As discussed on last-night's consensus call, the testnets next week will target the [Kiln Spec v2](https://hackmd.io/@n0ble/kiln-spec).
Presently, we support Kiln V1. V2 is backwards compatible, except for renaming `random` to `prev_randao` in:
- https://github.com/ethereum/execution-apis/pull/180
- https://github.com/ethereum/consensus-specs/pull/2835
With this PR we'll no longer be compatible with the existing Kintsugi and Kiln testnets, however we'll be ready for the testnets next week. I raised this breaking change in the call last night, we are all keen to move forward and break things.
We now target the [`merge-kiln-v2`](https://github.com/MariusVanDerWijden/go-ethereum/tree/merge-kiln-v2) branch for interop with Geth. This required adding the `--http.aauthport` to the tester to avoid a port conflict at startup.
### Changes to exec integration tests
There's some change in the `merge-kiln-v2` version of Geth that means it can't compile on a vanilla Github runner. Bumping the `go` version on the runner solved this issue.
Whilst addressing this, I refactored the `testing/execution_integration` crate to be a *binary* rather than a *library* with tests. This means that we don't need to run the `build.rs` and build Geth whenever someone runs `make lint` or `make test-release`. This is nice for everyday users, but it's also nice for CI so that we can have a specific runner for these tests and we don't need to ensure *all* runners support everything required to build all execution clients.
## More Info
- [x] ~~EF tests are failing since the rename has broken some tests that reference the old field name. I have been told there will be new tests released in the coming days (25/02/22 or 26/02/22).~~
## Issue Addressed
#3006
## Proposed Changes
This PR changes the default behaviour of lighthouse to ignore discovered IPs that are not globally routable. It adds a CLI flag, --enable-local-discovery to permit the non-global IPs in discovery.
NOTE: We should take care in merging this as I will break current set-ups that rely on local IP discovery. I made this the non-default behaviour because we dont really want to be wasting resources attempting to connect to non-routable addresses and we dont want to propagate these to others (on the chance we can connect to one of these local nodes), improving discoveries efficiency.
## Description
This PR adds a single, trivial commit (f5d2b27d78) atop #2986 to resolve a tests compile error. The original author (@ethDreamer) is AFK so I'm getting this one merged ☺️
Please see #2986 for more information about the other, significant changes in this PR.
Co-authored-by: Mark Mackey <mark@sigmaprime.io>
Co-authored-by: ethDreamer <37123614+ethDreamer@users.noreply.github.com>
## Issue Addressed
NA
## Proposed Changes
Adds the functionality to allow blocks to be validated/invalidated after their import as per the [optimistic sync spec](https://github.com/ethereum/consensus-specs/blob/dev/sync/optimistic.md#how-to-optimistically-import-blocks). This means:
- Updating `ProtoArray` to allow flipping the `execution_status` of ancestors/descendants based on payload validity updates.
- Creating separation between `execution_layer` and the `beacon_chain` by creating a `PayloadStatus` struct.
- Refactoring how the `execution_layer` selects a `PayloadStatus` from the multiple statuses returned from multiple EEs.
- Adding testing framework for optimistic imports.
- Add `ExecutionBlockHash(Hash256)` new-type struct to avoid confusion between *beacon block roots* and *execution payload hashes*.
- Add `merge` to [`FORKS`](c3a793fd73/Makefile (L17)) in the `Makefile` to ensure we test the beacon chain with merge settings.
- Fix some tests here that were failing due to a missing execution layer.
## TODO
- [ ] Balance tests
Co-authored-by: Mark Mackey <mark@sigmaprime.io>
## Proposed Changes
Lots of lint updates related to `flat_map`, `unwrap_or_else` and string patterns. I did a little more creative refactoring in the op pool, but otherwise followed Clippy's suggestions.
## Additional Info
We need this PR to unblock CI.
## Issue Addressed
Closes#2990
## Proposed Changes
Add a check to see if the `--validators-dir` CLI flag is set and if so store validator logs into it.
Ensure that if the log directory cannot be created, emit a `WARN` and disable file logging rather than panicking.
## Additional Info
Panics associated with logfiles can still occur in these scenarios:
1. The `$datadir/validators/logs` directory already exists with the wrong permissions (or was changed after creation).
1. The logfile already exists with the wrong permissions (or was changed after creation).
> These panics are cosmetic only since only the logfile thread panics. Following the panics, LH will continue to function as normal.
I believe this is due to the use of [`slog::Fuse`](https://docs.rs/slog/latest/slog/struct.Fuse.html) when initializing the logger.
I'm not sure if there a better way of handling logfile errors?
I think ideally, rather than panicking, we would emit a `WARN` to the stdout logger with the panic reason, then exit the logfile thread gracefully.
## Issue Addressed
#3020
## Proposed Changes
- Alias the `validators-dir` arg to `validator-dir` in the `validator_client` subcommand.
- Alias the `validator-dir` arg to `validators-dir` in the `account_manager validator` subcommand.
- Add test for the validator_client alias.
## Issue Addressed
Addresses https://github.com/sigp/lighthouse/issues/2926
## Proposed Changes
Appropriated from https://github.com/sigp/lighthouse/issues/2926#issuecomment-1039676768:
When a node returns *any* error we call [`CandidateBeaconNode::set_offline`](c3a793fd73/validator_client/src/beacon_node_fallback.rs (L424)) which sets it's `status` to `CandidateError::Offline`. That node will then be ignored until the routine [`fallback_updater_service`](c3a793fd73/validator_client/src/beacon_node_fallback.rs (L44)) manages to reconnect to it.
However, I believe there was an issue in the [`CanidateBeaconNode::refesh_status`](c3a793fd73/validator_client/src/beacon_node_fallback.rs (L157-L178)) method, which is used by the updater service to see if the node has come good again. It was holding a [write lock on the `status` field](c3a793fd73/validator_client/src/beacon_node_fallback.rs (L165)) whilst it polled the node status. This means a long timeout would hog the write lock and starve other processes.
When a VC is trying to access a beacon node for whatever purpose (getting duties, posting blocks, etc), it performs [three passes](c3a793fd73/validator_client/src/beacon_node_fallback.rs (L432-L482)) through the lists of nodes, trying to run some generic `function` (closure, lambda, etc) on each node:
- 1st pass: only try running `function` on all nodes which are both synced and online.
- 2nd pass: try running `function` on all nodes that are online, but not necessarily synced.
- 3rd pass: for each offline node, try refreshing its status and then running `function` on it.
So, it turns out that if the `CanidateBeaconNode::refesh_status` function from the routine update service is hogging the write-lock, the 1st pass gets blocked whilst trying to read the status of the first node. So, nodes that should be left until the 3rd pass are blocking the process of the 1st and 2nd passes, hence the behaviour described in #2926.
## Additional Info
NA
## Issue Addressed
Timeouts due to Windows builds running for 2h 20m.
## Proposed Changes
* Increase Bors timeout to 3h
* Refine the target branch check so that it will pass when we make PRs to feature branches. This is just an extra change I've been meaning to sneak in for a while.
## Additional Info
* I think it would also be cool to try caching for CI again, but that's a separate issue and we'll still need the long timeout on a cache miss.
## Issue Addressed
N/A
## Proposed Changes
Add a HTTP API which can be used to compute the block packing data for all blocks over a discrete range of epochs.
## Usage
### Request
```
curl "http:localhost:5052/lighthouse/analysis/block_packing_efficiency?start_epoch=57730&end_epoch=57732"
```
### Response
```
[
{
"slot": "1847360",
"block_hash": "0xa7dc230659802df2f99ea3798faede2e75942bb5735d56e6bfdc2df335dcd61f",
"proposer_info": {
"validator_index": 1686,
"graffiti": ""
},
"available_attestations": 7096,
"included_attestations": 6459,
"prior_skip_slots": 0
},
...
]
```
## Additional Info
This is notably different to the existing lcli code:
- Uses `BlockReplayer` #2863 and as such runs significantly faster than the previous method.
- Corrects the off-by-one #2878
- Removes the `offline` validators component. This was only a "best guess" and simply was used as a way to determine an estimate of the "true" packing efficiency and was generally not helpful in terms of direct comparisons between different packing methods. As such it has been removed from the API and any future estimates of "offline" validators would be better suited in a separate/more targeted API or as part of 'beacon watch': #2873
- Includes `prior_skip_slots`.
## Issue Addressed
Closes#2880
## Proposed Changes
Support requests to the next epoch in proposer_duties api.
## Additional Info
Implemented with skipping proposer cache for this case because the cache for the future epoch will be missed every new slot as dependent_root is changed and we don't want to "wash it out" by saving additional values.
## Issue Addressed
#2953
## Proposed Changes
Adds empty local validator check.
## Additional Info
Two other options:
- add check inside `local_index` collection. Instead of after collection.
- Move `local_index` collection to the beginning of the `poll_sync_committee_duties` function and combine sync committee with altair fork check.
## Issue Addressed
I noticed in some logs some excess and unecessary discovery queries. What was happening was we were pruning our peers down to our outbound target and having some disconnect. When we are below this threshold we try to find more peers (even if we are at our peer limit). The request becomes futile because we have no more peer slots.
This PR corrects this issue and advances the pruning mechanism to favour subnet peers.
An overview the new logic added is:
- We prune peers down to a target outbound peer count which is higher than the minimum outbound peer count.
- We only search for more peers if there is room to do so, and we are below the minimum outbound peer count not the target. So this gives us some buffer for peers to disconnect. The buffer is currently 10%
The modified pruning logic is documented in the code but for reference it should do the following:
- Prune peers with bad scores first
- If we need to prune more peers, then prune peers that are subscribed to a long-lived subnet
- If we still need to prune peers, the prune peers that we have a higher density of on any given subnet which should drive for uniform peers across all subnets.
This will need a bit of testing as it modifies some significant peer management behaviours in lighthouse.
## Issue Addressed
Alternative to #2935
## Proposed Changes
Replace the `Vec<u8>` inside `Bitfield` with a `SmallVec<[u8; 32>`. This eliminates heap allocations for attestation bitfields until we reach 500K validators, at which point we can consider increasing `SMALLVEC_LEN` to 40 or 48.
While running Lighthouse under `heaptrack` I found that SSZ encoding and decoding of bitfields corresponded to 22% of all allocations by count. I've confirmed that with this change applied those allocations disappear entirely.
## Additional Info
We can win another 8 bytes of space by using `smallvec`'s [`union` feature](https://docs.rs/smallvec/1.8.0/smallvec/#union), although I might leave that for a future PR because I don't know how experimental that feature is and whether it uses some spicy `unsafe` blocks.
## Issue Addressed
NA
## Proposed Changes
This PR extends #3018 to address my review comments there and add automated integration tests with Geth (and other implementations, in the future).
I've also de-duplicated the "unused port" logic by creating an `common/unused_port` crate.
## Additional Info
I'm not sure if we want to merge this PR, or update #3018 and merge that. I don't mind, I'm primarily opening this PR to make sure CI works.
Co-authored-by: Mark Mackey <mark@sigmaprime.io>
## Issue Addressed
Closes#3014
## Proposed Changes
- Rename `receipt_root` to `receipts_root`
- Rename `execute_payload` to `notify_new_payload`
- This is slightly weird since we modify everything except the actual HTTP call to the engine API. That change is expected to be implemented in #2985 (cc @ethDreamer)
- Enable "random" tests for Bellatrix.
## Notes
This will break *partially* compatibility with Kintusgi testnets in order to gain compatibility with [Kiln](https://hackmd.io/@n0ble/kiln-spec) testnets. I think it will only break the BN APIs due to the `receipts_root` change, however it might have some other effects too.
Co-authored-by: Michael Sproul <micsproul@gmail.com>
.ok_or_else(||Error::SchemaMigrationError("fork choice missing from database".into()))?;
letv11=downgrade_fork_choice(v17)?;
debug!(
log,
"Adding junk best_justified_checkpoint to fork choice store."
);
Ok(vec![v11.as_kv_store_op(FORK_CHOICE_DB_KEY)])
}
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
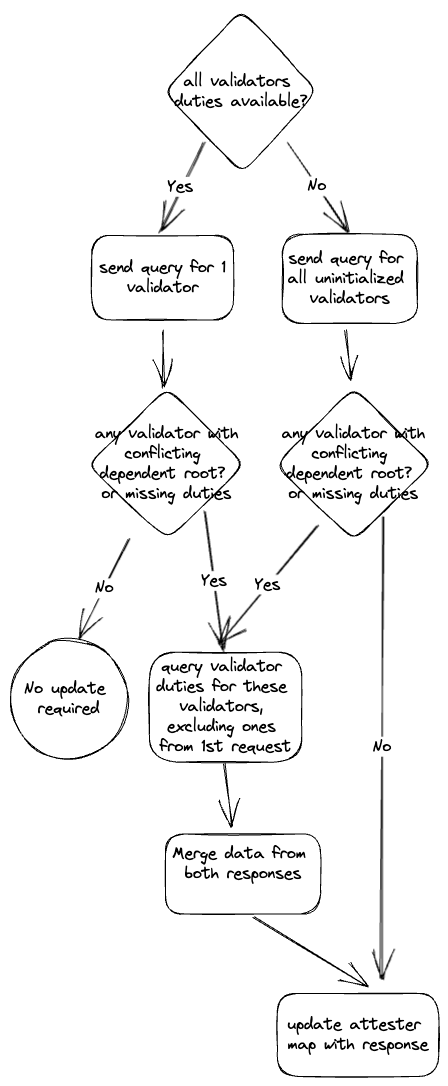{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}